
In modern blockchains, if some node wants to verify a block, it either has to be a full node storing the whole network state, or it has to continuously ask some remote storage for various parts of it. Each of these solutions possesses either inconveniences (storing 100+ GB of data) or risks (the storage forging the data it sends you).
I present a proper solution for a light client which can validate blocks - an AVL+ tree. Instead of storing N pieces of data, it requires the client to store 1 hash (which uniquely identifies state) and receive a log(N)-sized proof along with each transaction or block. The client can verify that the proof was generated from the same state the client root hash refers to. This enables the implementation of a verifying light client on smartphones and other devices that are incapable of storing the full state.
What is an AVL+ tree?
AVL+ tree is a map between keys and values. It enables proving of operations that are performed on it. The proof itself is the only thing anyone needs to replay the operation and end with the same result as you, essentially verifying that you did not cheat.
Each AVL+ tree has a unique root hash. If the hash is cryptographic enough, you can view it as a “name” for that particular state of a tree. That means, you can send a provable operation as follows: (operation, proof, endHash), where endHash is the root hash you ended with.
“AVL” is an abbreviation of the names of its inventors: Georgy Adelson-Velsky and Evgenii Landis.
What has “melting” to do with it?
The tree from implementation is kept in memory only partially; you can force it to “melt” into the underlying storage at will. It will materialize gradually, only the nodes that are actually needed for the operation.
How can it be used?
It can be used in blockchains to reduce the amount of data (stored on the client) you need to verify a transaction to a single hash.
However, it increases the weight of the transaction, as each object to be proven carries O(log(N))-sized data, where N is the count of keys in the map.
Development history
If you get bored at any time, go to the next section. It contains most of the technical details, compressed.
At first, I was given the task to construct an AVL+ tree. It essentially is an AVL tree, which is, in turn, a balanced binary tree which stores its keys and values in leaf nodes and only technical data in branches. The “+” means that each node has its hash computed and is stored inside it, and the hash of the node depends on the hashes of both child nodes. By induction, this means that any change of any node in the tree will change root hash, thus - and by properties of hashes - proving that root hash identifies the state.
For those interested - the hash itself, which is stored inside the node, cannot be used inside its own computation. The user of the tree selects the hashing algorithm, and there is a protection layer which prevents the situation entirely.
With the help of our theory specialist, we found out that we cannot simply store the height of each node in each subtree as that would require us to access both child nodes when checking the balance, inducing inefficiency. Instead, we decided to store the height difference - or how I called it - tilt. The tilt of any node from a balanced tree can only be from the set [-1, 0, 1].
I was also told that the tree should generate proof on each operation (insert, delete, or even lookup). We needed to somehow include the preceding and succeeding key into the proof, so that the receiver, for the deletion of an absent key, can check if the key was really absent by looking at the surrounding keys.
Proofs (in all the sources I read) were the “hash chains” + the modified leaf node. So, if you change some node, the proof would look like this:
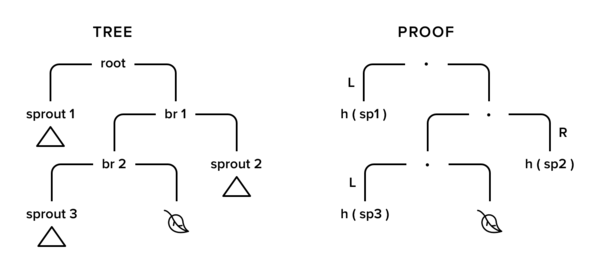
In this image, the only path to leaf we have changed was drawn, so we leave details of subtrees sprout1-3. The only things we need from them are their hashes.
The proof from the picture above is represented as
( [ (sprout1, L, info1)
, (sprout2, R, info1)
, (sprout3, L, info1)
]
, leafBefore
, newHash
)
where info1-3 are rest of the technical pieces of data from the node.
First, you need to prove it refers to the same root hash you have. For that, you have to do the following:
oldHash’ = foldr recomputeHash (hash leafBefore)
[ (sprout1Hash, L, info1)
, (sprout2Hash, R, info2)
, (sprout3Hash, L, info3)
]
where
recomputeHash (sideHash, _, info) rightHash = hash(sideHash + hash info + rightHash)
Then you have to check if the oldHash’ you get from that computation is the same hash you are holding. This action will prove that this proof is referring to the same tree as your root hash. Then you perform an operation on the leaf on that proof and recompute the hash of it, which should be equal newHash. If it is, the operation is considered proven.
The first thing that struck me was that the proof looks a lot like the tree itself. Should I write all the operations twice - for the tree and the proof - or should I write them once and reuse? At that moment, the first difference was born between my implementation and what is typically described in articles - my proof is a tree with uninteresting elements pruned. I added a tree state to my ADT: | Pruned hash.
There was another problem. At the time, I stored the surrounding keys inside each leaf node because some implementations did that (they claimed that this raises the verifiability level). This implied that after each mutation I needed to go to both of the neighboring keys to fix their next and previous key. The recursive insert didn’t look like it would pull that off and not become a complete mess.
So, I decided to use a zipper to navigate the tree freely.
Zipper is a “functional iterator” which can go up and down into subtrees inside a recursive tree-like structure and batch local modifications. When you exit the zipper, all changes are applied.
