
The explosive growth of large language models (LLMs) has reshaped the AI landscape. Yet their core design is still fundamentally stateless: a drawback often referred to as “conversational amnesia.” An LLM can only operate within a limited context window and, paradoxically, loses more signal as that window grows, making it unable to reliably carry information forward across extended interactions.
This limitation remains the key blocker to building truly persistent, collaborative, and personalized AI agents that can handle complex, multi-step, long-running workflows. To overcome it, the industry is moving past traditional stateless Retrieval-Augmented Generation (RAG) and toward more advanced architectural patterns purpose-built for long-term memory.
This report outlines and contrasts four leading design philosophies that have emerged:
- The Operating System Paradigm (MemGPT). Treats memory as a managed computational resource, virtualizing LLM context to simulate infinite capacity.
- OpenAI memory management. A product-driven approach where memory enables seamless, persistent personalization across all interactions.
- Claude memory management. Prioritizes user control and strict data isolation, using memory as a project-scoped workspace tool.
- AI Toolkits memory management. Open source provides building blocks for developers to design custom, domain-specific memory systems.
Our high-level findings reveal a clear trade-off between automated convenience and explicit control. Emerging systems such as MemGPT and modular agent frameworks point toward a future of autonomous, self-managing memory.
System I: MemGPT — The Operating System Paradigm
MemGPT represents a fundamental architectural shift: it reframes memory not as a content-management problem but as a resource-management challenge. Inspired directly by computer operating system design, it treats the LLM’s finite context window not as a hard limit but as a form of fast, volatile memory (analogous to RAM), to be intelligently managed alongside a larger, persistent storage layer (analogous to disk).
According to the well-known researcher Andrej Karpathy, a lot of computing concepts carry over in this paradigm. Concepts from computer security carry over, with attacks, defenses and emerging vulnerabilities. E.g. today it orchestrates:
- Input & Output across modalities (text, audio, vision)
- Code interpreter, ability to write and run programs
- Browser / internet access
- Embeddings database for files and internal memory storage and retrieval
According to him, looking at LLMs as chatbots is the same as looking at early computers as calculators. We’re seeing an emergence of a whole new computing paradigm. and it is very early.
Core Architecture: Virtual Context Management
At its core, MemGPT features a hierarchical memory architecture closely mirroring that of a traditional OS:
-
Primary Context (RAM) — The fixed-size prompt that the LLM can directly “see” during inference.
It consists of three partitions:-
Static system prompt, containing base instructions and function schemas.
-
Dynamic working context, serving as a scratchpad for reasoning steps and intermediate results.
-
FIFO message buffer, holding the most recent conversational turns.
-
-
External Context (Disk Storage) — An effectively infinite, out-of-context layer inaccessible to the model without explicit retrieval.
It includes:-
Recall Storage, a searchable document or log database containing the full historical record of interactions for literal recall.
-
Archival Storage, a long-term, vector-based memory for large documents and abstracted knowledge retrievable via semantic search.
