
This is the second article in our short series on lambda calculus. If you are unfamiliar with lambda calculus, we recommend starting with the first article. In this piece, we focus on introducing types to lambda calculus.
We’ve also previously covered the history of formal verification and, by extension, type theory. Reading that article might provide a historical background for the topics we’ll discuss here.
We assume familiarity with the basic lambda calculus syntax, which we covered in the previous article. Additionally, we assume basic understanding of the related concepts, including unrestricted computation, logic systems, paradoxes, Russell’s type theory, and logical consistency.
Typed lambda calculus extends the untyped lambda calculus by introducing a type system. It’s important to note that, unlike untyped lambda calculus, there are multiple typed lambda calculi, each differentiated by the specific features of the type system used. The exact features of the type system can be chosen with considerable flexibility. In this article, we will explore some of the common choices.
The untyped lambda calculus is hard to use as a logic system due to the paradoxes it creates. Adding Russell’s type theory to lambda calculus makes it, under certain conditions, logically consistent, which, in turn, makes it possible to mathematically guarantee certain behaviors (or lack thereof).
The most common argument for the strongly-typed languages is that if a program type checks, it will never segfault (or have any other type-related issues), but I think this argument sells typed languages short. A sufficiently strict and expressive type system allows for encoding much more than simply “not segfaulting.” In some cases, the whole domain can be expressed in types.
In this article, we are primarily focused on the basics, and therefore, we won’t delve deeply into the more expressive type systems such as System FC or those with dependent types.
Simply typed lambda calculus with atomic boolean values
Well-Typed Expressions Do Not Go Wrong
– Robin Milner, “A Theory of Type Polymorphism in Programming”
We will now introduce atomic values to the lambda calculus. While it is feasible to construct a value representation using only λ-abstractions (using Church encoding or otherwise) for almost any value we might be interested in, practically speaking, it’s not very convenient, rather memory-inefficient, and performance of the Church encoding on modern systems isn’t great.
Thus, we introduce atomic values and .
Since we’ve introduced atomic values, we also need to introduce an eliminator (i.e. a consumer) for these values. In this case, let’s consider an operator.
The semantics of this operator should be reasonably familiar to a practicing programmer, but let’s informally write them them out anyway:
- should reduce to
- should reduce to
- where is a redex, should be reduced first.
The introduction of the operator creates a bit of a kink. What do we do if is neither , , nor a redex? E.g.
Such terms are called “stuck” — the computation, according to our rules, can not proceed.
We want to avoid stuck terms!
To do that, we’ll have to place some restrictions on what could be.
Typing relations, rules, and systems
To express such restrictions, we introduce the so-called typing relation. A typing relation is a relation, in this case meaning a set of pairs, which assigns types to syntactically valid terms.
Not all syntactically valid terms can have a type assigned to them. We call terms that have a type well-typed, and the others ill-typed. The point of having a type system is to reject ill-typed terms, as those are the ones likely to get “stuck”.
One such individual assignment we’ll call a typing judgement, and will write it separated by a column: , read as “term has type ”.
Types can be thought of as sets of terms of a certain general form. Turns out (Reynolds, 1984), this naive interpretation of types as sets doesn’t hold to rigorous scrutiny. Still, it’s a good enough mental model unless you’re a type theory researcher (and if you are, hi, very nice of you to read this article, please get in touch if you have corrections).
In most practically relevant cases, specifying the typing relation by direct enumeration is at best impractical, and is usually impossible. We can instead specify it by writing out a finite set of rules, called typing rules, from which the typing relation can be derived. Together, types and typing rules constitute a type system.
Type systems offer a lightweight (i.e. without executing a program) tool to check if a program is “correct” – in a sense that it doesn’t produce stuck terms.
Typing rules are usually written in the form
where is zero or more semicolon-separated typing judgements, and is a single typing judgement.
If there are no premises, i.e. the conclusion is an axiom, the horizontal line is often omitted.
Let us introduce the type which represents a set of and any redexes that eventually evaluate to either.
Now we can write typing rules for our boolean values and as axioms:
And for the operator:
Note that rules are annotated with names. We’ll use these names to reference the rules later.
The first two rules, and are trivial. The third rule, , reads “given that has type , and both and have the same arbitrary type , then has this type ”.
