.png)
In this edition of our Haskell in Production series, we feature e-bot7 – a low-code conversational AI platform designed for customer service and support.
The questions in the article were answered collaboratively by Max Gerer, the co-founder and CTO of e-bot7, and Andreas Scharf, who is the tech lead of e-bot7’s Conversational Engine team.
Read further to learn where e-bot7 uses Haskell, why they decided to adopt it, and what was their experience using it.
How e-bot7 uses Haskell in Production
Could you give our readers a brief introduction to e-bot7 and your roles there?
We are e-bot7 co-founder and CTO Max Gerer and Conversational Engine team tech lead Andreas Scharf. E-bot7 is a low-code conversational AI platform designed for customer service and support. It uses natural language processing (NLP) and machine learning algorithms to understand and respond to customer inquiries in real time. With the help of e-bot, businesses can increase the effectiveness of their customer care operations by incorporating artificial intelligence into a variety of channels and automating client-facing conversations.
Where in your stack do you use Haskell?
The company consists of multiple independent teams, each using its preferred tech stack.
One of the central components of our product is the Conversational Engine. It determines the actions that a bot takes based on the input it gets. It’s at the heart of each bot and calls on other services to get context and perform actions, e.g. interacting with APIs or databases. To deal with natural language, it calls on the internal NLU service (written in Python) that adds structured context and attributes to the raw input.
The team developing Conversational Engine uses Haskell for the backend and PureScript for the frontend. The frontend is a pretty interface, where customers can visually create bot logic by making a graph.
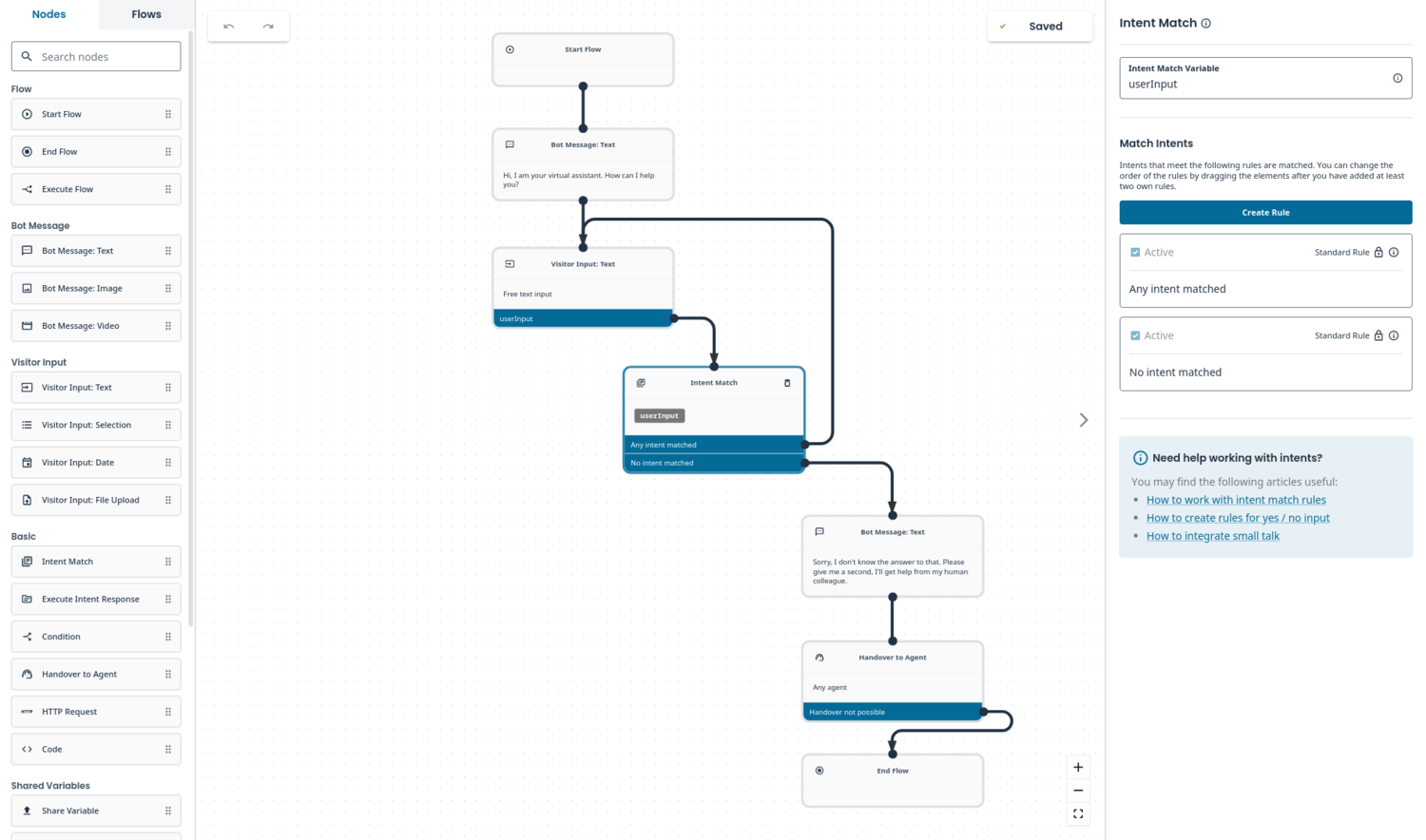
The created graph is sent to the backend, which transpiles it into Ebotlang (an internal language also written in Haskell). When somebody has an actual conversation in a chat, it’s also interpreted by the Haskell backend.
Why did you decide to choose Haskell for the project?
Since the Conversational Engine is such a central component of our application, we want to put it on a strong foundation. The layers that are built on top of that can be quite brittle and unpredictable (external APIs, AI model output, human programming/configuration of the bot itself). Haskell’s properties give us confidence that this base layer is as robust and deterministic as it can be.
While being such a central part of our stack, at the same time, the scope of this Conversational Engine is relatively clearly bounded. This made the decision to go with Haskell a bit easier since we knew that any potential drawbacks would be limited to this scope.
Are there any specific qualities of Haskell that make it valuable for your use cases?
