
In 2020, people benefit from artificial intelligence every day: music recommender systems, Google maps, Uber, and many more applications are powered with AI. However, the confusion between the terms artificial intelligence, machine learning, and deep learning remains. One of popular Google search requests goes as follows: “are artificial intelligence and machine learning the same thing?”.
Let’s clear things up: artificial intelligence (AI), machine learning (ML), and deep learning (DL) are three different things.
- Artificial intelligence is a science like mathematics or biology. It studies ways to build intelligent programs and machines that can creatively solve problems, which has always been considered a human prerogative.
- Machine learning is a subset of artificial intelligence (AI) that provides systems the ability to automatically learn and improve from experience without being explicitly programmed. In ML, there are different algorithms (e.g. neural networks) that help to solve problems.
- Deep learning, or deep neural learning, is a subset of machine learning, which uses the neural networks to analyze different factors with a structure that is similar to the human neural system.
This is how it looks on an Euler diagram:
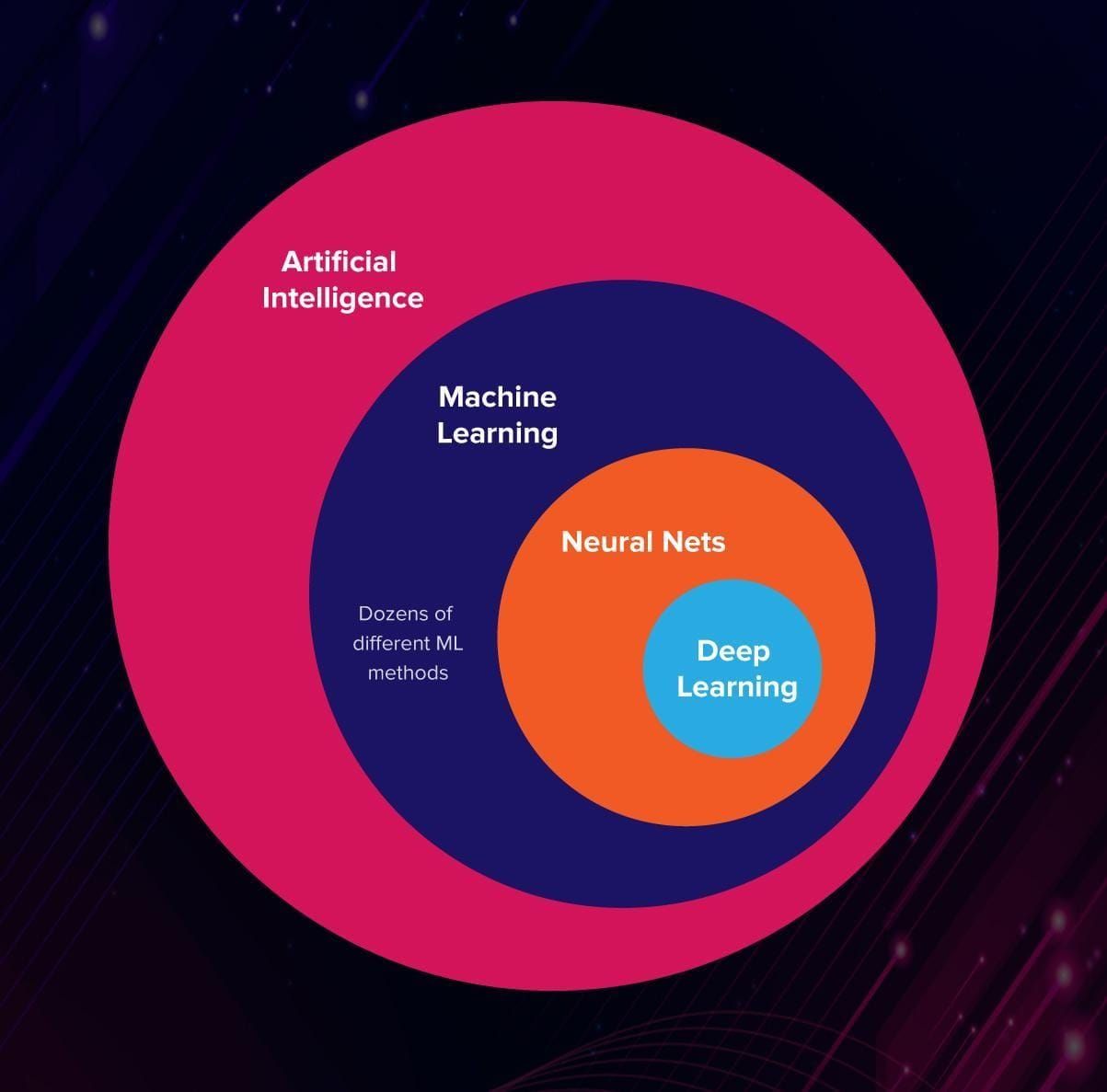
3 faces of artificial intelligence
The term artificial intelligence was first used in 1956, at a computer science conference in Dartmouth. AI described an attempt to model how the human brain works and, based on this knowledge, create more advanced computers. The scientists expected that to understand how the human mind works and digitalize it shouldn’t take too long. After all, the conference collected some of the brightest minds of that time for an intensive 2-months brainstorming session.
