
Software developers increasingly adopt the microservices architecture, a server-side solution where interconnected services function autonomously. This enables distinct teams to work on separate services without interrupting the overall workflow—a level of flexibility rarely seen in alternative architectural approaches. Additionally, the next generation approach—multi-runtime architecture—is gaining more attention.
In this blog post, we explain both concepts, as well as their benefits and limitations compared to the monolithic architecture.
What are microservices?
Microservices are a method in software development where the application is built as a collection of small, autonomous services, each with their own specific functionality and communicating via clearly defined APIs. This approach simplifies the scaling of applications and speeds up the development process.
The microservices architecture emerged as a response to the limitations of traditional monolithic architectures, which are less flexible and scalable, and often unable to meet many modern requirements. In monolithic architectures, various processes are closely interlinked and operate as one unified system. Consequently, when a particular process within the application faces a surge in demand, it necessitates scaling the whole architecture. As the application evolves and its code base expands, introducing new features or making enhancements to a monolithic application becomes increasingly complicated. Additionally, monolithic architectures carry a higher risk to the overall application availability. The reason for this is the interdependency and close coupling of processes, which means that the malfunctioning of a single process can have a more pronounced and widespread impact.
Watch this video to learn how Netflix leverages microservices.
What are the key features of the microservices architecture?
Now, let’s look in more detail at the characteristics of the microservices architecture.
Modularity
At the heart of microservices architecture is the principle of modularity. It involves decomposing a software application into smaller, independent modules that are responsible for specific tasks or functions. Each module, often referred to as a service, operates autonomously and communicates with other services via APIs. The modular structure enhances flexibility, as developers can update or scale individual services without impacting the entire system.
Decentralization
Microservices are decentralized in both data management and governance. Unlike monolithic architectures where data is centrally stored and managed, each microservice can have its own logic, allowing for more resilient and adaptable data management. Decentralized governance means teams can independently manage the respective services, leading to faster development cycles and reduced coordination overhead.
Scalability
One of the significant advantages of microservices is scalability. Since services are independent, they can be scaled horizontally (adding more instances of the same service) depending on the demand. This is crucial for handling varying loads and ensuring that the application can manage increased load without performance degradation.
Independent deployment
Microservices architecture allows for independent deployment of services. This means that updates, bug fixes, or new features can be introduced for a specific service without having to redeploy the entire application. This enables a simplified continuous deployment process, reducing the risk and cost of deployment.
What does the microservices architecture consist of?
Alongside services, the microservices architecture includes APIs, containers, Service-Oriented Architecture (SOA) elements, and cloud-based resources.
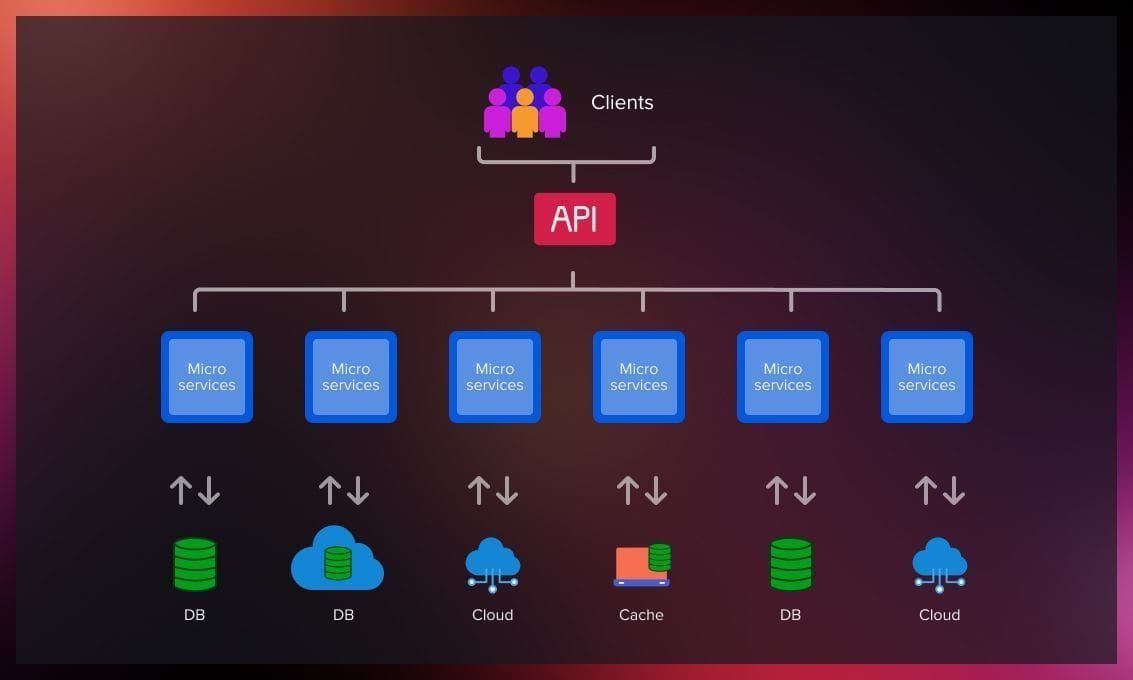
APIs
An API (Application Programming Interface) is a crucial yet separate element of microservices. It acts as the glue that binds various services, allowing for the exchange of requests and responses, which collectively drive the application’s functionality. Central to this setup is an API gateway, which orchestrates the flow of API calls between internal services and external clients, while also managing security, monitoring, and load balancing. By offloading these responsibilities, microservices remain agile and efficient.