The obvious ones: the type system and purity give us confidence in the code we write. These qualities would serve any use case well, but in our case, we specifically wanted to optimize for that, even at the cost of potential downsides.
We want to provide robust tools to our clients – after they build and launch a bot, it should not blow up at runtime and should run without incidents or bugs. Live bots can’t be easily updated in the middle of the conversation, so they should be correct and stable when constructed. It’s a meme that once Haskell code is deployed, it is stable, but there is truth to it, and it’s a nice guarantee.
We used JavaScript before; it worked as a prototype, but it didn’t scale. We had the opposite experience with Haskell. The initial phase was harder, but we can easily extend the functionality without breaking what we have.
On top of that, we have to deal with the complex logic of a conversation. And Haskell is a perfect fit for implementing domain-specific languages (DSLs). And if you take it one step further, you can smoothly write and use your own programming language.
How did you end up creating your own language? Does Haskell support developers in creating their own languages for domain-specific purposes?
If you want to model natural conversations between humans and machines, you have to overcome a few hurdles. You need to extract meaning from the text and provide it to the machine in a structured way (using Natural Language Understanding), you need to be able to follow complex threads, you need to talk to various other systems, and all the interaction happens asynchronously. Users may reply immediately, or they may reply the next day.
We decided to offer our customers a domain-specific language in order to abstract away the underlying mechanics and focus on programming conversational flows as naturally as possible. Limiting the possible functions that a bot can perform allows us to better reason about failure modes and be more confident that each bot will function as expected.
As we’ve previously noted, Haskell offers excellent tools for building custom languages. Writing the implementation is similar to drafting a specification. The first is Alex for lexing and Happy for parsing, both of which are suitable for your own domain-specific language. The language we developed is statically type-checked to find errors and inconsistencies before running the bots. The well-known Hindley-Milner type system is the foundation for our custom type checker implementation. Additionally, the language has other features like optional type annotations, pattern matching, and sum types. Even though it was a sizable project to work on, it was enjoyable and ended up offering several advantages, such as allowing a continuous increase in functionality.
Did you run into any downsides of Haskell while developing the project? If so, could you describe those?