Surely, the researchers had fun during that summer in Dartmouth but the results were a bit devastating. Imitating the brain with the means of programming turned out to be… complicated.
Nonetheless, some results were achieved. For example, the researchers understood that the key factors for an intelligent machine are learning (to interact with changing and spontaneous environments), natural language processing (for human-machine interaction), and creativity (to liberate humanity from many of its troubles?).
Even today when artificial intelligence is ubiquitous, the computer is still far from modelling human intelligence to perfection.
AI is generally divided into 3 categories:
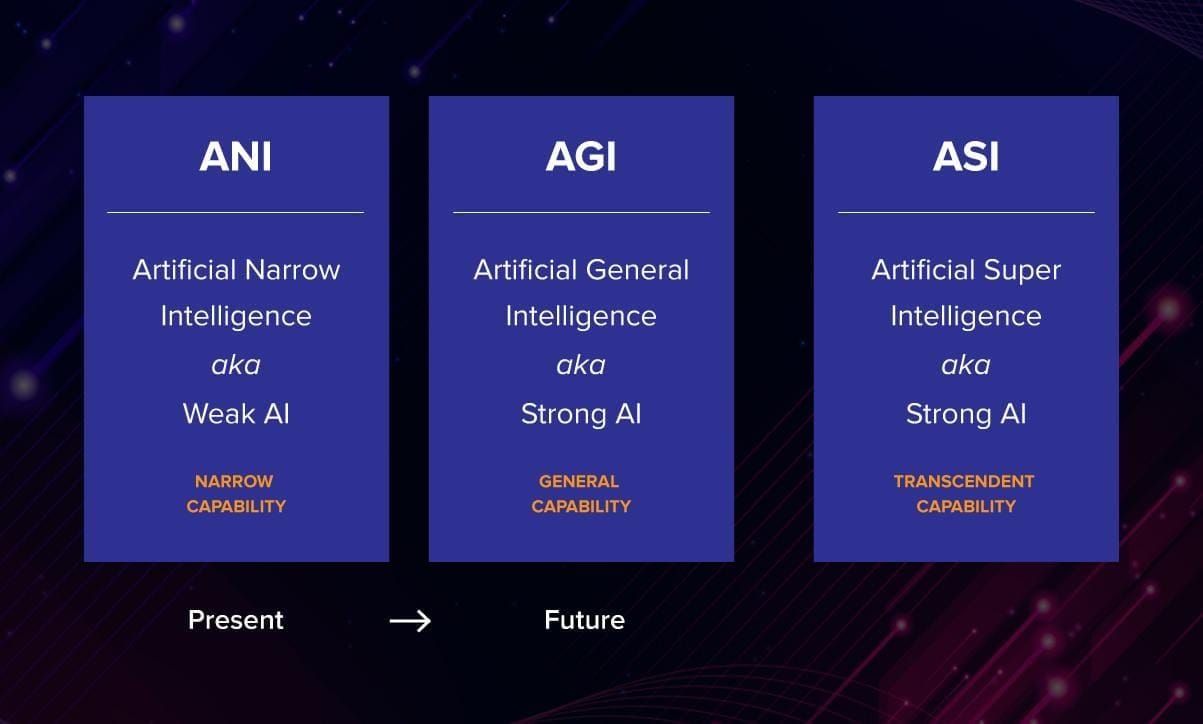
Narrow/Weak AI
To understand what weak AI is, it is good to contrast it with strong AI. These two versions of AI are trying to achieve different goals.
