
The term “foundation models” is very new. It was introduced and popularized by the Stanford Institute for Human-Centered Artificial Intelligence when first large-scale multitask models started to appear in 2019-ish.
Early examples of foundation models are GPT-3, BERT, and DALL-E 2. They were called “base models” or “foundation models” because they were trained on a massive amount of multimodal data. That allowed them to perform an assortment of tasks — all you need to do is provide the model with an input, aka request. And the model will generate art for you, write an essay, or an email.
In this article, you will learn more about how such models are built and how they work.
What is a foundation model?
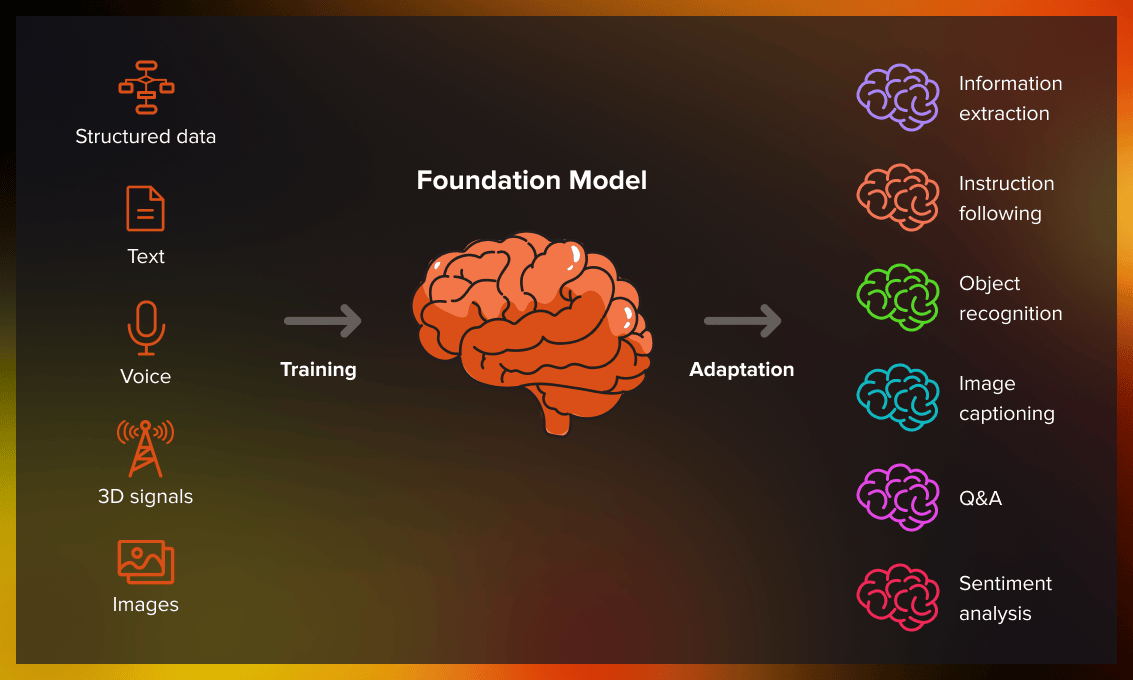
Foundation model is an enormous machine learning model that has been trained on a lot of unstructured unlabeled data. The data can be of different formats including text, images, videos. It can also include multiple types of data at once since for many real-life tasks multimodality of the model is key. The resulting model can be adapted to perform a large variety of different tasks. For example, if it has been trained on different textual data it can write movie scripts, ads, essays, or academic papers. They adapt fast and can learn new tricks during training. If it has been trained on images, it can generate digital arts, fake images of existing or non-existent people or places, etc.
Moreover, foundation models usually require little technical knowledge to operate them. Most of the neural networks that are available to the public only need input in a natural language that formulates the task and the expected outcome.
Some examples of foundation models are BERT, DALLE, GPT models, MidJourney. We will talk more in detail about them later in the article.
“Foundation” means that these models can serve as a base or foundation for multiple ML tasks.
At the base of the foundation model lay such technologies as self-supervised learning and transformers. However, what is new about these models is their ability to scale even more and perform tasks beyond training.
The capabilities of foundation models are incredibly wide. Here are just a few:
- Language. Foundation models dominate NLP tasks: they can be used for many linguistic tasks from writing different texts to voice-over and translation. The same model can operate different languages, dialects, and styles.
