
Convolutional neural networks are very important in machine learning. If you want to do computer vision or image recognition tasks, you simply can’t go without them. But it can be hard to understand how they work.
As an IT service company, Serokell provides solutions that include work with convolutional neural networks. This post has been written in collaboration with our programmers to help you familiarize yourself with this exciting and promising field. We will talk about the mechanisms behind convolutional neural networks, their benefits, and business use cases.
What is a neural network?
First, let’s brush up our knowledge about how neural networks work in general.
Any neural network, from simple perceptrons to enormous corporate AI-systems, consists of nodes that imitate the neurons in the human brain. These cells are tightly interconnected. So are the nodes.
.png)
Neurons are usually organized into independent layers. One example of neural networks are feed-forward networks. The data moves from the input layer through a set of hidden layers only in one direction like water through filters.
_(1).png)
Every node in the system is connected to some nodes in the previous layer and in the next layer. The node receives information from the layer beneath it, does something with it, and sends information to the next layer.
Every incoming connection is assigned a weight. It’s a number that the node multiples the input by when it receives data from a different node.
_(1).png)
There are usually several incoming values that the node is working with. Then, it sums up everything together.
.png)
There are several possible ways to decide whether the input should be passed to the next layer. For example, if you use the unit step function, the node passes no data to the next layer if its value is below a threshold value. If the number exceeds the threshold value, the node sends the number forward. However, in other cases, the neuron can simply project the input into some fixed value segment.
When a neural net is being trained for the first time, all of its weights and thresholds are assigned at random. Once the training data is fed to the input layer, it goes through all the layers and finally arrives at the output. During training, the weights and thresholds are adjusted until training data with the same labels consistently provides similar outputs. This is called backpropagation. You can see how it works in TensorFlow Playground.
You can read more about neural networks in our introductory deep learning article.
What’s the problem with simple NNs?
Regular artificial neural networks do not scale very well. For example, in CIFAR, a dataset that is commonly used for training computer vision models, the images are only of size 32x32 px and have 3 color channels. That means that a single fully-connected neuron in a first hidden layer of this neural network would have 32x32x3 = 3072 weights. It is still manageable. But now imagine a bigger image, for example, 300x300x3. It would have 270,000 weights (training of which demands so much computational power)!
A huge neural network like that demands a lot of resources but even then remains prone to overfitting because the large number of parameters enable it to just memorize the dataset.
CNNs use parameter sharing. All neurons in a particular feature map share weights which makes the whole system less computationally intense.
How does a Convolutional Neural Network (CNN) work?
A convolutional neural network, or ConvNet, is just a neural network that uses convolution. To understand the principle, we are going to work with a 2-dimensional convolution first.
Why do we use convolution in neural networks?
Convolution is a mathematical operation that allows the merging of two sets of information. In the case of CNN, convolution is applied to the input data to filter the information and produce a feature map.
_(1).png)
This filter is also called a kernel, or feature detector, and its dimensions can be, for example, 3x3. To perform convolution, the kernel goes over the input image, doing matrix multiplication element after element. The result for each receptive field (the area where convolution takes place) is written down in the feature map.
.png)
We continue sliding the filter until the feature map is complete.
Padding and striding
Before we go further, it’s also useful to talk about padding and striding. These techniques are often used in CNNs:
- Padding. Padding expands the input matrix by adding fake pixels to the borders of the matrix. This is done because convolution reduces the size of the matrix. For example, a 5x5 matrix turns into a 3x3 matrix when a filter goes over it.
- Striding. It often happens that when working with a convolutional layer, you need to get an output that is smaller than the input. One way to achieve this is to use a pooling layer. Another way to achieve this is to use striding. The idea behind stride is to skip some areas when the kernel slides over: for example, skipping every 2 or 3 pixels. It reduces spatial resolution and makes the network more computationally efficient.
Padding and striding can help process images more accurately.
For a more detailed explanation of how CNNs work, watch this part of the machine learning course by Brandon Rohrer.
For real-life tasks, convolution is usually performed in 3D. The majority of images have 3 dimensions: height, width and depth, where depth corresponds to color channels (RGB). So the convolutional filter needs to be 3-dimensional as well. Here is how the same operation looks in 3D.