“Strong” AI seeks to create artificial persons: machines that have all the mental powers we have, including phenomenal consciousness. “Weak” AI, on the other hand, seeks to build information-processing machines that appear to have the full mental repertoire of human persons. (Searle, 1997)
Weak, or narrow AI, is good at performing a particular task, but it will not pass for human in any other field outside of its defined capacities.
You have probably heard of Deep Blue, the first computer to defeat a human in chess. Not just any human – Garry Kasparov in 1996. Deep Blue could generate and evaluate about 200 million chess positions per second. To be honest, some were not ready to call it AI in its full meaning, while others claimed it to be one of the earliest examples of weak AI.
Another famous example of AI beating humans in games is AlphaGo. This program won in one of the most complicated games ever invented, learning how to play it and not just calculating all the possible moves (which is impossible).

Nowadays, narrow artificial intelligence is widely used in science, business, and healthcare. For example, in 2017 a company named DOMO declared the launch of Mr. Roboto. This AI software system contains powerful analytics tools and can provide business owners with recommendations and insights for business development. It can detect abnormalities and spot patterns that can be useful for risk management and resourceful planning. Similar programs exist for other industries as well, and large companies such as Google and Amazon invest money in their development.
General/strong AI
This is the point in the future when machines become human-like. They make their own decisions and learn without any human input. Not only are they competent in solving logical tasks but they also have emotions.
The question is: how to build a living machine? You can program the machine to produce some emotional verbal reactions in response to stimuli. Chatbots and virtual assistants are already quite good at maintaining a conversation. Also, the experiments on teaching robots to read human emotions are already in action. But reproducing emotional reactions doesn’t make the machines truly emotional, does it?
Superintelligence
This is the piece of content everybody usually expects when reading about AI. Machines, way ahead of humans. Smart, wise, creative, with excellent social skills. Its goal to either make humans’s lives better or destroy them all.
Here comes the disappointment: the scientists of today don’t even dream of creating autonomous emotional machines like the Bicentennial Man. Well, except maybe for this guy who has created a robocopy of himself.
The tasks that data scientists are focusing on right now (and which can help to create general and superintelligence) are:
- Machine Reasoning. MR systems have some information at their disposal, for example, a database or a library. Using deduction and induction techniques they can formulate some valuable insights based on this information. It can include planning, data representation, search and optimisation for AI systems;
- Robotics. This field of science concentrates on building, developing, and controlling robots from roombas to intelligent androids;
- Machine Learning is the study of algorithms and computer models used by machines in order to perform a given task.
You can call them methods of creating AI. It is possible to use just one or combine all of them in one system. Now, let’s go deeper into details.
How can machines learn?
Machine learning is a subset of the larger field of artificial intelligence (AI) that “focuses on teaching computers how to learn without the need to be programmed for specific tasks,” note Sujit Pal and Antonio Gulli in Deep Learning with Keras. “In fact, the key idea behind ML is that it is possible to create algorithms that learn from and make predictions on data.”