Containers
Containers are standalone, executable units of software, complete with all necessary items to operate independently. They are isolated from other software components, allowing multiple containers to coexist in the same environment. In microservices, each service is usually encapsulated within its own container, residing on the same or related servers.
Containers utilize a shared operating system kernel, which enables a higher density on servers compared to traditional virtual machines (VMs). Containers also have rapid deployment and decommissioning capabilities.
While not mandatory for microservices, containers greatly facilitate their practical implementation, as their small footprint and resource efficiency match the small codebases of microservices. Advanced container orchestration tools like Kubernetes further enhance this environment by automatically managing container lifecycle, including the restarting of failed containers with little to no human intervention.
In contrast, a typical virtual machine encompasses a full operating system, drivers, and other components. Although it’s possible to deploy a microservice within a VM for added isolation, this approach can lead to poorer performance and increased maintenance costs.
Service-Oriented Architecture (SOA)
Microservices and Service-Oriented Architecture (SOA) have some common traits, but they represent different concepts. SOA is a development strategy focused on integrating reusable software components or services through a common interface. This interface allows services to work together via an enterprise service bus with minimal knowledge of the inner workings of each service. SOA components typically use Extensible Markup Language (XML) and Simple Object Access Protocol (SOAP) for communication.
SOA is particularly effective for transactional and reusable services within large software systems. However, it is less adaptable for new or refactored code, or in scenarios requiring rapid continuous development and deployment cycles. This is where microservices come in.
Microservices can be seen as an advancement of SOA principles. The main distinction lies in the scope: SOA is designed for broad enterprise-level operations, whereas microservices focus specifically on the application level. In certain cases, SOA can enhance microservices by facilitating interoperability between applications and reusable services across an enterprise IT system.
Cloud computing
Containers and microservices can be deployed in any data center or colocation facility, but they are especially effective in infrastructures designed to manage extensive, integrated services and support rapid or unpredictable scaling. Public cloud environments are particularly suitable for microservices, offering scalable, on-demand computing resources. They also provide essential tools for microservices architectures, such as orchestration engines, API gateways, and flexible pay-as-you-go licensing models. These components are integral in creating and sustaining a robust microservices infrastructure.
How to migrate from monolith to microservices?
