
.png)
Word2Vec, short for “word to vector,” is a technology used to represent the relationships between different words in the form of a graph. This technology is widely used in machine learning for embedding and text analysis.
Google introduced Word2Vec for their search engine and patented the algorithm, along with several following updates, in 2013. This collection of interconnected algorithms was developed by Tomas Mikolov.
In this article, we will explore the notion and mechanics of generating embeddings with Word2Vec.
What is a word embedding?
If you ask someone which word is more similar to “king” – “ruler” or “worker” – most people would say “ruler” makes more sense, right? But how do we teach this intuition to a computer? That’s where word embeddings come in handy.
A word embedding is a representation of a word used in text analysis. It usually takes the form of a vector, which encodes the word’s meaning in such a way that words closer in the vector space are expected to be similar in meaning. Language modeling and feature learning techniques are typically used to obtain word embeddings, where words or phrases from the vocabulary are mapped to vectors of real numbers.
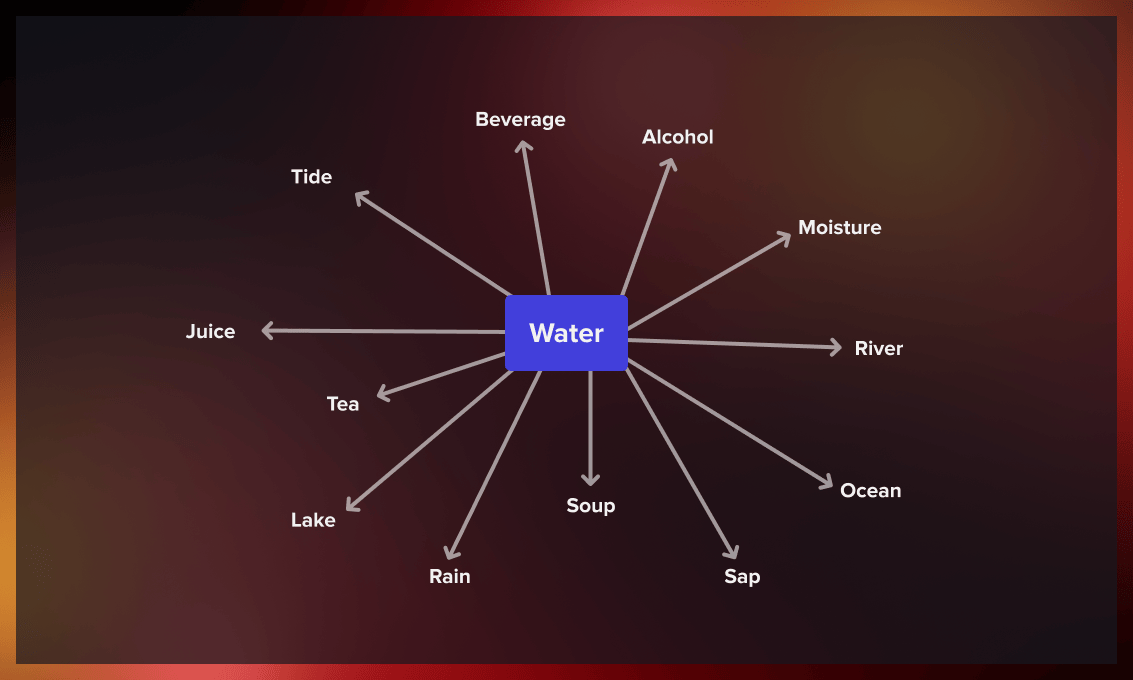
The meaning of a term is determined by its context: the words that come before and after it, which is called the context window. Typically, this window is four words wide, with four words to the left and right of the target term. To create vector representations of words, we look at how often they appear together.
Word embeddings are one of the most fascinating concepts in machine learning. If you’ve ever used virtual assistants like Siri, Google Assistant, or Alexa, or even a smartphone keyboard with predictive text, you’ve already interacted with a natural language processing model based on embeddings.
What’s the difference between word representation, word vectors, and word embeddings?
Word meanings and relations between them can be established through semantics analysis. For this, we need to convert unstructured text data into a structured format suitable for comparison. This process is commonly referred to as word representation.
Word representations are visualizations that can be depicted as independent units (e.g. dots) or by vectors that measure the similarity between words in multidimensional space. However, using individual dots to investigate multiparametric correlations would be nearly impossible, as it would require us to recognize the grammatical meaning and essence of words, identify relationships between homonyms and synonyms, grammatical structures and the position of words within sentences via multiple combinations of dots.