In order to “educate” the machine, you need these 3 components:
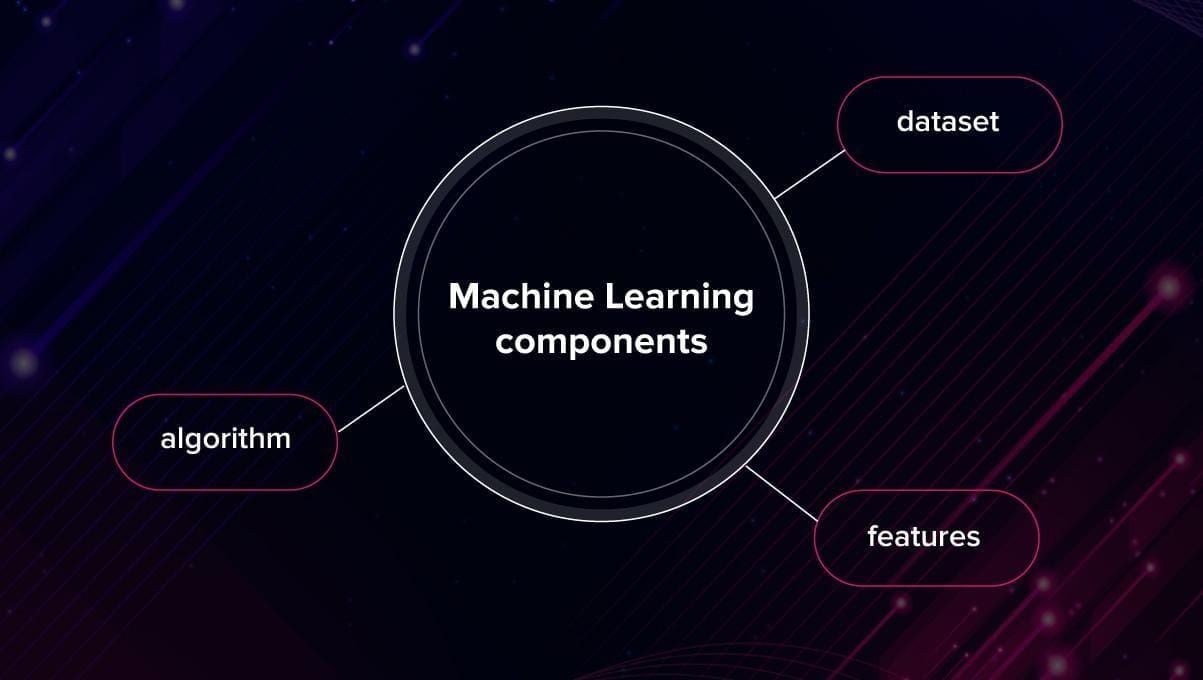
Datasets. Machine learning systems are trained on special collections of samples called datasets. The samples can include numbers, images, texts or any other kind of data. It usually takes a lot of time and effort to create a good dataset.
Features. Features are important pieces of data that work as the key to the solution of the task. They demonstrate to the machine what to pay attention to. How do you select the features? Let’s say, you want to predict the price of an apartment. It is hard to predict by linear regression how much the place can cost based on the combination of its length and width, for example. However, it is much easier to find a correlation between price and the area where the building is located.
Note: It works as above in case of supervised learning (we will talk about supervised and unsupervised ML later on) when you have training data with labeled data, which contain the “right solutions”, and a validation set. During the learning process, the program learns how to get to the “right” solution. And then, the validation set is used to tune hyperparameters to avoid overfitting. However, in unsupervised learning, features are learned with unlabeled input data. You do not tell the machine where to look at, it learns to notice patterns by itself.
Algorithm. It is possible to solve the same task using different algorithms. Depending on the algorithm, the accuracy or speed of getting the results can be different. Sometimes in order to achieve better performance, you combine different algorithms, like in ensemble learning.
Any software that uses ML is more independent than manually encoded instructions for performing specific tasks. The system learns to recognize patterns and make valuable predictions. If the quality of the dataset was high, and the features were chosen right, an ML-powered system can become better at a given task than humans.
Deep learning
Deep learning is a class of machine learning algorithms inspired by the structure of a human brain. Deep learning algorithms use complex multi-layered neural networks, where the level of abstraction increases gradually by non-linear transformations of input data.
