
Dr. Varun Ojha is a lecturer in computer science at the University of Reading, United Kingdom. Previously, he worked as a postdoctoral researcher at the public research university ETH Zürich in Switzerland and as a Marie Curie Fellow at the Technical University of Ostrava, Czech Republic. Since 2010, his research has been focused on artificial intelligence, specifically: neural networks, deep learning, and computer vision. He is also working on optimization techniques in data science.
In this interview, Dr. Varun Ojha shares theoretical insights and practical recommendations from his work. We discusss topics like best strategies for training neural networks, overfitting, and open-source datasets.
Interview with Dr. Varun Ojha
What projects are you working on right now?
I specialize in algorithms called neural trees. These algorithms simultaneously solve feature engineering and function approximation tasks. I also work on adversarial robust deep learning, investigating how deep learning could be made secure from adversarial attack. Adversarial attack means an input to a machine learning model that causes it to fail. For example, a model was designed to recognise cars. If you change a few pixels in the image, the car may be identified as a different object. How to make such a model robust and viable? Many researchers are now trying to solve this problem.
My neural networks research is mostly theoretical. Recently, I have been working on a sparse neural tree algorithm called backpropagation neural tree that can be used to efficiently solve machine learning problems, such as classification, regression, and pattern recognition. But despite being theoretical, this research has immediate applications in the real world.
What is your technology stack? Which languages, frameworks, and libraries do you use most often?
I program in Java. But in my field, Python is the most used programming language. Therefore, I now also work on Python programming as this has become the language of machine learning, mainly due to libraries like Keras, TensorFlow and PyTorch. To my students, I often recommend PyTorch as it is easy to use and effective.
What are the most important trends in the neural networks domain today? What are the biggest problems scientists are trying to solve?
Two biggest challenges right now are natural language processing and computer vision.
One of the research problems is the cost of training algorithms. For example, in natural language processing the largest network is GPT-3, which has more than 175 billion parameters. Training networks can cost $10 million to $20 million, which only big companies can afford. These companies train networks for specific tasks like scene recognition and make them available for ordinary researchers to apply them to their work. I used one such pre-trained network in my recent research on flood monitoring, in which I was training algorithms to distinguish between a flooding scenario and a non-flooding scenario.
What are the datasets you are experimenting with? Which of them would you recommend and why?
I generally use the so-called benchmark/state-of-the-art image recognition datasets: MNIST, CIFAR10, ImageNet, COOC, Cityscapes, and KITTI. They are open-source datasets, and more databases with free access can be found on popular web pages like Papers With Code and Kaggle.
For a self-collected dataset that needs to be stored independently, I generally use cloud storage or storage provided by the university. But for projects where we need to train ML models on Amazon Web Services (AWS), we store a dataset there. For some projects, I use Google Collab Pro. Some of my students also use NVIDIA DIGITS.
The choice of the data set depends on the task. Since my research is focused on image classification and the improvement of algorithms, I use CIFAR10 and ImageNet more often. I normally work with 3-4 datasets simultaneously to compare the performance of my algorithms.
How do you choose the NN structure and determine the optimal number of layers in it?
Choosing an NN structure is the most critical problem in NN-based research. There is no straightforward answer to this question. Let me walk you through some basic steps one would take when choosing a deep neural network structure.
At a very fundamental level, the input and output layers depend on the problem you are trying to solve. For example, for an image classification problem, your first layer is typically a 2D/3D convolutional layer. The last one is a dense layer (fully connected layer) with the number of nodes at the output layer equal to the number of classes in the dataset. The last layer for object segmentation tasks is the 2D/3D convolutional layer as we need to segment the parts of the images themselves.
Apart from these, a deep neural network has several types of layers: convolutional, pooling, batch normalization, dropout, and dense/FC layers.

Each also has the choice of the number of kernels/neurons. Here, depth and width are directly proportional to the number of parameters in models, meaning the larger the parameter, the longer is the training time and the higher the training cost. Also, the model complexity and inference time (speed of model prediction on single input during test scenario) will increase as you go for larger parameters. Thus there are trade-offs between the model training cost/time/complexity/explainability and the accuracy you want to achieve.
There are expansive hyperparameter optimization techniques where you can use methods like Bayesian optimization, reinforcement learning algorithms, and gradient-based neural architecture search to determine the right NN architecture.
On the shallow neural network side, I, however, worked on a special class neural network called neural trees, where the optimization of network architecture is done by genetic programming. In some of my recent research, “Backpropagation Neural Tree” I found that “any stochastic gradient descent training of any apriori sparse ‘arbitrarily thinned’ neural network would perform a better or equivalent degree of accuracy compared to a symmetric fully connected neural network.” In fact, I found that only 14% of NN and backpropagation neural tree parameters are able to solve classification problems with a high degree of accuracy.