-
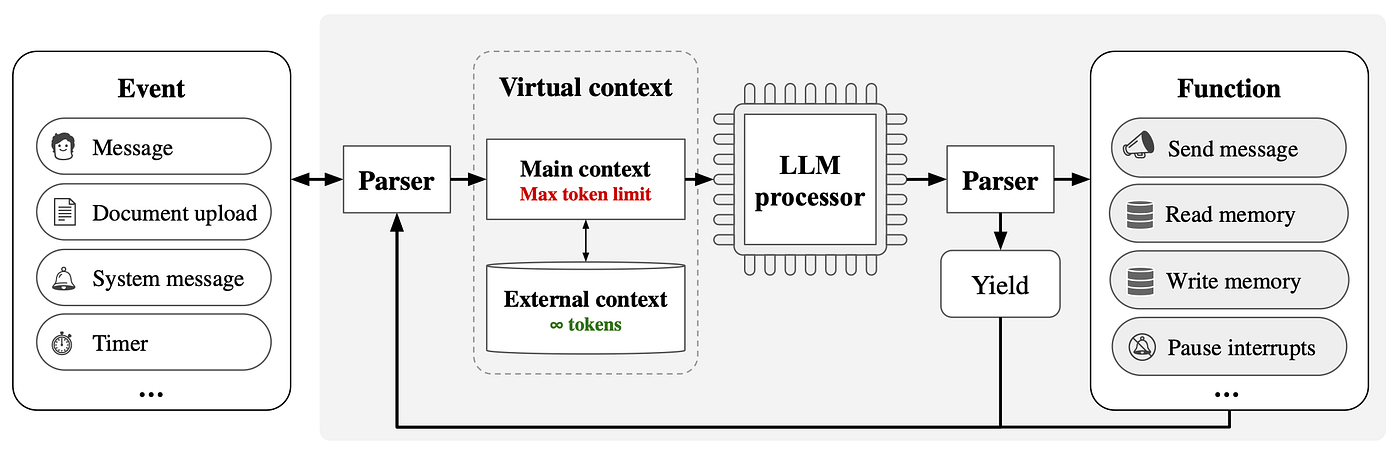
Information flow between these tiers is governed by a strict paging mechanism. The LLM “processor” works only within the primary context. To access external data, it must autonomously issue explicit function calls (e.g., conversation_search, archival_memory_search).
Results from these calls are then paged in, replacing less relevant segments in the FIFO queue, and creating the illusion of an unbounded context window while remaining within the physical token limits of the underlying model.
Memory Formation: The Self-Managed Write-Back Cycle
Persisting information into long-term memory occurs through an event-driven write-back cycle, analogous to an OS interrupt.
The process is triggered by memory pressure: when token usage in the primary context approaches a defined threshold (e.g., 70% capacity), the system inserts an internal alert.
Upon receiving this signal, the LLM halts its current reasoning, reviews its working memory, determines which content is least critical, summarizes it, and writes it to the appropriate external tier.
Crucially, the LLM itself manages this cycle—autonomously deciding what to keep, what to discard, and where to store it.
This self-reflective capability allows for dynamic memory correction (e.g., overwriting outdated facts) and embodies a primitive form of cognitive self-regulation.
Tooling and Technology Stack
Typical implementations leverage the following stack:
-
Core Framework: The original MemGPT open-source Python framework, now evolved into Letta.
-
LLM Compatibility: Model-agnostic but optimized for function-calling models such as OpenAI’s GPT-4 or GPT-3.5.
-
Vector Databases: Used for archival semantic search; common options include Chroma, LanceDB, or pgvector.
-
Persistent Storage: Recall layers often use lightweight databases or file systems for event logs and message histories.
Strengths:
Elegant abstraction of the finite-context problem; creates the illusion of infinite memory via virtualization.
Limitations:
All reasoning and memory management are handled by a single agent, consuming valuable cognitive bandwidth.
Because stored data is unstructured, performing complex relational queries (e.g., “Which decisions were influenced by facts from source X?”) is nearly impossible without heavy post-processing—precisely what MaaS aims to solve.
In short, MemGPT’s brilliance lies in its autonomy—but that autonomy comes at a cost. Every cycle spent on memory logistics is a cycle not spent on task reasoning.
System II: OpenAI Memory Management
OpenAI’s memory for ChatGPT represents a product-first architecture designed to deliver a seamless, deeply personalized experience.
Unlike other models, it implements a global, user-centric memory that persists across all conversations, making the assistant continuously aware and contextually intelligent with minimal user effort.
Core Architecture: Hybrid Fact + Semantic Storage
The system combines two complementary memory layers:
-
Saved Memories. While we do not exactly know how it is organized, it can be viewed as a page or two of different facts collected together from all of your chats. LLM decides automatically which of the data you’ve provided via your current conversation is added there. These can be explicitly provided (“Remember that I live in San Francisco”) or automatically classified by the model as potentially useful. Each session begins with this document prepended to the LLM prompt, ensuring continuity. We assume that they also might use some simple key-value database to manage it more accurately.