We should note that the typing rule will forbid some “correct” terms, as in “terms that aren’t stuck”. For example, is just , which is arguably perfectly reasonable, but our type system wouldn’t allow it.
This is true in general: any sufficiently strict type system will reject some “correct” terms, but that’s basically a consequence of Gödel’s incompleteness theorems, so either we have to deal with a system that allows for paradoxes (inconsistency), or we have to live with some arguably correct terms being rejected (incompleteness).
In this particular example, it makes sense if you think about it. The example above is trivial enough, but consider you might have Here, it is quite unclear what the type of the whole expression should be without executing the program. That is not to say this is a fundamental restriction, more powerful type systems can lift it, but we won’t discuss them here.
We call a type system sound if it assigns (relates) at most one type to each term.
Typing lambda-abstractions, variables and applications
We have introduced typing rules for boolean values and , but there are other terms in our calculus. Specifically, we also have abstractions, applications, and variables.
Let’s start with abstractions.
A lambda-abstraction is basically a function of a single argument. We could introduce a new simple type and relate all abstractions to this type. Unfortunately, we would soon run into trouble with this approach.
Indeed, imagine a term Both branches would have the type , but their behavior is very different. This example suggests that we need to know both the argument type and the return type of a lambda abstraction.
So instead of a single type, we introduce a family of types where is a type constructor. A type relates to all functions accepting an argument of type and returning the result of type For the sake of simplicity of notation, we assume is right-associative, hence to write the type of an abstraction returning an abstraction, e.g. we don’t need parentheses, i.e. .
To decide on the argument type, we basically have two options:
- We can try to “guess” what type it should be based on context. This is inferred typing. Not always possible, though.
- We can demand that the type is specified explicitly. This is explicit typing.
For now, let’s go with the second option. Hence, we need to introduce an explicit typing notation:
All λ-abstractions must be explicitly typed like this.
If we know the type of the abstraction argument, we can infer the type of the result by substituting the known type of the variable into the typing rules for the abstraction body. Formally, this idea is expressed by introducing a typing context.
A typing context is a set of typing judgements for variables that are “in scope”, i.e. judgements that are locally known but not necessarily globally true. Note that variables are not assumed to be identified by their names here: each variable will have a corresponding distinct typing judgement in the context even if their names are the same.
Practically speaking, typing context can be thought of as a mapping from variables to types and is often implemented as such.
The “current” context is usually denoted by and is written to the left of other typing judgements, separated by (a symbol for logical entailment). We can also extend the context by simply adding new comma-separated typing judgements, e.g. is the context , extended by the judgement
Using all this new syntax, we can define a typing rule for abstractions now:
This rule simply says that if – given the current context plus the type of the abstraction variable – the type of the body turns out to be , then the whole abstraction in the current context has type Pretty straightforward, but the notation may seem a bit arcane. Spend a minute to understand it, we’ll be using it more down the line.
For individual variables, the typing rule would then be rather trivial:
For applications, it’s a bit more involved, but hopefully nothing too surprising:
Try to interpret this one yourself, then check if you’re correct.
This reads, basically, "for an application expression, if the left-hand side (function) has type and the right-hand-side (argument) has the type , then the result of the application will have type Answer
To clear up a technicality, we also need to have the context in our rule, since typings of terms might depend on the context, too:
Example
The practical application of these rules is we can use those to assign types to terms and thus ensure the program doesn’t get stuck.
In actual practice, we’d have some inference algorithm to decide on types of terms (and whether they have one). In this theoretical introduction, we’ll just assume there’s some way to get the type of a given term, without getting into the specifics of how it works.
As a proof that a given term has a given type, we can use typing trees. Typing trees just chain typing rules in a tree-like structure.
As a simple example, let us show that term has type in some arbitrary context .
It may be more natural to read this typing tree bottom-up. We start with the initial premise, i.e. the expression in question has the expected type. This is justified by the rule, where is instantiated (i.e. replaced) with , with , and with . The second premise of the rule, namely that , is trivially true due to . The first premise is true due to the rule, wherein and are instantiated with , and with . The premise of the rule in turn is true due to the rule, as the judgement is trivially an element of the typing context (i.e. an arbitrary context extended by the judgement ).