This suggests that one needs to be careful about the complexity of the model. In machine learning, the lower the complexity, the better the generalization ability of a model is.
How would you recommend practitioners who do not have much experience with this to select hyperparameters?
You have to decide whether you want to use a complex or a simple model and experimentally test where the error can be minimal. Let’s say you are dealing with an image processing task.
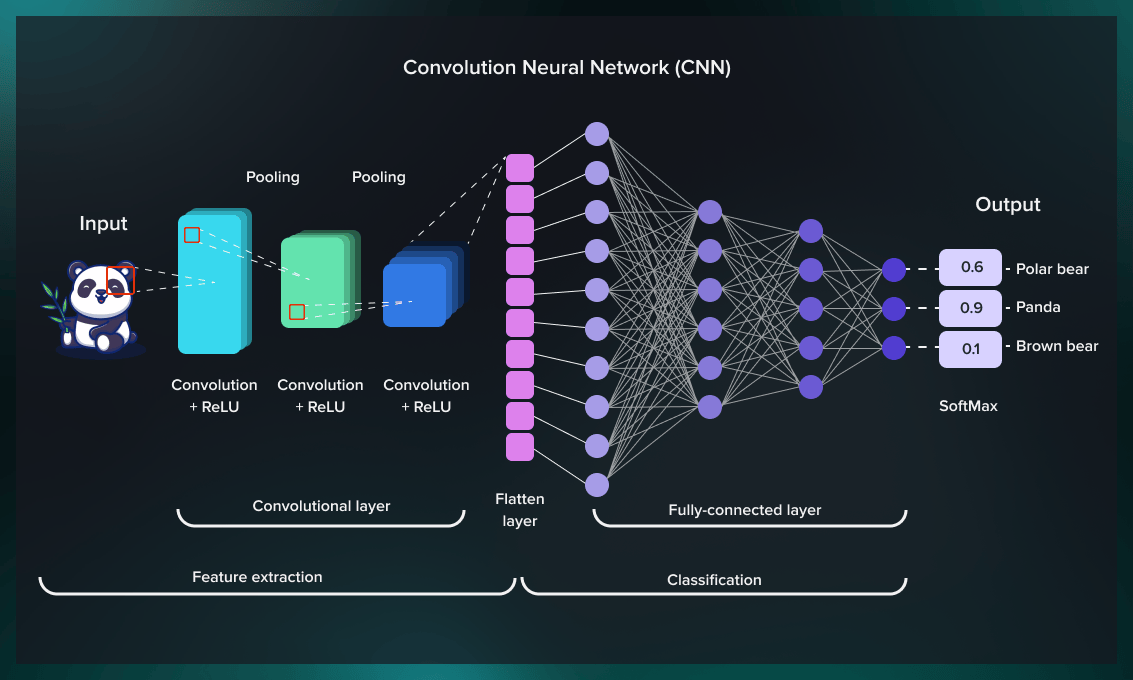
Once the first layer is fixed, as you have a dataset, and use the digital version of the image as your input layer. Then you do the convolutional layer. After you are done with that, you proceed to the flatten layer, and finally, to the resulting layer. This way, you build your basic NN architecture, test the performance, and then improve it by incrementally adding layers and changing hyperparameters such as the number of kernels. If you see that the performance is not good enough, you can add more layers and see where it is going. If it is eventually getting worse, try to reduce the amount of added layers. So it is always an experimental way. At this point, we don’t have any rule of thumb as to how to choose hyperparameters. In some of our recent work, we tried analysing the sensitivity of deep learning hyperparameters.
What are the criteria for balancing the size of the NN, the methods used, and the cost?
As I said before, the training cost (time and money) and model size of NNs are trade-offs that one needs to be careful of. The main criterion is how well an NN model can predict things. Hence, the test accuracy (i.e., accuracy on unseen datasets) is the driving force in all large models we discussed.
However, pre-trained models are getting more and more popular. Therefore, the NN model size in many cases may not be as problematic as training a NN from scratch. For both NLP and Vision tasks, there are pre-trained models that can be applied and fine-tuned or re-designed for their particular data set. Here, one needs to be careful about the task relatedness when choosing the pre-trained NN models. For instance, if the task is generic object recognition, an NN model like YOLO or Mask-RCNN trained on the COCO stuff dataset would be the user’s choice.