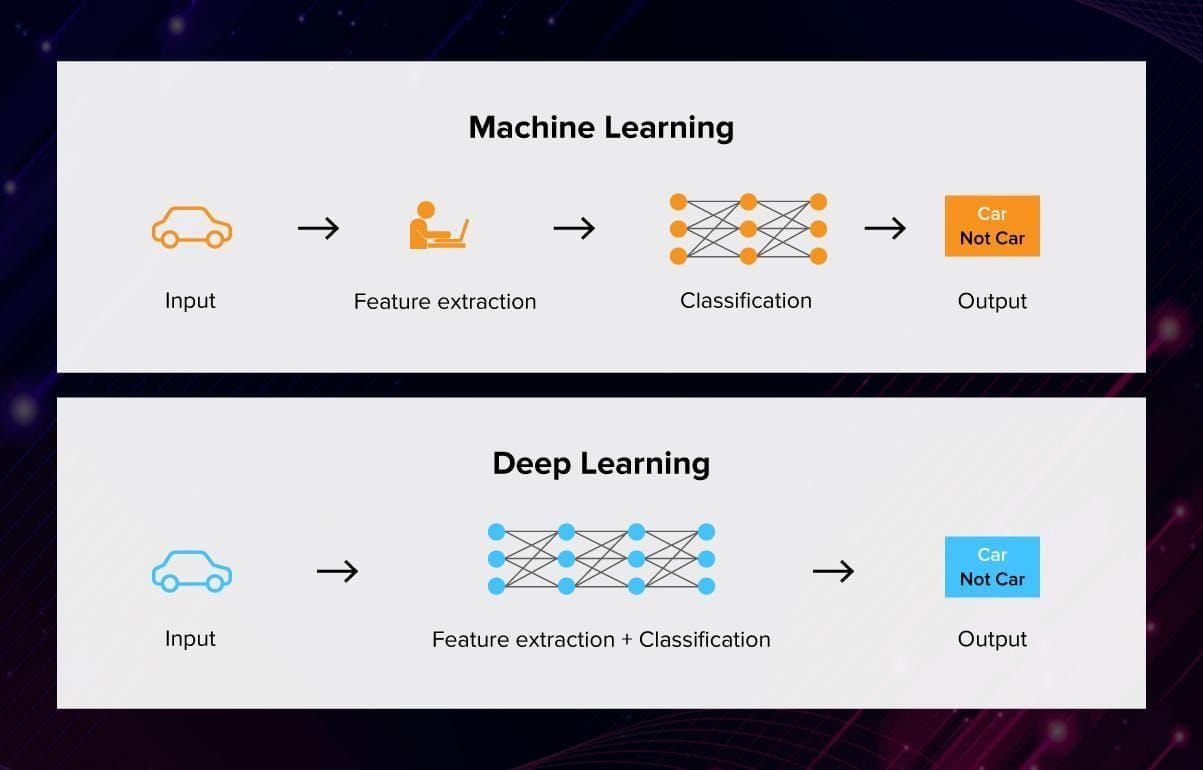
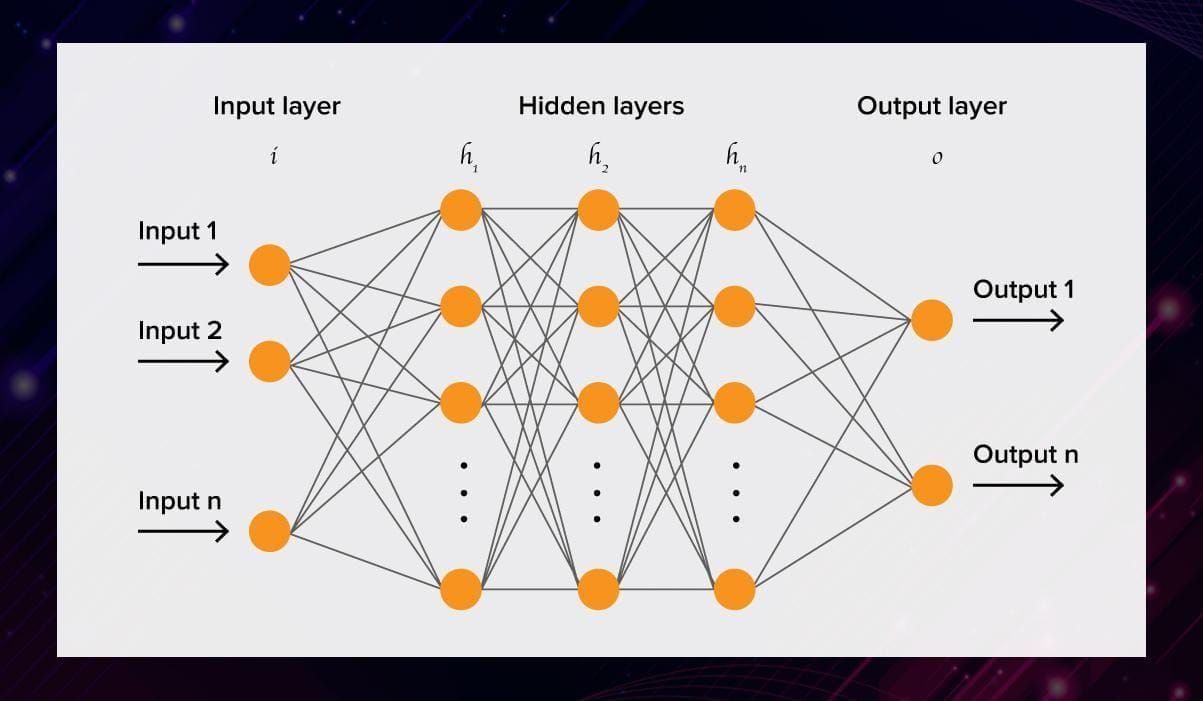
In a neural network, the information is transferred from one layer to another over connecting channels. They are called weighted channels because each of them has a value attached to it.