-
Chat History Reference. A large-scale RAG-style retrieval layer that semantically searches across all previous user interactions to find relevant context fragments for the current query. According to the system’s behaviour we assume that this search is working on the whole text, not on the summaries of these chats.
During response generation, both layers are queried in parallel. Memories are added to the beginning of the conversation. Semantically matched chat snippets are combined into the model’s context according to the concrete request, yielding personalized, contextually aware outputs.
Memory Formation
The write-back cycle operates in two modes:
-
Explicit Commands. The user directly instructs the model to remember or forget something.
-
Automatic Extraction. Background classifiers continuously scan conversations to identify recurring or salient information (e.g., profession, tone preferences). Extracted facts are either suggested to or silently added into the saved memory layer.
User oversight remains central. Through the ChatGPT settings interface, users can view, edit, or delete any stored memory, ensuring transparency, privacy, and control.
Technology Stack (Presumably)
While proprietary, the architecture likely includes:
-
A high-performance vector store for semantic retrieval over historical chats.
-
A scalable key-value or document database for structured “saved memories.”
-
A background extraction pipeline leveraging a classification model.
Strengths:
Delivers effortless, “magical” personalization at global scale, which is perfect for user application.
Limitations:
Global scope makes it unsuitable for enterprise or professional contexts. The risk of context leakage (where information from one client or topic influences another) is inherent to its design. Also it is not supporting multi-user usage in the same scope, at least for now.
In essence, OpenAI’s architecture mirrors its business strategy: prioritize simplicity and personalization for a mass audience over data compartmentalization or symbolic structure. Its strength lies in accessibility and its limitation lies in lack of user control.
System III: Claude Memory Management
Claude’s approach stands as a philosophical counterpoint to OpenAI’s global personalization. Anthropic emphasizes user control, explicit activation, and strict data compartmentalization, producing a memory system that is less automated but more predictable: well-suited to professional workflows where data separation is non-negotiable.
Core Architecture: Project Summaries and File-Scoped Context
Claude’s memory combines official features with strong, community-driven patterns:
-
Project Memory (Team/Enterprise). Users create distinct projects, each with its own editable memory summary of key facts, instructions, and context. That summary is automatically injected into prompts for all chats within the same project, enforcing hard boundaries – nothing from Project A can bleed into Project B.
-
Community Patterns in
CLAUDE.md. In developer workflows, teams often include aCLAUDE.mdfile at the repo root. When interacting with Claude in that working directory, the file is read and included in context. This acts like “context injection,” not dynamic RAG: the whole file is loaded, enabling versioned, reviewable, and Git-managed context (architecture principles, coding standards, API specs) that sits alongside the codebase. -
On-Demand Retrieval Tools. When explicitly asked to “recall” something from the past, Claude appears to use internal tools (e.g.,
conversation_search) confined to the current project. It doesn’t rely on a global index, reinforcing compartmentalization.
Memory Formation: Mostly Curated by the User
In contrast to OpenAI’s automation, Claude’s write-back cycle is largely explicit:
-
Project memory is updated because a user asks for it to be updated.
-
The
CLAUDE.mdpattern is edited by humans via normal version control. -
Memory is not “always on”; users often prompt Claude to look back, which in turn activates the project-limited search tools.
-
The search implementation has two key elements:
- Conversation search. Makes keyword and topic-based searches across the entire conversation history.
- Recent chats. Provides time-based access to the conversation history with customizable sort chronological order and optional pagination using ‘before’ and ‘after’ datetime filters.
Technology Stack
-
Anthropic Platform: Project memory is a first-class feature in Claude’s web app/API for Team/Enterprise plans.
-
Files + Version Control: The
CLAUDE.mdpattern relies only on standard files, editors, and Git. -
3rd-Party Connectors: An emerging ecosystem (e.g., CLI tools) exposes long-term or local stores via Claude tool integrations.