So a researcher has to find that balance by means of experiment. Can you give some more practical recommendations for the preliminary estimate?
Let’s say you are using ImageNet. It is a huge dataset with millions of images that is hard for an ordinary researcher to get through, even with a simple model. But today you have access to GPUs or cloud services like Google Collab. Google Collab offers you free or sometimes very cheap calculations for 24 hours. So you can estimate whether this kind of dataset can be trained within 24 hours or not. Accordingly, you set the number of epochs. This way, you can first test your algorithm with a small number of iterations and observe the progress of your test training and validation loss. Then, if you see that both are fine, you can, for example, set 100 epochs and train that dataset overnight. And of course, the cost also depends on the size of the network. I do not recommend using networks with billions of parameters because there are already a large number of state-of-the-art algorithms that one can use for their applications.
How do you address the issue of overfitting? Can you share any practical tips?
Overfitting can be addressed by techniques like “early-stopping” and regularizing the NN during the training. Early stopping checks the NN training performance in comparison to the NN validation performance at any given point in time. If the NN validation performance on the unseen data starts showing worse results from a certain point, we stop the NN training and fall back to the previous best state.
In addition to early stopping, the use of weight regularization and dropout layers are effective in controlling overfitting. Start with relatively small base models when making a deep NN model architecture. Then add layers iteratively using either the grid search technique or one of the hyperparameter optimization methods we discussed earlier.
Do you work with real-time object recognition? Could you share the latest trends? What works better than YOLO today?
I have used some of the detectors (deep neural networks for object detection) like Mask-RCNN and YOLO pre-trained networks for some projects like waste-water bottle detection in a video and measuring speed and tracking boat in a boat race. For some other projects like recognition of water levels for flood prediction, I have used image segmentation R-CNN family of algorithms. We achieve pretty high accuracy (about 94%) in detecting real-flood events.
There are many versions of these two detectors like Faster R-CNN and YOLOv5. RetinaNet is also a very efficient object detection algorithm currently in use.
For object detection, each algorithm has its own pros and cons. For instance, the R-CNN family of object detection has a slower inference time than the YOLO family for real-time detection. However, when real-time detection is not a constraint, then the R-CNN family can give higher efficiency in detecting objects. There are also some libraries, like Detectron2, developed by the Facebook team, that support R-CNN-like algorithms for object detection.
The process behind NNs is a black box. How can a researcher explain the result to business? Have you developed your own system to evaluate the results?
Indeed, the black-box nature of neural networks is a big issue. This is opposed to a popular machine learning algorithm called a decision tree that is a kind of explainable machine learning. The NN fundamental design is first to mix several weighted input features and, second, to transform that into another feature using a nonlinear transformation. This weighted mixing and nonlinear transformation using activation function layer by layer are largely attributed to making NN a black box.
The explainability of NN is a challenging research domain. When it comes to image recognition, we can observe the behavior of the algorithm in each iteration. For convolutional deep neural networks, one can examine a feature map of the convolutional layer to visually find, for a given input, which kernel/part of the NN process and which part of an input image are responsible for a prediction. For example, if you input an image of a car into this NN, which NN parts process wheels, windshield, shape of car etc., can be examined.
To explain neural networks, we might use visualization of layer-wise feature relevance propagation, understanding feature interaction, i.e., one can try to understand for what inputs an NN behaves in what ways or how much its accuracy varies for perturbing input features, and what parts of an image an NN gives most attention to.
As I said, I work on algorithms called neural trees. These are a type of neural network where neural tree decisions on given inputs propagate through particular branches of the tree, making explainability intrinsic to this class of neural information processing algorithms. You can check my work on Backpropagation Neural Tree, published in Neural Networks (2022) for a deeper look.
What are your future research plans? What would you like to explore?
I will continue to work on neural networks, and my goal is to develop explainable algorithms. As we discussed, the lack of explainability is a big problem in this area.
I’m also working on how the training cost could be reduced. Overall, it is about understanding NNs better. My ambition is to develop efficient neural network algorithms inspired by neuroscience, i.e. modeled after the neurons in the human brain. I find that very exciting.
Can you recommend a few NN resources for our readers?
- For neural networks, I would recommend ICLR and NeurIPS.
- ICML is a great source to follow the latest developments in machine learning.
- For computer vision and pattern recognition, I would advise CVPR.
Serokell has broad expertise in building and using neural networks for developing fintech and blockchain solutions, edtech platforms, and much more. If you have an idea that needs to be realized or a problem to solve, contact us today! We are here to help.

_(1).jpg)
_(1).jpg)
.jpg)
.jpg)