Zipper gave me descentLeft/Right (to go to child nodes), up (to go to a parent node, applying all local changes and maybe rehash) and change (perform a local modification, schedule a node to be rehashed) operations.
This was a huge change. The zipper actually let me call rebalance only in the up operation, which isolated the rebalance and made it possible for me to forget about the issue in all other cases. Rebalance was only called in an up operation if the source node (or any of its transitive children) was changed.
Since my proofs were the same trees (but cut), I had to collect them somehow. I thought about collecting the cut tree while traversing full one, but that looked hard. So I split the task in two.
First, I collected hashes of nodes I’ve touched during an operation. Even if I just read the node - the read operation has to be proven, too. After I ended the zipper traversal, I fed the node hashes collected and an old tree into a pruner, which cut away any subtrees I didn’t touch, producing a proof.
So, now you don’t have to run different insert on the proof - you just get your tree from it and run the same insert you do on a full tree.
This also allows proving any batch of consecutive operations with a single proof, by computing union of their sets of node hashes and feeding the result to pruner.
Pruning is just a recursive descent into the tree that for each node checks if that is in the “interesting” set. If it is, it’s kept and its children are traversed; if it’s not, it’s replaced with Pruned itsHash and the algorithm doesn’t descend further. The result of pruning is called a Proof.
So, in the end, I was able to write insert, delete, and lookup as simple operations without any care for rebalance and (almost) no care for proofs.
The usage in the Disciplina project
I was discussing it with our tech lead, and he got an idea to partially store the tree inside a kv-database, not materialize the full tree. He also proposed the usage of Free monad, instead of the Fix-plumbing that I had at the time. That went well, and I ended with a simple interface for the underlying monad of store and retrieve actions - representing some plain KV-database holding the (hash, treeNode) pairs. The Pruned constructor was replaced with the Pure one from Free monad. I wrote a loader in the Internal layer, which only materialized nodes you need. I also made a save operation, which synchronized the tree with the DB returning its dematerialized version. This enabled the “melting” and gradual “solidification” of the tree into/from the database.
During the time we plugged in rocksdb as storage underneath the AVL+, a feature was added: storing in and restoring current root from the storage, as well as two variants of tree save: append and overwrite.
The append worked by writing the tree along with any other tree contained in the database and then changing root pointer to the new one. This made possible of loading up any previous state of the tree from the same storage. The overwrite operation attempted to remove the unshared part of the previous tree (pointed on by the root ptr) before storing diverged nodes of the current one.
In the next incursion, I removed the “next” and “previous” keys from leaves. The reason was - we can just navigate to them deterministically while doing lookup/insert/delete, there’s no need to store their keys and complicate things by updating those keys every time.
One problem I had before was now solved properly - when multiple operations on the same node were done, for each of them the node hash was recalculated. The cryptographic computations are heavy, so there was a need to reduce the load.
The solution was tricky - I made the hashes lazy (we had StrictData language extension applied). That way, the hash will be calculated on request, and only for the last version of the tree. It does increase the memory consumption to +1 thunk per node, but other changes from that patch (-2 keys (next/prev) and -1 Integer per node) are a good compensation for that.
A small improvement in node change tracking was made: instead of comparing a node hash with its previous state - stored in a descent stack - I introduced a boolean isDirty “variable” (within the zipper state). That caused some spurious test failures, which occurred 10% of the time, to just disappear.
Current state of the art
For an extremely large state, implementation supports for the tree to be only partially materialized in memory.
The proof can be generated from and applied to any sequence of changes - to the transaction or the whole block.
To prove the block, a client doesn’t need to communicate with the source of the block or any holder of the full state, all data required for the verification is contained within a proof.
The special storage to plug in while you prove is included in the same package.
The “materialized” and “non-materialized” states are indistinguishable from the user and operation standpoint. You just have a Map hash key value and do things on it. It can be compared for equality with another tree, even if key and value types aren’t supporting equality comparison.
For the operations, it supports insert, delete, lookup, lookupMany, and fold[If] actions. Each of them returns: a result, a new tree, and a nodeset. (Yes, lookup returns a new tree as well. The tree, where the visited nodes are materialized.) You then join all the nodesets and prune them against the initial tree; this gives you a proof which can be used to rerun the same operations on some other client (including a light one) to prove the changes you’ve made before.
The current tree can be stored in the storage via append or overwrite and then restored via currentRoot, which is an O(1) operation returning the tree in a non-materialized way.
The tree, with some operations performed, acts as a cache, synchronizing with the storage on append and overwrite - but the usage of overwrite requires an external lock. You can also just throw the tree out, disposing of any changes you’ve made.
The hidden zipper layer takes care of rebalancing and proof collection. Although you still need to at least visit the nodes you want for them to end in a proof, this is not a problem: visiting is a part of the domain operation.
Conclusion
I have presented a solution to the problem that can be used in blockchains to make light clients that can validate a block without holding the full state or making additional requests to the server. The tree itself can be safely stored elsewhere, due to its storage scheme, thus eliminating the problems of another way of light client implementation. The tree is also capable of working with a state that doesn’t fit into the memory.

.jpg)



.jpg)