Strengths:
Advanced control, predictability, and transparency. Ideal for client work and regulated environments where data isolation is paramount.
Limitations:
High cognitive load and limited scalability. Memory grows only as fast as users curate it.
Large, monolithic summaries risk the loss of information.
System IV: AI Toolkits Memory Management
LangChain and Microsoft Autogen aren’t memory products; they’re frameworks that give you the primitives to assemble sophisticated memory architectures. The payoff is fine-grained control, but the cost is engineering effort.
Core Architecture: Composable and Protocol-Oriented
-
LangChain Memory Modules:
-
Buffer Memory and Window Memory (short-term chat windows),
-
Summary Memory (periodic LLM summaries to save tokens),
-
Entity Memory (structured capture of people/orgs/concepts),
-
Knowledge-Graph Memory that builds nodes/edges on the fly for relational querying.
-
-
LangGraph for Stateful Agents. A graph-based orchestration layer for building cyclic, multi-agent workflows where memory is an explicit part of the agent’s state persisted across steps and sessions.
-
Autogen Memory Protocol. A generalized Memory interface with a RAG-centric pattern: agents query external memory stores to enrich their context. Community integrations cover vector DBs and third-party memory services.
Memory Formation: Your Design
These frameworks don’t ship with an “always-on” write-back loop. You design it yourself. For example:
- The agent completes a step.
- A “memory extraction” tool (often LLM-powered) distills facts, entities, or relationships.
- A “memory store” tool writes structured results to the chosen backend (vector store, graph DB, KV/Doc store).
Technology Stack
- Languages: Python and JavaScript/TypeScript.
- Orchestration: LangChain, LangGraph, Autogen
- Pluggable Datastores:
- Vector stores: Pinecone, Chroma, Weaviate, LanceDB.
- Graph DBs: Neo4j, Memgraph, Kùzu.
- KV/Document stores: Redis, MongoDB.
Basically anything you want as they are both open-sourced.
Strengths:
Unmatched flexibility. You can encode the exact memory structure, DB tech, and agent logic your domain needs, often surpassing off-the-shelf systems with the precise tinkering.
Limitations:
Complex and expensive to build and maintain. Reliability, scale, consistency, and data governance are your responsibility.
Industry Trajectory:
Early memory systems leaned on raw text + vector search. That hits a ceiling for relational questions (“Who’s working with Alice on currently blocked projects?”). Later we introduced entities and relationships, knowledge graphs. Patterns like LangChain’s KG memory and growing Graph DB integrations signal a shift from mere similarity search toward relational reasoning, the most plausible path to collaborative, “systems-level” agents.
Final thoughts on the current state
Basically every approach has its strengths and weaknesses, to quickly summarize:
- OpenAI. Frictionless, “magical” continuity for individuals: great for consumers but risky for enterprise separation.
- Claude. Strong isolation and user control: great for client work and regulated contexts but manual effort required.
- MemGPT. Autonomous context virtualization: near-infinite memory feel but single-agent overhead and unstructured storage limit relational queries.
- Toolkits. Maximum customizability: best path to tailor-made, domain-specific systems but highest build complexity.
While there is no universally accepted approach to handle AI agents memory management right now, we can foresee some strong emerging trends and patterns that will result in more stable, reliable, safe and interpretable AI systems in the near future. For example, modern systems went from direct context sharing into some RAG capabilities and now are moving into autonomous memory orchestration with LLMs using tools provided by developers. In order to handle the logic and provide additional guardrails industry is shifting from unstructured snippets and restricting prompts with cornercases into direct knowledge graph usage. And nowadays, in order to prevent context overflow more systems are moving from single agent calls into multi-agent pipelines. These pipelines might accumulate a lot of errors due to the snowball effect of inaccurate agents being called on each step, which also will be overcome with knowledge graphs, shared memory pipelines and its strict typing with audition capabilities.