All neurons have a unique number called bias. This bias is added to the weighted sum of inputs reaching the neuron, to which then an activation function is applied. The result of the function determines if the neuron gets activated. Every activated neuron passes on information to the following layers. This continues up to the second last layer. The output layer in an artificial neural network is the last layer that produces outputs for the program.
Watch this video to have a more detailed look at the process.
In order to train such neural networks, a data scientist needs massive amounts of training data. This is due to the fact that a huge number of parameters have to be considered in order for the solution to be accurate.
Deep learning algorithms are quite the hype now, however, there is actually no well-defined threshold between deep and not-so-deep algorithms. However, if you would like to have a deeper understanding of this topic, check out this blog post by Adrian Colyer.
Some practical applications of DL are, for example, speech recognition systems such as Google Assistant and Amazon Alexa. The sound waves of the speaker can be represented as a spectrogram, which is a time-snapshot of different frequencies. A neural network that is capable of remembering sequence inputs (such as LSTM, short for long-short-term-memory) can recognize and process such sequences of spatial-temporal input signals. It learns to map the spectrogram feeds to words.
DL comes really close to what many people imagine when hearing the words “artificial intelligence”. The computer learns by itself; how awesome is that?! Well, the truth is that DP algorithms are not flawless. Programmers love DL though, because it can be applied to a variety of tasks. However, there are other approaches to ML that we are going to discuss right now.
No Free Lunch and why there are so many ML algorithms
Before we start: There are several ways to classify the algorithms, and you are free to stick to the one you like best.
In artificial intelligence science, there is a theorem called No Free Lunch. It says that there is no perfect algorithm that works equally well for all tasks: from natural speech recognition to surviving in the environment. Therefore, there is a need for a variety of tools.
Algorithms can be grouped by their learning style or similarity. In this post, you will have a glance at the algorithms grouped based on their learning style because it is more intuitive for a first-timer. A classification based on similarity you can find here.
Four groups of ML algorithms
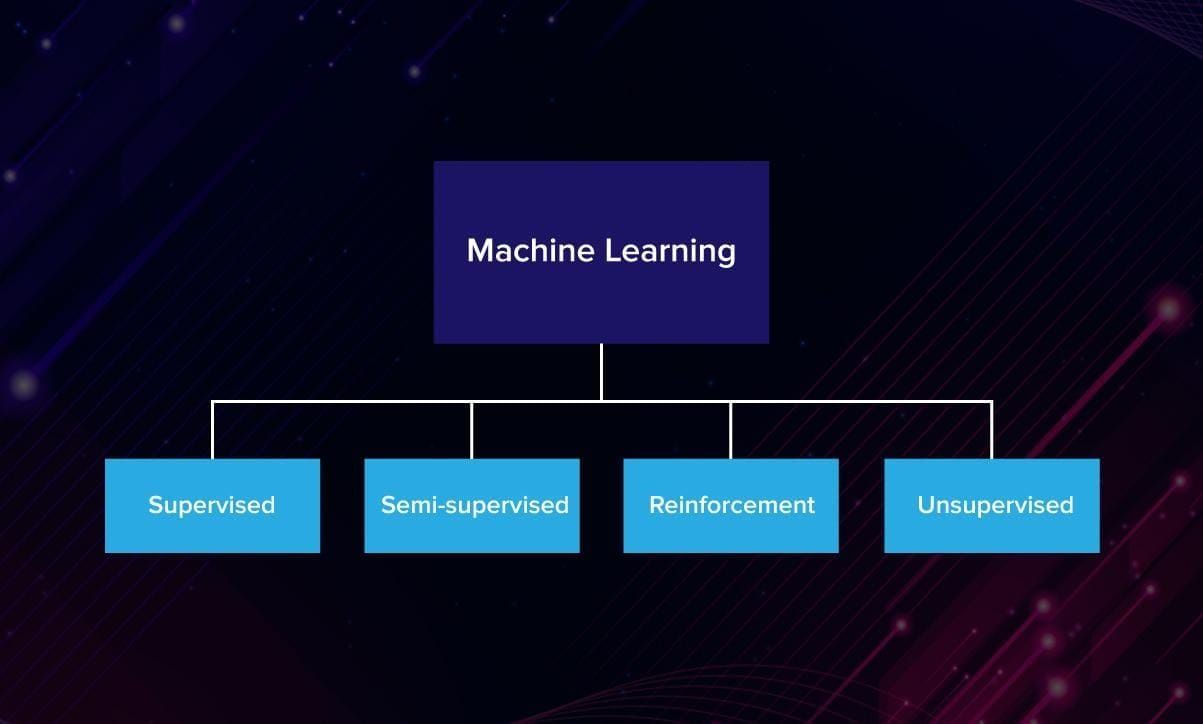
So, based on how they learn, machine learning algorithms are usually divided into 4 groups:
Supervised Learning
“Supervised” means that a teacher helps the program throughout the training process: there is a training set with labeled data. For example, you want to teach the computer to put red, blue and green socks into different baskets.
First, you show to the system each of the objects and tell what is what. Then, run the program on a validation set that checks whether the learned function was correct. The program makes assertions and is corrected by the programmer when those conclusions are wrong. The training process continues until the model achieves a desired level of accuracy on the training data. This type of learning is commonly used for classification and regression.