Actual inference algorithms ultimately constructively build such proofs. However, there isn’t necessarily a single way to build them: a given type system may have multiple inference algorithms. On the other hand, a type system may be sound, but undecidable, in which case it will not have a general inference algorithm at all.
The impossibility of simply typed lambda calculus without atomic values
So, we have a sound type system. However, it does have one pretty obvious drawback.
We will omit the proof of the soundness of the simply typed lambda calculus with atomic booleans, however, it’s easy enough to find for the interested reader, e.g. in (Pierce, 2002). The short sketch is to prove soundness we need to prove two propositions: Both are proven by structural induction on terms, but you’ll also have to formally define the computation semantics, which here we glossed over.On the soundness
In the untyped lambda calculus, we could define
and use it anywhere we would fancy an identity function.
With our new fancy type system, we can not. Obviously, for any concrete type, we could define
But we can’t do it in general.
Notice how we need a terminating type in the type signature. Consequently, if our calculus didn’t have any atomic values, i.e. didn’t have any types beyond abstractions, we wouldn’t be able to specify the argument type.
The reason for this is the lack of polymorphism.
Polymorphic lambda-calculi
Double-barreled names in science may be special for two reasons: some belong to ideas so subtle that they required two collaborators to develop; and some belong to ideas so sublime that they possess two independent discoverers. […] the Hindley-Milner type system and the Girard-Reynolds polymorphic lambda calculus [are the] ideas of the second sort.
– Philip Wadler, “The Girard-Reynolds Isomorphism”
Polymorphism, essentially, is the ability of the type system to deal with terms that can have arbitrary types. Practically speaking, a fully-typed program will not have any terms with polymorphic types, as a polymorphic type is basically a placeholder to be replaced with concrete types during compilation.
But parts of a program, especially during type checking or type inference, might have polymorphic types.
Viewing polymorphic types as placeholders to be replaced is justified in the context of this theoretical introduction, and it gives a useful intuition.
However, in practice, things like dynamic dispatch make it a bit more complicated.On polymorphic types as placeholders
We need to distinguish two different kinds of polymorphism (Strachey, 2000):
- Ad-hoc, which defines a common interface for an arbitrary set of individually specified types, and
- Parametric, which allows using abstract symbols in type signatures, representing arbitrary types, instead of concrete types.
Ad-hoc polymorphism is more common, and is used extensively in popular programming languages like C++, Java, etc, where it’s called “function/method/operator overloading.” Essentially, ad-hoc polymorphism is a way to make a single function (or, more accurately, a single API endpoint) behave differently for different types. For example, summing integers is pretty different from floating-point numbers, but using a single operator for both is convenient.
Parametric polymorphism is a bit different: it allows us to use so-called type variables in the type signature. At the use site, type variables are instantiated to concrete types. The implementation must be the same regardless of the specific instantiation.
Ad-hoc polymorphism is, generally speaking, pretty ad-hoc. It doesn’t have much of a theoretical background to speak of, although there’s an approach to making it less ad-hoc (Wadler, 1989). In contrast, parametric polymorphism does have a strong theoretical foundation.
Hindley-Milner type system
First, let us discuss the so-called rank-1 polymorphism.
We introduce type variables using the universal quantifier, The exact place where the variables are introduced matters.
In particular, rank-1 polymorphism allows the universal quantifier only on the top level of types. Practically, this means that is okay, but is not.
There’s an argument to be made about how is practically rank-1 polymorphic as it is isomorphic to but we’ll gloss over this point here.
Rank-1 polymorphic type system with type inference is first described by Roger Hindley in (Hindley, 1969), and later rediscovered by Robin Milner in (Milner, 1978).
A formal analysis and correctness proof was later performed by Luis Damas in (Damas, 1982).
This type system is called the Damas-Hindley-Milner type system, or more commonly the Hindley-Milner type system. We will call it HM below.
HM (usually with many extensions) is used as a base for many functional languages, including ML (by the way invented by Robin Milner) and Haskell.
I say HM is used as a base for Haskell.
This is on some technical level correct, but I feel a deluge of “um, actually” coming, so I’ll get this out of the way.