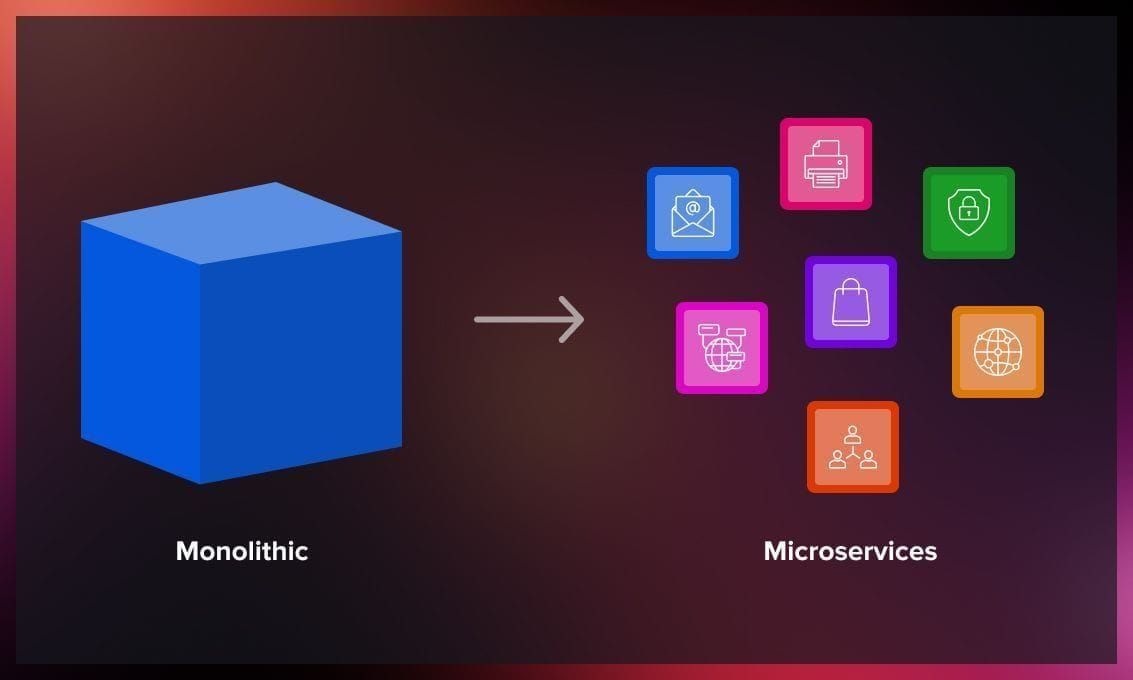
Migration from the monolithic architecture to microservices involves the following steps.
Step 1. Assessing the current infrastructure
Before migrating to microservices, you have to assess various aspects of your current setup:
- Core business goals: Identify what you aim to achieve with microservices, for example, faster development, better uptime, innovation, or scalability.
- Service-Level Agreements (SLAs): Ensure SLAs are in line with your deployment infrastructure and understand the SLAs of potential cloud providers, especially for serverless hosting.
- Infrastructure: Given microservices’ loosely-coupled nature, assess your tools and methods for service deployment and recovery strategies for failed deployments.
- DevOps: Your teams should be well-versed in DevOps practices and equipped with the right technology to enhance agility in a microservices environment.
- Security: Microservices require robust cybersecurity. Review your measures for authorization, authentication, API gateways, communication protocols, network security, and firewalls.
Step 2. Selecting services for migration
It’s important to determine which components should be migrated first. Begin with edge services, which are defined contexts with fewer dependencies and are typically easier to break down into smaller services. Examples of such services include order management, invoicing, or notification systems.
Additionally, consider transitioning from a monolithic architecture to microservices to resolve issues, such as performance bottlenecks.
Step 3. Managing data
A fundamental tenet of microservices architecture is that each microservice should possess its own exclusive database. However, fragmenting a monolithic database can be challenging due to potential overlaps and dependencies among database elements.
Data management in a microservices environment can be organized based on specific data-related patterns:
- Database-Per-Service
In microservice architectures, the Database-Per-Service pattern plays a crucial role: by allocating a unique database to each microservice, it ensures data isolation and consistency while minimizing service interference.
However, this approach complicates data integration and queries across services, necessitating efficient communication protocols and clearly defined interfaces. Careful management of database schema changes is essential to prevent disruption in services. With appropriate strategies, this pattern significantly boosts scalability and fault tolerance in microservices systems.
- Saga
The Saga pattern is necessary for ensuring data consistency in microservice transactions across distributed systems. Rather than performing traditional database transactions, it segments operations into individual, reversible actions. If any part of the process fails, compensating actions are initiated to maintain consistency. This decentralized method enhances resilience and scalability but requires thorough orchestration and failure handling.
- Command Query Responsibility Segregation (CQRS)
CQRS tackles simultaneous data updates and queries within a service. It separates the functions of writing (commands) and reading (queries), enabling services to focus and scale based on their main tasks. Despite its benefits, CQRS also adds complexity, particularly in keeping data consistent across services. Before implementing it, you should carefully consider the pros and cons in light of the specific requirements of the system.
- Event sourcing
Event sourcing captures and stores all state changes in an application as a sequence of events, rather than just the current state. This approach allows a system to rebuild its state by replaying these events.
In microservices, this means each service can independently track its history, fostering independence and decoupling. Events act as a comprehensive record, useful for various purposes including analytics and auditing. While this method aids in error recovery and handling, it requires careful planning for event versioning and storage scalability.