Word vectors are multidimensional numerical representations where words with similar meanings are mapped to nearby vectors in space. And terms used in similar contexts are assigned vectors close to each other. For example, “cat,” “dog,” and “rabbit” should have similar vectors because they all belong to the category of animals. In contrast, “car” and “laptop” should have vectors that are far apart from them because they have no direct semantic relationship.
Word embedding is a technique for representing words with low-dimensional vectors, which makes it easier to understand similarity between them. This approach is particularly helpful as it allows for effective vector analysis to evaluate relationships between words.
What are word embeddings used for?
Word embeddings find their application in feature generation, document clustering, text classification, and various natural language processing tasks:
- Suggesting similar, dissimilar, and most common terms for a given word in a prediction model.
- Semantic grouping of things/objects of similar characteristics and distinguishing them from other categories.
- Dividing positive and negative reviews, clustering queries by topic.
- Natural language processing tasks: parts-of-speech tagging, sentimental analysis, and syntactic analysis.
Watch this video to learn about experimental creative writing with vectorized words:
What is Word2Vec?
Word2Vec (word to vector) is a technique used to convert words to vectors, thereby capturing their meaning, semantic similarity, and relationship with surrounding text. This method helps computers learn the context and connotation of expressions and keywords from large text collections such as news articles and books.
The basic idea behind Word2Vec is to represent each word as a multi-dimensional vector, where the position of the vector in that high-dimensional space captures the meaning of the word.
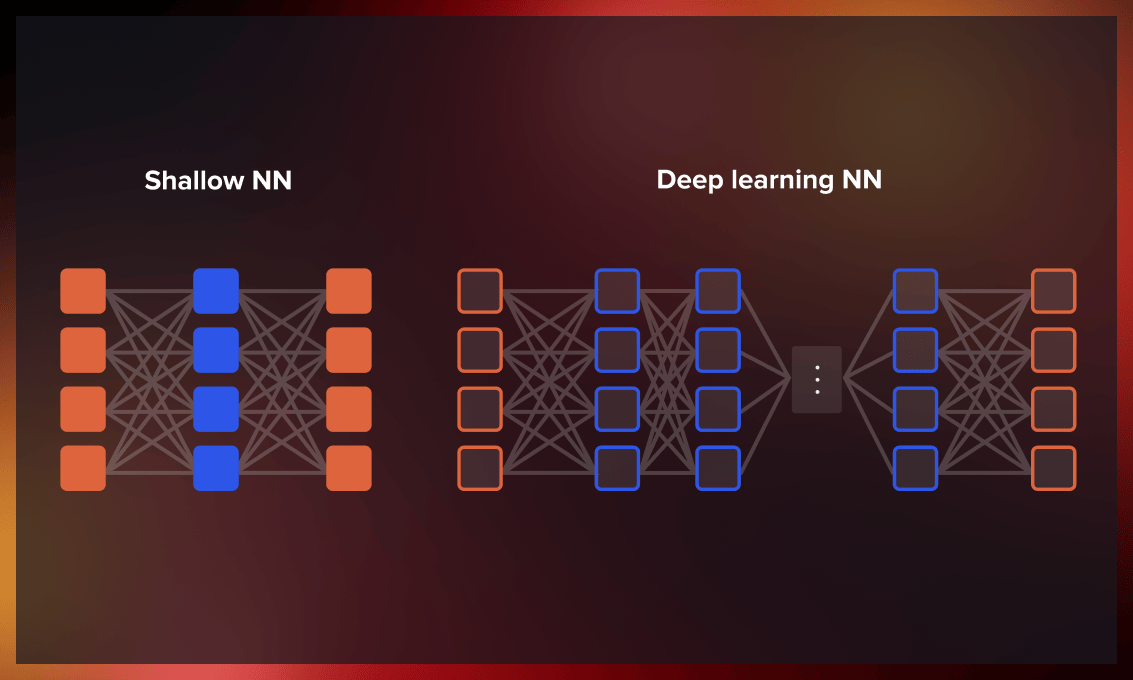
Word2Vec is an algorithm that uses a shallow neural network model to learn the meaning of words from a large corpus of texts. Unlike deep neural networks (DNNs), which have multiple hidden layers, shallow neural networks only have one or two hidden layers between the input and output. This makes the processing prompt and transparent. The shallow neural network of Word2Vec can quickly recognize semantic similarities and identify synonymous words using logistic regression methods, making it faster than DNNs.