Algorithm examples:
- Naive Bayes,
- Support Vector Machine,
- Decision Tree,
- K-Nearest Neighbours,
- Logistic Regression,
- Linear and Polynomial regressions.
Used for: spam filtering, language detection, computer vision, search and classification.
Unsupervised Learning
In unsupervised learning, you do not provide any features to the program allowing it to search for patterns independently. Imagine you have a big basket of laundry that the computer has to separate into different categories: socks, T-shirts, jeans. This is called clustering, and unsupervised learning is often used to divide data into groups by similarity.
Unsupervised learning is also good for insightful data analytics. Sometimes the program can recognize patterns that the humans would have missed because of our inability to process large amounts of numerical data. For example, UL can be used to find fraudulent transactions, forecast sales and discounts or analyse preferences of customers based on their search history. The programmer does not know what they are trying to find but there are surely some patterns, and the system can detect them.
Algorithm examples:
- K-means clustering,
- DBSCAN,
- Mean-Shift,
- Singular Value Decomposition (SVD),
- Principal Component Analysis (PCA),
- Latent Dirichlet allocation (LDA),
- Latent Semantic Analysis, FP-growth.
Used for: segmentation of data, anomaly detection, recommendation systems, risk management, fake images analysis.
Semi-supervised Learning
As you can judge from the title, semi-supervised learning means that the input data is a mixture of labeled and unlabeled samples.
The programmer has in mind a desired prediction outcome but the model must find patterns to structure the data and make predictions itself.
Reinforcement Learning
This is very similar to how humans learn: through trial. Humans don’t need constant supervision to learn effectively like in supervised learning. By only receiving positive or negative reinforcement signals in response to our actions, we still learn very effectively. For example, a child learns not to touch a hot pan after feeling pain.
One of the most exciting parts of reinforcement learning is that it allows you to step away from training on static datasets. Instead, the computer is able to learn in dynamic, noisy environments such as game worlds or the real world.
Games are very useful for reinforcement learning research because they provide ideal data-rich environments. The scores in games are ideal reward signals to train reward-motivated behaviours, for example, Mario.
Algorithm examples:
- Q-Learning,
- Genetic algorithm,
- SARSA,
- DQN,
- A3C.
Used for: self-driving cars, games, robots, resource management.
Summing up
Artificial intelligence has many great applications that are changing the world of technology. While creating an AI system that is generally as intelligent as humans remains a dream, ML already allows the computer to outperform us in computations, pattern recognition, and anomaly detection. Read more materials about ML algorithms, DL approaches and AI trends in our blog.

.jpg)
.jpg)
.jpg)
.jpg)