- API composition
API composition is responsible for retrieving data from multiple services. In scenarios where each microservice manages distinct data, direct client-side querying can be cumbersome. This pattern utilizes an intermediary, such as an API composer or aggregator, to consolidate data from various services into a cohesive response. This simplifies client queries and improves data delivery efficiency.
- Shared Database
The Shared Database anti-pattern is used when multiple microservices directly access a common database, bypassing APIs or messaging systems. This approach compromises the autonomy of individual services and poses risks to data integrity. Additionally, this design can create security vulnerabilities and complicate the evolution of the system, turning minor database changes into extensive, coordinated tasks.
Step 4. Optimizing interservice communication
When planning communication between services, it’s essential to consider how interactions are structured:
- Direct service-to-service communication: This involves a one-to-one interaction where a single service processes each client request.
- Collaborative service processing: Here, one-to-many interactions occur, with multiple services collaboratively processing each request.
Additionally, the communication can be either synchronous or asynchronous:
- Synchronous: This involves direct, real-time interaction between client and service, where the client waits for an immediate response, potentially leading to temporary blocking.
- Asynchronous: In this model, the client doesn’t wait for an immediate response. Communication might involve a message broker, where a service posts a message that other services subscribe to and process at their convenience.
Whenever possible, opting for asynchronous communication from a business logic perspective is advisable, as it enhances system stability and facilitates better load balancing.
Step 5: Testing and deploying
Testing in a microservice architecture differs from traditional monolithic systems. While in monoliths the entire application is tested as one unit, a microservices-based application requires several testing methods. These include:
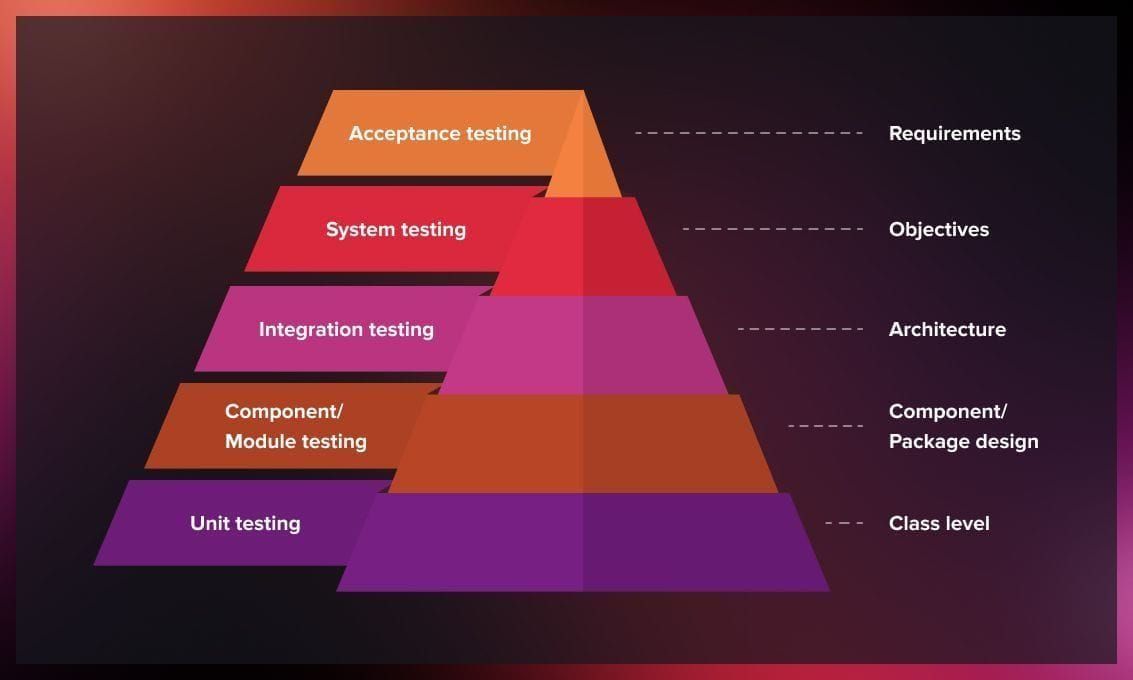
- Unit testing: Focuses on the functionality of individual services (units).
- Component testing: Tests larger-components or modules.
- Integration testing: Ensures interaction between different services.