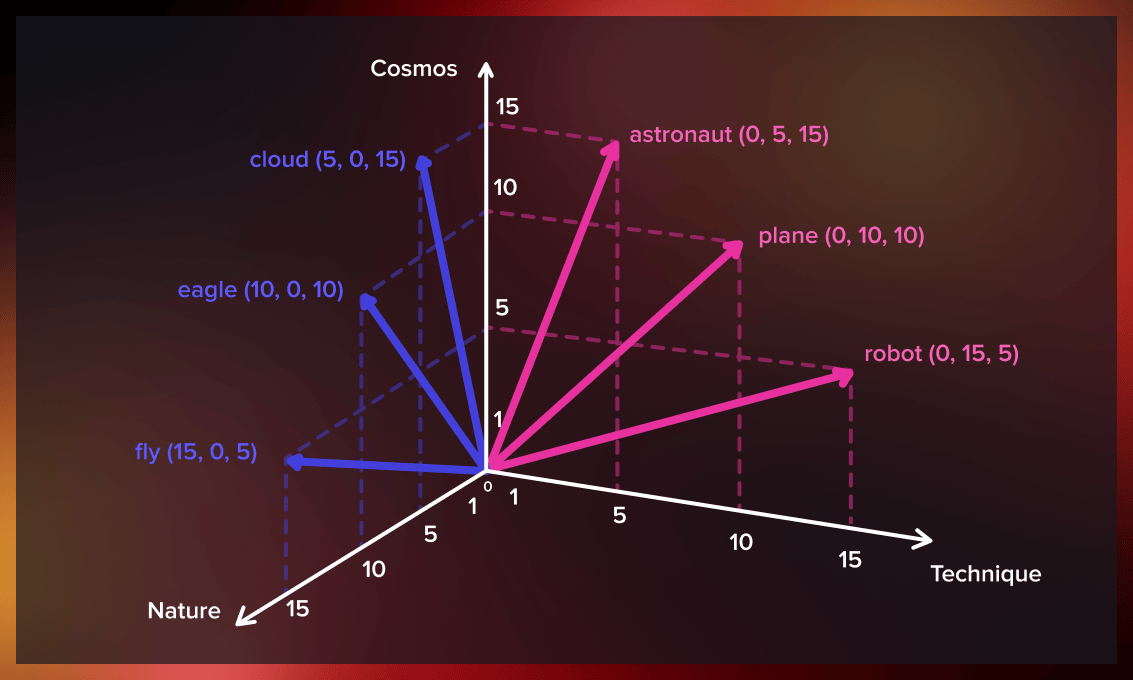
Word2Vec takes a large corpus of text as input and generates a vector space with hundreds of dimensions. Each unique word in the corpus is assigned a vector in this space.
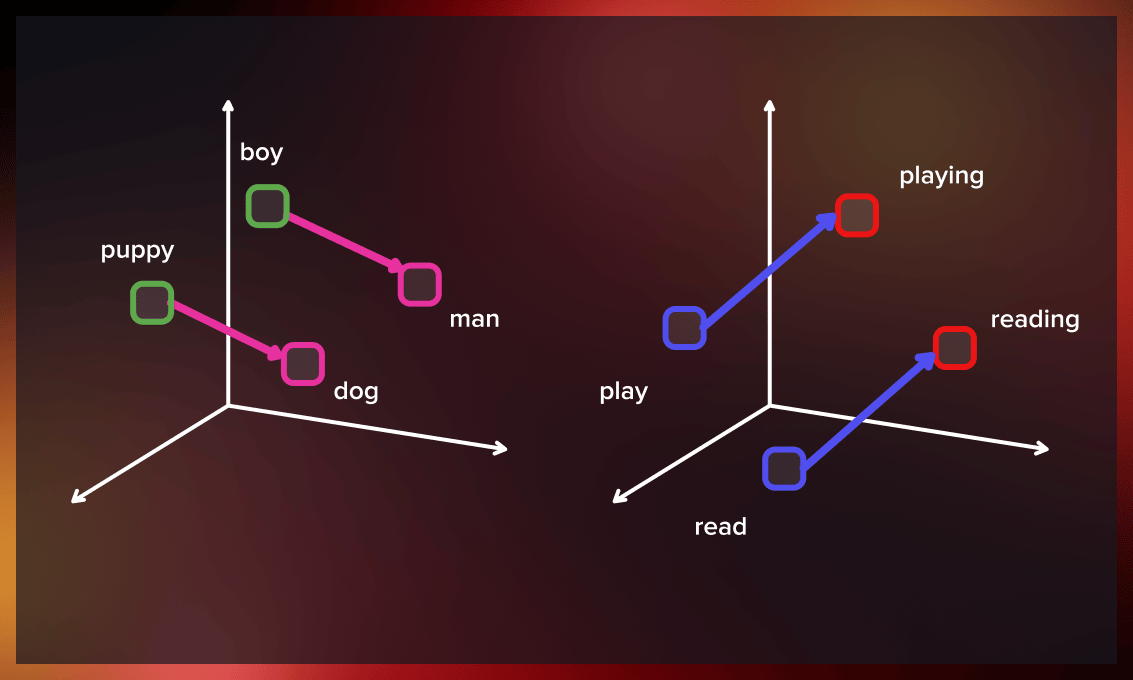
The development of word to vector also involved analyzing the learned vectors and exploring how they can be manipulated using vector analysis. For instance, subtracting the “man-ness” from “King” and adding “women-ness” would result in the word “Queen,” which captures the analogy of “king is to queen as man is to woman.”