For a while, Haskell used a variation of System Fω at the back end, at some point switching to System FC, while on the front end both Haskell98 and Haskell2010 use a variation on HM with type classes and monomorphism restriction.
If we include various GHC extensions, things quickly get very complicated, but at the core, it’s still somewhat similar to HM.On Haskell's type system
Let-polymorphism
HM makes one concession for the sake of type inference. It only allows the so-called let-polymorphism instead of unconstrained parametric polymorphism.
To explain what this means with an example: one would like to have polymorphic type inference for expressions like
but type inference in polymorphic lambda calculus is in general undecidable without explicit type annotations (Wells, 1999).
To work around that, HM stipulates that polymorphic types can only be inferred for let-bindings, e.g. bindings of the form
Obviously, HM has to introduce the let-binding construction into lambda calculus syntax and define its semantics in terms of base lambda calculus. Hopefully, the translation is more or less obvious – let-bindings are semantically equivalent to immediately-applied lambda abstractions. Note, however, that this doesn’t yet allow for recursive definitions.
HM syntax
I will now formally introduce the syntax of expressions, types, and a function acting on type expressions. I’ll use an informal variation of BNF (Backus-Naur form) to define syntax.
The expression syntax is exactly the syntax of lambda calculus plus the let-in construct:
Note that , , are recursive references.
Types are introduced in two parts, the first part being the monotypes and the second – polytypes (also called type schemes, hence the ):
represents type constructors, defined as primitives, and their set is arbitrary in HM, but it must include at least the abstraction type constructor .
Parentheses can be used in value and type expressions to change evaluation order, but we omit these in the syntax definitions for brevity.
Note that type variables are admitted as monotypes, which makes those distinct from monomorphic types that can’t have type variables.
Polytypes also include monotypes, in addition to quantified types.
The quantifier binds the type variables, so in a type expression all of are bound. Type variables that are not bound are called free.
The crucial difference between monotypes and polytypes is the notion of equivalence.
Monotypes are considered equivalent if they are syntactically the same, i.e. have the same terms in the same places. So, for example, a monotype is only equivalent to i.e. itself.
With polytypes, the equivalence is considered up to the renaming of bound variables (assuming no conflicts with free type variables of course). So, for example, is equivalent to
Notice we couldn’t rename to , as that would result in an entirely different polytype – this is the same quirk as with α-equivalence of abstractions in untyped λ-calculus.
We also need a function to define typing rules. collects all free variables from its argument. It is defined as follows:
The function is properly defined on type expressions (i.e. polytypes and consequently monotypes). However, for notational convenience the last equation extends it also to typing contexts.
The principal type
Polymorphism implies that the same term can have more than one type. In fact, it could have infinitely many types, as is the case with
For the type system to be sound, we need to somehow choose the “most best” type out of all possibilities. Thankfully, there is a straightforward way to do so.
The idea is to choose the largest most general type, also called the principal type – that is, the most specific polytype that can still produce any other possible type via bound variable substitution. We denote substitution of a type variable for a monotype in an expression as
If some type can be produced from by substitution, it is said that is more general than written as defines a partial order on types.
Note that the more general type is “smaller” than the less general type. This is a feature of treating types as sets: the more general the type, the fewer possible values it can have. The most general type is usually considered uninhabited (with a few caveats), i.e. it has no values at all.
Formally, this all can be expressed by the following rule (called specialization rule):
where and each of can mention type variables
This rule essentially says that a more general type can be made less general by substitution.
The condition ensures that free variables are not accidentally replaced and are treated as constants.
Typing rules
The complete HM ruleset is as follows:
This is just one possible formulation of the ruleset. Other equivalent formulations exist, but this one is enough for our purposes for now.
Variable, application, and abstraction rules should already look somewhat familiar – indeed, those are almost exactly the same as those in simply typed lambda calculus.
One notable feature is that the variable rule allows variables to have polytypes, while application and abstraction do not. This, together with the let-in rule, enforces the constraint that only let-in bindings are inferred as polymorphic.
The let-in rule is unsurprisingly similar to a combination of application and abstraction rules. In fact, if we do combine them as follows:
we see that the only substantial difference is uses the polytype instead of the monotype for the type of
The last two rules deserve a bit of a closer look.