- Performance testing: Evaluates the responsiveness and stability of the system under various conditions.
- Contract testing: Assesses interactions between the user and the service.
- End-to-end testing: Examines the overall performance of the entire application.
Each type of testing verifies that microservices operate effectively both independently and in collaboration. However, testing microservices comes with challenges. For example, a malfunction in one service can cause problems in others, complicating the identification of the original issue. The variety of communication channels and protocols used demands specialized knowledge. Additionally, the requirement to test numerous endpoints and conduct automated testing calls for skills in scriptwriting and proficiency with automation tools.
What are the limitations of microservices?
The deployment process for microservices, as compared to the monolithic architecture, can be more complex and may involve several challenges, such as:
-
Management of component dependencies is more difficult.
-
It’s harder to monitor the overall performance of the application.
-
Debugging processes are more intricate.
-
Integration testing is more complicated, necessitating the testing of each API in the sequence and overall system performance.
-
Maintaining high availability across numerous services entails higher costs.
Now, let’s look deeper into the reasons for these limitations.
Microservices separate different business areas by using specific contexts for each. However, this approach does not completely solve the problem of detaching business logic from middleware. When middleware is integrated directly into microservices as a library, you need tight coupling. As we move towards more distributed technologies, strengthening the connections between microservices and integration platforms becomes more and more important. Nonetheless, managing the state across various microservices remains a significant challenge.
Alternatively, a traditional, unified middleware solution, such as an enterprise service bus, provides the necessary technical features. However, this approach lacks the flexibility and speed required to keep up with the evolving demands of the modern business landscape.
This is why many microservices-based architectures commonly rely on containers and Kubernetes. This challenge can be addressed through a multi-runtime applications architecture, also known as Mecha architecture. It enables programmers to transfer traditional middleware functions onto a platform equipped with a pre-configured secondary runtime.
Watch this video to learn more about pros and cons of microservices:
What is the multi-runtime microservices architecture?
Microservices are well-suited for standard tasks at certain levels. But for projects that are more complex, multifunctional, and varied, the multi-runtime microservices architecture is a better choice.
Multi-runtime microservices (Mecha) are a microservices architecture where different microservices are developed and run using different runtime environments. Multi-runtime microservices allow each service to choose its own technology stack and runtime environment, offering greater flexibility but also adding complexity in terms of system integration and management.
In Mecha, there’s a clear distinction between micrologic, which is solely for business tasks, and the broader scope of microservices. A microservice in this context is a combination of self-contained micrologic and Mecha components, each contributing to the overall service functionality.
Multi-runtime microservices provide ready-to-use basic units and are compatible with open protocols and formats. Mecha supports declarative configurations in formats, such as YAML and JSON, enabling detailed specification of features and connections to micrologic endpoints. It also accommodates integration with advanced API specifications and complex, stateful workflows.
While Mecha architecture is still in a conceptual phase, it holds promise for simplifying technological deployments. It eliminates the need for multiple, specialized agents by centralizing functions like storage, message persistence, and caching, which are supported by either cloud-based or local services.
What are the limitations of the multi-runtime microservices architecture?
Multi-runtime services architectures come with several limitations. They don’t necessarily outweigh the benefits, especially for large-scale, distributed systems that require flexibility. However, they do represent challenges that must be addressed during design and implementation.
- Complexity: Managing and coordinating across different runtimes can significantly increase the system’s complexity. This complexity arises from the need to handle different languages, frameworks, and runtime environments, which can make development, testing, and maintenance more challenging.
- Interoperability issues: Different runtimes may have varied communication mechanisms and data formats. Ensuring seamless interoperability between these can be challenging, often requiring additional layers of translation or adaptation.
- Performance overhead: Communication between different runtimes might involve network calls, serialization, and deserialization of data, which can introduce latency and reduce overall system performance.
- Consistency and transaction management: Achieving data consistency across multiple runtimes can be difficult, especially in distributed transactions. This might require complex coordination and consensus protocols.
- Scalability and resource management: Scaling a multi-runtime system involves not just scaling individual components but also ensuring that the inter-runtime communication scales effectively. Additionally, resource management can be more complex due to the varied requirements of different runtimes.
Conclusion
Microservices have significantly transformed the landscape of software development. As an innovative alternative to the traditional monolithic architectural model, which has been prevalent in software development for many years, microservices offer programmers a more efficient method to develop, monitor, manage, deploy, and scale various applications through cloud technology.