How is Word2Vec trained?
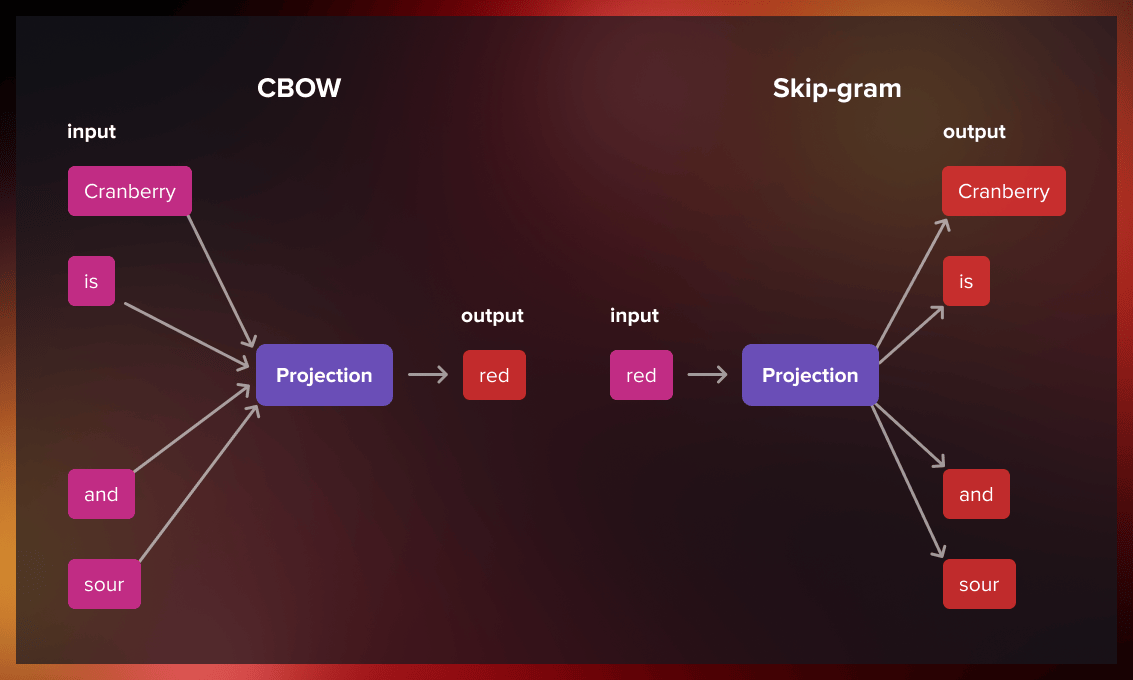
Word to vector is trained using a neural network that learns the relationships between words in large databases of texts. To represent a particular word as a vector in multidimensional space, the algorithm uses one of the two modes: continuous bag of words (CBOW) or skip-gram.
Continuous bag-of-words (CBOW)
The continuous bag-of-words model predicts the central word using the surrounding context words, which comprises a few words before and after the current word.