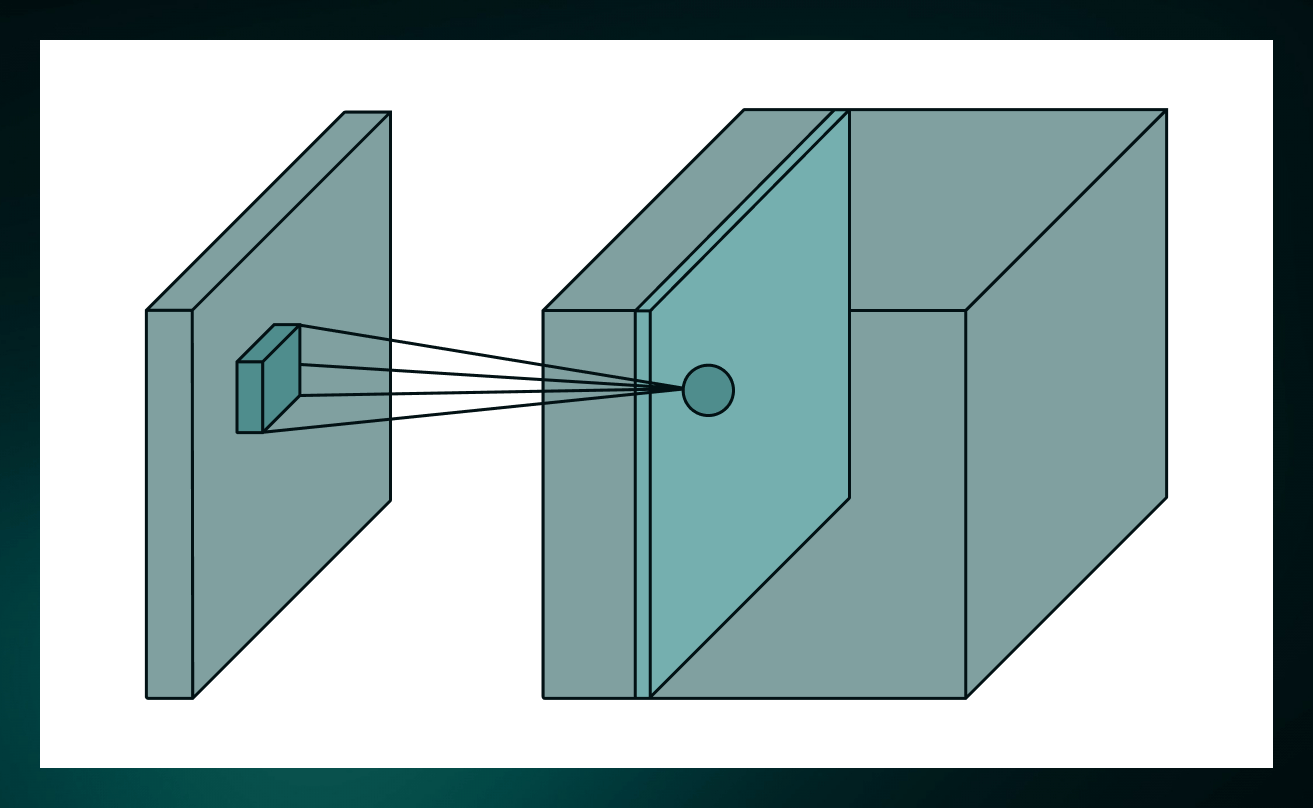
There are multiple filters in a convolutional layer and each of them generates a filter map. Therefore, the output of a layer will be a set of filter maps, stacked on top of each other.
For example, padding and passing a 30x30x3 matrix through 10 filters will result in a set of 10 30x30x1 matrices. After we stack these maps on top of each other, we will get a 30x30x10 matrix.
This is the output of our convolutional layer.
The process can be repeated: CNNs usually have more than one convolutional layer.
3 layers of CNN
The goal of CNN is to reduce the images so that it would be easier to process without losing features that are valuable for accurate prediction.
ConvNet architecture has three kinds of layers: convolutional layer, pooling layer, and fully-connected layer.
- A convolutional layer is responsible for recognizing features in pixels.
- A pooling layer is responsible for making these features more abstract.
- A fully-connected layer is responsible for using the acquired features for prediction.
.png)
Convolutional layer
We’ve already described how convolution layers work above. They are at the center of CNNs, enabling them to autonomously recognize features in the images.
But going through the convolution process generates a large amount of data, which makes it hard to train the neural network. To compress the data, we need to go through pooling.
Pooling layer
A pooling layer receives the result from a convolutional layer and compresses it. The filter of a pooling layer is always smaller than a feature map. Usually, it takes a 2x2 square (patch) and compresses it into one value.
A 2x2 filter would reduce the number of pixels in each feature map to one quarter the size. If you had a feature map sized 10×10, the output map would be 5×5.