The instantiation rule says that if a given expression has a general type in context, it can be specialized to a less general type as defined in the previous subsection. This rule ensures we can in fact use in any matching context, e.g.
On the other hand, the generalization rule works kind of in reverse: it adds a universal quantifier to a polytype. The idea here is that an implicit quantification in can be made explicit if the type variable in question does not appear free in the context. The immediate consequence of this rule is that variables that end up free in a typing judgement are implicitly universally quantified.
Instantiation and generalization rules working together allow for essentially moving quantifications to the top level of a type.
Indeed, as polytypes are allowed neither in abstactions nor applications, when a polytype would occur there, instantiation rule would need to be used, replacing bound type variables with fresh free ones. Conversely, whenever a monotype with free variables occurs in a polytype position, generalization rule can be used to quantify them again.
Recursive bindings
In the discussion so far, we glossed over recursive bindings.
The original paper mentions recursion can be implemented using the fixed-point combinator .
Its semantics are pretty much the same as in untyped lambda calculus, and its type is
Note that this combinator can not be defined (or rather, typed) in terms of HM, so it has to be introduced as a built-in primitive.
Then, the syntactical form for recursive bindings can be introduced as syntactic sugar:
Alternatively, an extension to the typing ruleset with the same semantics is possible.
This is all rather straightforward, but it comes at a price. With the introduction of non-terminating terms can be formulated, which otherwise isn’t the case.
For example, the term where is the identity function, is a non-terminating computation.
Additionally, as evidenced above, becomes inhabited. This introduces various logical consistency issues, which are not usually an issue for a general-purpose programming language but are an issue for a theorem prover.
However, without , general recursion is not possible, which makes the calculus strictly less powerful than a Turing machine.
Hence, a choice has to be made either in favor of logical correctness or computational power.
System F
Hindley-Milner type system is nice in that it can infer types, but it is somewhat restrictive due to only supporting let-polymorphism.
One somewhat annoying feature is that, as discussed above, Hindley-Milner can not type the following term:
This comes down to type inference for higher-rank polymorphism being undecidable, but this issue is readily alleviated by explicit type signatures.
System F, independently discovered by Jean-Yves Girard (Girard, 1972) and John Reynolds (Reynolds, 1974), also called polymorphic lambda calculus or second-order lambda calculus, is a generalization of Hindley-Milner type system to arbitrary-rank polymorphism.
System F, unlike Hindley-Milner, formalizes parametric polymorphism explicitly in the calculus itself, introducing value-level lambda-abstractions over types. This essentially makes specialization explicit.
We will sketch the basics of System F here but won’t get into any detail. An interested reader is highly encouraged to look into (Pierce, 2002).
The primary new syntactical form introduced in F is the abstraction over types, denoted with a capital lambda:
Since there is type abstraction, there is also type application, denoted as where is a term and is a type. Square brackets are used to visually disambiguate type applications from term applications and don’t have any special meaning.
Syntax for types is similar to HM, but it’s not split into monotypes and polytypes, meaning universal quantification may appear anywhere in the type, not just on the top level:
Typing rules are that of simply typed lambda calculus with the addition of
(compare with instantiation and generalization rules in HM)
Hence, assuming where the type constructor is assumed to be a primitive for simplicity, the motivating example could be typed as
and its actual implementation would use type applications explicitly, i.e.
Polymorphic lambda calculi, unlike STLC, are powerful enough to admit Church encodings again.
For instance, we could define the pair type as
and producers and eliminators for it as
with their types correspondingly
Of course, it’s still inefficient, so practical applications of this encoding are limited.
Still, it’s nice that we can limit the base calculus to only have the type constructor, and not lose anything in terms of expressive power.On assuming Pair is a primitive
In practical applications (like Haskell with RankNTypes extension), these explicit applications are inferred from type signatures.
In GHC, they can also be made explicit with the TypeApplications extension.
The lambda cube
With System F, we’ve introduced the concept of terms depending on types via the type abstraction.
A natural question that might come from this is, what other kinds of dependencies might we introduce?
Dependence of terms on terms is a given since it’s a feature of untyped lambda calculus. But we can also have dependence of terms upon types, types upon terms, and types upon types.