Haskell is among the less commonly used languages, and therefore there are fewer libraries and tools available. The ones that are available are often less mature than their counterparts in the most popular languages. In contrast to Haskell, where you are often lucky to find a library at all, other languages often have multiple options to choose from.
It hurts the most when it comes to integration with other teams. While they can just plug-and-play any fancy technology (more or less battle-tested solutions that work out of the box), we have to either write from scratch or tweak existing libraries to serve our purposes. For instance, integrating with Kafka, Confluent Schema Registry, and OpenTelemetry with Jaeger.
There are some other smaller things that seem annoying at first, but take only a couple of days to figure out – for example, dealing with records or setting up a development environment. In either case, things got a lot better in the last couple of years.
How do you deploy your Haskell code? Have you encountered any problems?
Our current production stack, which is built utilizing AWS Lambda, DynamoDB, and CloudFormation, is performing admirably for us. Without experiencing any difficulties or disruptions, we were able to go from zero users to one user to the vast majority of users. One significant danger exists in this situation: if you wish to switch cloud providers, vendor lock-in could make the process more difficult.
The use of automation is crucial for releasing and deploying. This has been effectively automated using GitHub Actions. One of the problems we had, aside from the necessary tweaking to the cache and compile times of continuous integration, was exceeding the 7 GB GitHub-specific memory limit. We changed the modularization of part of the code base in order to reduce memory usage and avoid running on self-hosted instances.
Could you list some Haskell libraries that your team found very useful while working on the project and that you would like to feature?
In the core of our app, we use aws-lambda-haskell-runtime in combination with servant to implement a web application based on AWS Lambda. Servant allows us to write type-safe REST APIs, and servant-docs guarantees that our documentation is never stale.
We use amazonka for AWS and hw-kafka-client to talk to the external world via Kafka.
Golden tests, also known as snapshot tests, help us ensure that updates do not break existing functionality or bots. So we use hspec-golden and property-based testing with the help of QuickCheck.
And when reality kicked in, we started using hpc-lcov for tracking code coverage, licensor for tracking licenses, tracing for distributed Zipkin traces, and katip for tracking bugs and logging errors with structured context.
Did your team run into any difficulties with hiring Haskell developers?
In general, hiring good developers is difficult, regardless of programming language. With Haskell, there is a smaller pool of them compared to Python or Java, so that makes it difficult to hire many in a short timeframe. However, what we’ve seen is that among the population of people who apply for Haskell jobs, there is a much higher representation of some qualities that we value highly. Most programmers don’t just stumble into writing Haskell code; they seek it out because they care deeply about the quality of their code and are enthusiastic about what they do. With that usually comes an above-average knowledge of programming concepts in general.
You also use PureScript. How well does it synergize with Haskell on the backend, and would you recommend it as the frontend language of choice for other Haskell teams?
An early version of the graph editor was implemented in TypeScript. The team looked into PureScript because the developers were already using Haskell on the backend and were familiar with functional programming.
A functional approach to working with the state plus prior Elm and Redux experience made the move simple. Roughly speaking, PureScript just differs in syntax, while FFI allows interfacing with the JavaScript environment without starting from scratch. Easy integration with existing libraries and JavaScript – specifically the React ecosystem – was one of the main advantages of choosing PureScript over Elm and a joy to work with. In comparison to TypeScript, the PureScript language offers a more powerful type system and more functional programming language features. Because of this, PureScript is a great fit for our team and application. It also gave us the chance to benefit from good tooling, connect with other helpful enthusiasts, and contribute to the PureScript ecosystem.
Although it is feasible to attempt to use code generation between the front end and the back end, it turned out not to be a significant problem to tackle in our project. It wasn’t one of our pain points because our APIs are relatively small and we have end-to-end tests. For instance, PureScript and Haskell libraries’ default JSON encoder and decoder instances were highly compatible.
Thanks to Max and Andreas for sharing their experience!
If you would like to read more interviews like these, check out our Haskell in Production post series. And don’t forget to follow us on Twitter or subscribe to receive articles in your email via the form below.
As a Haskell IT agency, Serokell offers comprehensive services that include blockchain development, data analysis tools, fintech applications, and more. Contact us today to discuss the solution you need.



.jpg)
.jpg)
.jpg)
.jpg)