Multiple different functions can be used for pooling. These are the most frequent:
- Maximum Pooling. It calculates the maximum value for each patch of the feature map.
- Average pooling. It calculates the average value for each patch on the feature map.
After using the pooling layer, you get pooled feature maps that are a summarized version of the features detected in the input. Pooling layer improves the stability of CNN: if before even slightest fluctuations in pixels would cause the model to misclassify, now small changes in the location of the feature in the input detected by the convolutional layer will result in a pooled feature map with the feature in the same location.
Now we need to flatten the input (turn it into a column vector) and pass it down to a regular neural network for classification.
Fully-connected layer
The flattened output is fed to a feed-forward neural network and backpropagation is applied at every iteration of training. This layer provides the model with the ability to finally understand images: there is a flow of information between each input pixel and each output class.
Advantages of convolutional neural networks
Convolutional neural networks have several benefits that make them useful for many different applications. If you want to see them in practice, watch this thorough explanation by StatQuest.
Feature learning
CNNs don’t require manual feature engineering: they can grasp relevant features during training. Even if you’re working at a completely new task, you can use the pre-trained CNN and, by feeding it data, adjust the weights. CNN will tailor itself to a new task.
Computational efficiency
CNN, due to the procedure of convolution, are much more computationally efficient than regular neural networks. CNN uses parameter sharing and dimensionality reduction, which makes models easy and quick to deploy. They can be optimised to run on any device, even on smartphones.
High accuracy
The current state-of-the-art NNs in image classification are not convolutional nets, for example, in image transformers. However, CNNs have now been dominating for a very long time in most cases and tasks regarding image and video recognition and similar tasks. They usually show higher accuracy than non-convolutional NNs, especially when there is a lot of data involved.
Drawbacks of ConvNet
However, ConvNet is not perfect. Even if it seems like a very intelligent tool, it’s still prone to adversarial attacks.
Adversarial attacks
Adversarial attacks are cases of feeding the network ‘bad’ examples (aka slightly modified in a particular way images) to cause misclassification. Even a slight shift in pixels can make a CNN go crazy. For example, criminals can fool a CNN-based face recognition system and pass unrecognized in front of the camera.
.png)
Data-intensive training
For CNNs to showcase their magical power, they demand tons of training data. This data is not easy to collect and pre-process which can be an obstacle to the wider adoption of the technology. That is why even today there are only a few good pre-trained models such as GoogleNet, VGG, Inception, AlexNet. The majority are owned by global corporations.
What are convolutional neural networks used for?
Convolutional neural networks are used across many industries. Here are some common examples of their use for real-life applications.
Image classification
Convolutional neural networks are often used for image classification. By recognizing valuable features, CNN can identify different objects on images. This ability makes them useful in medicine, for example, for MRI diagnostics. CNN can be also used in agriculture. The networks receive images from satellites like LSAT and can use this information to classify lands based on their level of cultivation. Consequently, this data can be used for making predictions about the fertility level of the grounds or developing a strategy for the optimal use of farmland. Hand-written digits recognition is also one of the earliest uses of CNN for computer vision.
.png)
Object detection
Self-driving cars, AI-powered surveillance systems, and smart homes often use CNN to be able to identify and mark objects. CNN can identify objects on the photos and in real-time, classify, and label them. This is how an automated vehicle finds its way around other cars and pedestrians and smart homes recognize the owner’s face among all others.
.png)
Audio visual matching
YouTube, Netflix, and other video streaming services use audio visual matching to improve their platforms. Sometimes the user’s requests can be very specific, for example, ‘movies about zombies in space’, but the search engine should satisfy even such exotic requests.
Object reconstruction
You can use CNN for 3D modelling of real objects in the digital space. Today there are CNN models that create 3D face models based on just one image. Similar technologies can be used for creating digital twins, which are useful in architecture, biotech, and manufacturing.
Speech recognition
Even though CNNs are often used to work with images, it is not the only possible use for them. ConvNet can help with speech recognition and natural language processing. For example, Facebook’s speech recognition technology is based on convolutional neural networks.
Summing up
To sum up, convolutional neural networks are an awesome tool for computer vision and similar areas because of their ability to recognize features in raw data.
They can recognize the connections between different pixels in training data and use this information to engineer features on their own, building up from low-level (edges, circles) to high-level (faces, hands, cars).
The problem is the features can become rather incomprehensible to humans. Moreover, a wild pixel in the image can sometimes lead to new surprising results.
If this article interested you and you would like to learn more about neural networks, deep learning, and artificial intelligence, you can continue reading about machine learning on our blog.