Essentially, we have three axes, so this whole variant space constitutes, topologically speaking, a cube.
Behold, the lambda cube:
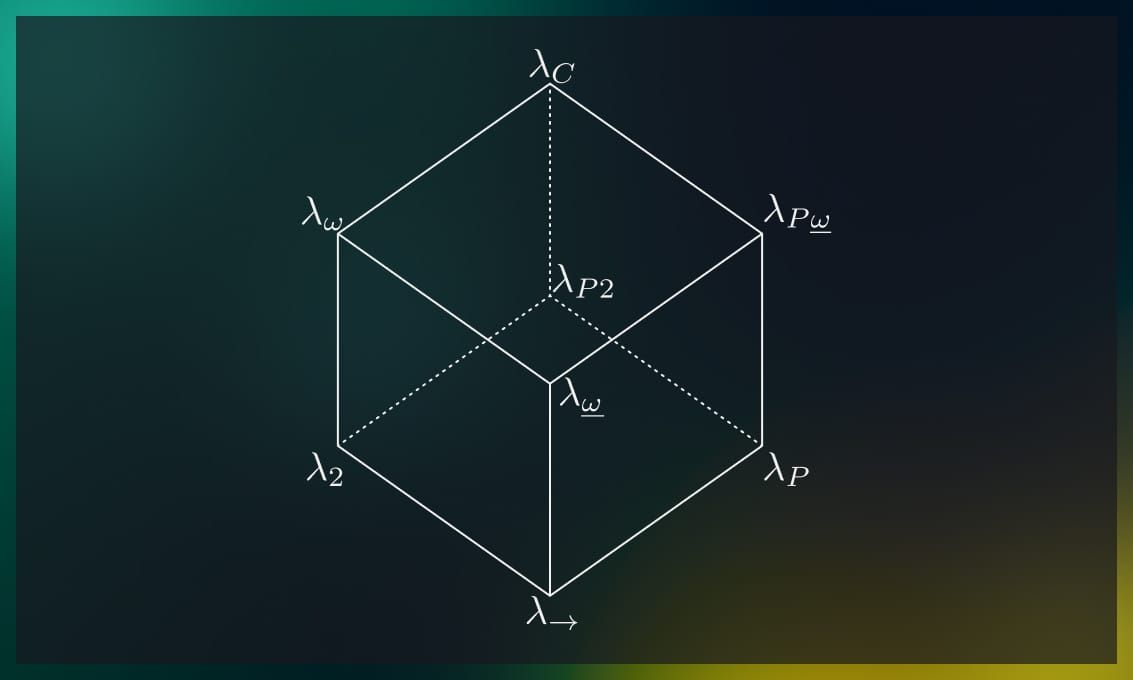
Going directly up in the picture introduces dependence of types upon types, i.e. user-defined type constructors.
Going left introduces dependence of terms upon types, i.e. System F style polymorphism.
Going right introduces dependence of types upon terms, i.e. Martin-Löf style dependent types.
Thus, we have the following variations:
| term ← type | type ← type | type ← term | |
|---|---|---|---|
| × | |||
| × | |||
| × | |||
| × | × | ||
| × | × | ||
| × | × | ||
| × | × | × |
The left arrow ← denotes “depends on”.
The lambda cube was introduced by Henk Barendregt in (Barendregt, 1991) to investigate different generalizations of simply-typed lambda calculus (here denoted as ).
Let us briefly discuss some of the options.
is System F, discussed above.
is System Fω. It extends System F with type operators, which makes it much more complex, but also more expressive. In short, System Fω additionally allows quantification, abstraction and application for type constructors, essentially turning the type level into a simply-typed λ-calculus in its own right.
, a.k.a. System Fω is System Fω without type abstraction/application on the term level. Practicall speaking, this boils down to simply typed lambda calculus with user-defined types.
is simply typed lambda calculus with dependent types.
, a.k.a. is the calculus of constructions (Coquand, 1986), famously used as the base for the Coq proof assistant, but also with other dependently-typed languages. Here, the border between terms and types is virtually gone.
We will not discuss these advanced type systems in any more detail here, but I thought I should at least mention them.
Conclusions
We need to develop our insight into computing processes and to recognise and isolate the central concepts […]. To do this we must become familiar with them and give them names even before we are really satisfied that we have described them precisely.