Skip-gram
The skip-gram model architecture is designed to achieve the opposite of the CBOW model. Instead of predicting the center word from the surrounding context words, it aims to predict the surrounding context words given the center word.
The choice between the two approaches depends on the specific task at hand. The skip-gram model performs well with limited amounts of data and is particularly effective at representing infrequent words. In contrast, the CBOW model produces better representations for more commonly occurring words.
Where to find the training data?
There are various online datasets that can be used for research purposes, such as:
- Text data for several languages from the WMT11 site (remove duplicate sentences before training the models).
- Text data from additional languages can be obtained from statmt.org and the Polyglot project.
Why is Word2Vec revolutionary?
Word2Vec’s meaningful embedding goes beyond traditional word vectorization methods like latent semantic analysis (LSA), singular value decomposition (SVD), or global vectors for word representation (GloVe), which existed before its introduction in 2013. Here’s why.
- Word2Vec creates numerical vectors in a high-dimensional space while preserving the semantic and syntactic relationships between them.
- This concept is more effective than any of its predecessors, as it simplifies the representation of relationships by encoding them into fixed-sized vectors and reducing the dimensionality of the space involved. This simplification makes mathematical analysis easier.
- This technique can be applied to textual data and non-textual data, providing a tool to compare different things and identify similarities, whether it be goods, chemical compounds, gene sequences, or business concepts.
Word2Vec enables training contextualized models using open-source code optimized for speed and efficiency on specific data sets. For example, if your target data is in finance, you can use a model trained on the finance corpus.
What are the limitations of Word2Vec?

- Has difficulty handling unknown words
One of the main issues with Word2Vec is its inability to handle unknown or out-of-vocabulary words. If Word2Vec has not encountered a term before, it cannot create a vector for it and instead assigns a random vector, which is not optimal. This can be especially problematic in noisy data domains like Twitter, where many words are used only a few times in a large corpus.
- Doesn’t have shared representations at sub-word levels
Word to vector does not have shared representations at sub-word levels, meaning it represents each word as an independent vector. This is a problem for morphologically rich and polysynthetic languages like German, Turkish, or Arabic, where many words are morphologically similar.
- Difficult to scale to new languages
To scale Word2Vec to new languages, new embedding matrices are necessary. However, since parameter sharing is impossible, using the same model for cross-lingual applications is not feasible.
What are the applications of W2V?
 Word2Vec models are widely used in various natural language processing applications. Below, we look at some most popular use cases.
Word2Vec models are widely used in various natural language processing applications. Below, we look at some most popular use cases.
Search engines
Word2Vec is used in search engines to improve the accuracy of search results. When a user enters a question, the search engine uses Word2vec to transform it into a vector representation. This vector is then compared to the representations of documents or web pages to determine which are most relevant to the search query. This algorithm also enables search engines to understand the context of a search query. For example, if a user searches for “apple,” Word2Vec can determine whether the user is looking for information about the fruit or the technology company based on the context of the search query.
Language translation
W2V models are also employed for automated translation. They use graphical representations of word meanings across languages to enable automated translation. Popular examples of such applications include Google Translate and Translate.com.
Query clustering and customer feedback analysis
Word2Vec offers a solution for businesses that need to analyze thousands of customer reviews and extract useful metrics. Word embeddings are particularly useful in this context. By creating vector representations of words trained on or adapted to survey data-sets, you can capture the complex relationships between the responses being reviewed and the specific context in which they were given. Machine learning algorithms can then leverage this information for further analysis.This way, you can identify common themes and sentiments, and develop strategies to address these concerns.
Recommendation systems
Word2Vec models are not restricted to textual data. You can apply them to any type of data that comes in a sequence, such as users’ click sessions, search history, and purchase history. This data can be used to create powerful recommender systems that boost online business profits by improving click-through rates and conversions. Fixed-sized vector representations can be created for different items, such as places or products, that capture human-like relationships and similarities between them. For instance, using the vector similarity score between the products, we can recommend accessories or additional sports equipment to the athletes buying the barbell. Similarly, Airbnb trained Word2Vec models on user click and conversion sessions, which they used to generate business value.
Conclusion
Word to vector was invented a decade ago and is now considered an older algorithm in the field of machine learning. It has been outperformed by deep neural networks based on transformers. Nonetheless, this two-layer neural network remains relevant in situations where speed and simplicity of computations are prioritized over solutions offered by other neural networks, for example for mobile applications.