- Robotics. Generalist robots, i.e. house helpers and companion robots need to perform a variety of tasks in the physical world to be efficient. However, today the field is encountering significant limitations to achieve universal robots, as there isn’t sufficient data in the right form to train them. Foundation models can help overcome these limitations by providing different ways to learn.
- Computer vision. Foundation models can use multimodal data when working with images and videos. And that can significantly improve the quality of computer vision solutions, as the model has multiple streams of information.
- Philosophy and research. By observing how machines learn about language and the world, we can understand something new about how we learn about the world.
The foundation model capabilities aren’t limited to these topics. Perhaps we will live to see the future where foundation models are even more omnipresent.
How do foundation models generate response?
Foundation models are a type of machine learning model that are designed to learn from vast amounts of data in order to generate responses to user input.
So, how do foundation models generate response? The answer lies in their architecture, which is typically based on a deep neural network. This network is composed of many layers of interconnected nodes, each of which performs a specific function in the learning process.
At the heart of this architecture is the concept of an embedding layer. This layer maps input data, such as text or speech, to a high-dimensional vector space. This process allows the model to represent words and phrases as numerical vectors, which can then be used to perform mathematical operations that capture the relationships between them.
Once the input data has been mapped to the embedding layer, it is passed through a series of hidden layers. These layers use a combination of linear and non-linear transformations to extract features from the input data. The output of each hidden layer is then passed to the next layer, until the final layer produces the model’s response.
The output of the final layer can take many forms, depending on the application. For example, in a chatbot, it might be a text response that is generated based on the user’s input. In a language translation model, it might be a translated sentence. In a sentiment analysis model, it might be a score that indicates the sentiment expressed in a given piece of text.
Overall, foundation models are incredibly powerful tools for generating responses to user input. By leveraging deep neural networks and embedding layers, these models are able to learn from vast amounts of data and generate highly accurate responses to a wide range of tasks.
How are foundation models trained?
To build a foundation model, you need to go through several steps:
Data creation
Foundation models require massive amounts of data during training. This step involves collecting data usually created by other people such as photos, emails, medical documents.
In The Next Platform, they have calculated the resources needed to train a foundation model:
*Our guess is that it would take about a year to run a 500 billion parameter GPT model on a four-node CS-2 cluster, and across a 16-node cluster, you might be able to do 2 trillion parameters in a year. Or, based on our estimates, that would let you train from scratch a GPT 175B from scratch more than 13 times – call it once a month with a spare. So that is what you would get for forking out $30 million to have your own Andromeda CS-2 supercomputer. But renting 13 GPT 175B training runs might cost you on the order of $142 million if our guesstimates are right about how pricing and performance will scale up on the AI Model Studio service scales.
— Counting the Cost of Training Large Language Models, The Next Platform*
Some even warn about the future where we won’t have enough data to train our models and will have to switch to alternative architectures. Our Data Science Team Lead has written an article about it for VentureBeat.
Data curation
Foundation models learn from unlabeled datasets. However, it’s wrong to think that unlabeled data just means “scrape whatever you can and run your model on it”. Data curation is a metadata managing activity that makes relevant data easy to find and access for the model. During this process, data is organized into datasets. Engineers check that data is relevant and of high enough quality.
Training
Foundation models use unsupervised learning techniques, such as autoencoders or generative adversarial networks (GANs), to learn from unstructured data. These techniques can be used to pretrain the model on large amounts of unlabeled data before fine-tuning it on labeled data for a specific task. Moreover, foundation models use self-supervised learning to generate labels directly from input data and improve the predictions. Foundational models also employ transfer learning.
Transfer learning works by taking the knowledge an AI model has to gain to perform the tasks it can already do and expanding upon it to teach the model to perform new tasks — essentially “transferring” the model’s knowledge to new use cases.
— Foundation Models: AI’s Next Frontier, Technopedia
Training curation
Supervised learning can be used on some subsets of the data to fine-tune it to a particular task. During training, the model is presented with input data and corresponding output data, known as labels. For example, in a chatbot application, the input might be a user’s message and the output might be the appropriate response.
The model then uses this labeled data to adjust the weights and biases of its neural network in order to minimize the difference between its predicted output and the true output. This process is repeated many times, with the model gradually improving its accuracy as it learns from more data. During this stage, we want to fix misalignment and introduce protection against weird unexpected behavior, such as encoding non-disclosure of data, for example.