– Christopher Strachey, “Fundamental Concepts in Programming Languages”
The topic of type theory is rather vast, so it’s infeasible to cover it in a single blog article in any considerable detail.
Hopefully, I’ve introduced enough basics here so that an interested reader can continue exploring this topic on their own, and mentioned enough topics for further reading.
So let’s briefly review what we covered.
- We learned the basic conventions and syntax of the type theory (or at least its modern style), using simply explicitly typed lambda calculus with atomic booleans as a demonstrative example.
- We then discussed the Hindley-Milner type system for rank-1 polymorphic lambda calculus in some detail.
- We also discussed how unbound recursion makes Hindley-Milner-type logics inconsistent.
- Then we briefly discussed System F, which is a generalization of the Hindley-Milner type system.
- System F being one possible extension of simply typed lambda calculus, we also very briefly mentioned other possible extensions, including dependently typed ones, using the model of the lambda cube.
Exercises
-
Using the framework of simply typed lambda calculus with atomic booleans, show (by building typing trees) that given terms have stated types:
-
Using the framework of simply typed lambda calculus with atomic booleans, find some context given which the term has the type Is it possible to describe all such contexts in simply-typed lambda calculus?
-
How would you describe all contexts from exercise 2 in the Hindley-Milner type system?
-
Implement a simply typed lambda calculus type checker and interpreter in your favorite programming language. Likely easier to start from an untyped lambda calculus interpreter, then introduce atomic values and types. See the previous article for hints on implementing the former.
Note the article does not discuss any particular inference algorithms. For simply-typed λ-calculus with explicitly typed abstraction arguments, it’s not really an issue. The type of an expression always immediately follows from the types of its sub-expressions.
Here is a sketch for a function which returns the type of an expression in the definition of STLC given here:
Here, denotes a variable, denote arbitrary sub-expressions, and denote arbitrary types.
The value denotes the result that the term is ill-typed. You should output an error in this case.
Feel free to add more atomic types than just .
References
(Barendregt, 1991) Barendregt, Henk. “Introduction to generalized type systems.” Journal of Functional Programming 1, no. 2 (1991): 125-154.
(Coquand, 1986) Coquand, Thierry, and Gérard Huet. “The calculus of constructions.” PhD diss., INRIA, 1986.
(Damas, 1982) Damas, Luis, and Robin Milner. “Principal type-schemes for functional programs.” In Proceedings of the 9th ACM SIGPLAN-SIGACT symposium on Principles of programming languages, pp. 207-212. 1982.
(Girard, 1972) Girard, Jean-Yves. “Interprétation fonctionnelle et élimination des coupures de l’arithmétique d’ordre supérieur.” PhD diss., Éditeur inconnu, 1972.
(Hindley, 1969) Hindley, Roger. “The principal type-scheme of an object in combinatory logic.” Transactions of the american mathematical society 146 (1969): 29-60.
(Milner, 1978) Milner, Robin. “A theory of type polymorphism in programming.” Journal of computer and system sciences 17.3 (1978): 348-375.
(Pierce, 2002) Pierce, Benjamin C. Types and programming languages. MIT press, 2002.
(Reynolds, 1974) Reynolds, John C. “Towards a theory of type structure.” In Programming Symposium, pp. 408-425. Springer, Berlin, Heidelberg, 1974.
(Reynolds, 1984) Reynolds, John C. “Polymorphism is not set-theoretic.” In International Symposium on Semantics of Data Types, pp. 145-156. Springer, Berlin, Heidelberg, 1984.
(Strachey, 2000) Strachey, Christopher. “Fundamental concepts in programming languages.” Higher-order and symbolic computation 13.1 (2000): 11-49.
(Wadler, 1989) Wadler, Philip, and Stephen Blott. “How to make ad-hoc polymorphism less ad hoc.” In Proceedings of the 16th ACM SIGPLAN-SIGACT symposium on Principles of programming languages, pp. 60-76. 1989.
(Wells, 1999) Wells, Joe B. “Typability and type checking in System F are equivalent and undecidable.” Annals of Pure and Applied Logic 98.1-3 (1999): 111-156



.jpg)
.jpg)