Model transfer
The trained model needs to be adapted to a domain and a particular set of tasks. For example, in the case of ChatGPT, GPT-3 (or 4) is the foundation model, and the chat is a sort of a superstructure, an interface that allows the user to manipulate the model. GPT was used both in the chatbot and the coding assistant Copilot. DALL-E also uses GPT to create images and texts but has a slightly different model on top of it.
Model curation
Different rules and modules are created to improve the performance of the model. For example, ChatGPT isn’t allowed to produce racists or sexist content. Other foundation model may also have filters such as adult content, hate speech, etc.
How do foundation models work?
Foundation models work on the principle of emergence. Emergence characterizes how deep the engineers need to understand the task in order to create a model that can solve it.
Compare:
- In machine learning, the engineer chooses an algorithm that instructs the machine how to solve a task, for example, by applying decision trees. They had to think how to teach the algorithm to do what they wanted it to do and select the algorithm that would be best suited for a particular task.
- In deep learning, thanks to neural networks, it is the machine that learns to extract important features from the data and manipulate them, however, the role of pretraining the model is still huge. In deep learning, neural networks would be trained on raw data, extract higher-level features through the training process (representation learning), and gain on standard benchmarks, in basically any task or industry.ML engineers still need to design an architecture but they don’t have to solve high-level tasks such as feature-extraction. However, the architecture sets limitations to what kind of tasks the model can solve.
- In foundational models, the models use data to learn a wide range of functionalities. For engineers, there is no need to think about features or architecture since a large complex model will select the architecture and features as well, including even advanced features. In foundation models, the use of transfer learning allows to not simply reuse the architecture but also take the ‘knowledge’ learned from one task (for example, object recognition in images) and apply it to another task (video classification).
Risks of foundation models
Foundation models aren’t all fun and games. There are risks associated with building and using them too.
Flaw-inheritance
With foundation models, there is always a risk that bias and flaw can be inherited by all adapted models. There can appear hard-to-understand and unexpected model failures that are, consequently, hard to fix. Therefore, aggressive homogenization can present not only benefits but also significant risks. A way to avoid it is to strive to develop ethical models.
Resources-hungry
Foundation models consume a lot of resources. Not only data (although you do need a lot of data to train them) but also computer resources, power, and electricity. A system like ChatGPT consumes so much electricity that it would be enough to power a whole town. So the next time you want to go talk to the bot, remember about ecology.
What are the applications of foundation models?
Common applications of foundation models include:
Healthcare
Foundation image recognition models can be fine-tuned for medical purposes. Many biomedicine tasks require expensive expert knowledge such as disease treatment or discovery of new drugs. Foundation models can automate these processes and make them less expensive without compromising on efficiency. Moreover, much of healthcare data is naturally multimodal such as test results, etc. For example, at Merelogic, they help companies to integrate AI/ML into drug development pipelines in a way that drives drug programs forward.
Law
Foundational models can help in law to process large amounts of data, decipher ambiguous legal jargon, and construct coherent narratives for lawyers to use. Moreover, their generative abilities could help to generate routine paperwork. For example, ChatGPT for lawyers can be used to summarize legal documents, improve their style, and compose notes and other documents.
Education
Foundation models can assist with generating tasks and providing feedback for teachers and more efficient grading of papers. Foundation models can potentially make the educational process much more personalized.
ChatGPT teaches students to ask better questions and then defend those questions, which could help them become real scientists. ChatGPT can also be used to incite classroom or lab discussion.
— James W. Pennebaker, PhD, a professor of psychology at the University of Texas at Austin
Engineering
GitHub Copilot uses machine learning algorithms to suggest code as developers write it. Copilot can recommend whole code blocks, remarks, based on the engineer’s past coding designs. Coding speed and effectiveness could be significantly enhanced with Copilot.
According to research done by GitHub, the group that used GitHub Copilot had a higher rate of completing the task (78%, compared to 70% in the group without Copilot). The striking difference was that developers who used GitHub Copilot completed the task significantly faster–55% faster than the developers who didn’t use GitHub Copilot.
Conclusion
Foundation models are an important invention that can produce benchmark results in many fields from natural language processing to computer vision. However, there are also risks associated with the design and use of such models. Being developed by big tech companies, they aren’t monitored by the public, which raises the question of how ethical these models are. We are yet to live and see how foundation models will be developed in the future.
Resources used in this article are:
- On the Opportunities and Risks of Foundation Models by Bommasani et al.
- On the Opportunities and Risks of Foundation Models YouTube video by Samuel Albanie

.jpg)
.jpg)



