
The most popular solutions for storing data today are data warehouses, data lakes, and data lakehouses. This post gives a detailed overview of these storage options and their pros and cons for specific purposes.
What is a data warehouse?
A data warehouse (often abbreviated as DWH or DW) is a structured repository of data collected and filtered for specific tasks. It integrates relevant data from internal and external sources like ERP and CRM systems, websites, social media, and mobile applications.
Before the data is loaded into the warehousing storage, it should be transformed and cleansed so it can be used for analysis. The data that is not relevant for a particular case gets discarded.
Data warehouses often combine relational data sets from multiple sources, such as user preferences, business reports, and transactional data to aggregate historical information. While the database stores current information – “what’s happening here and now” – the data warehouse can store other historical slices of the same database.
However, the primary purpose of data warehouses is to store meta information. For example, this could be indicators such as the PNL of a particular customer group over the entire business history represented by a graph. Dozens of different parameters, some of which are quite complicated, can be tracked and instantly retrieved from the outside for analysis purposes.
The data warehouse rarely contains freshly updated data. It always lags behind the included databases and only has old data stamps (the only exception is some calculated indicators that require fresh updating). So, in a sense, the data warehouse is more of a place for reserve copies of the databases.
A well-designed data warehouse can improve business operational efficiency by allowing users to quickly access historical information on key business metrics. Data engineers and analysts can extract data from data warehouses using SQL clients, business intelligence tools, and other applications.
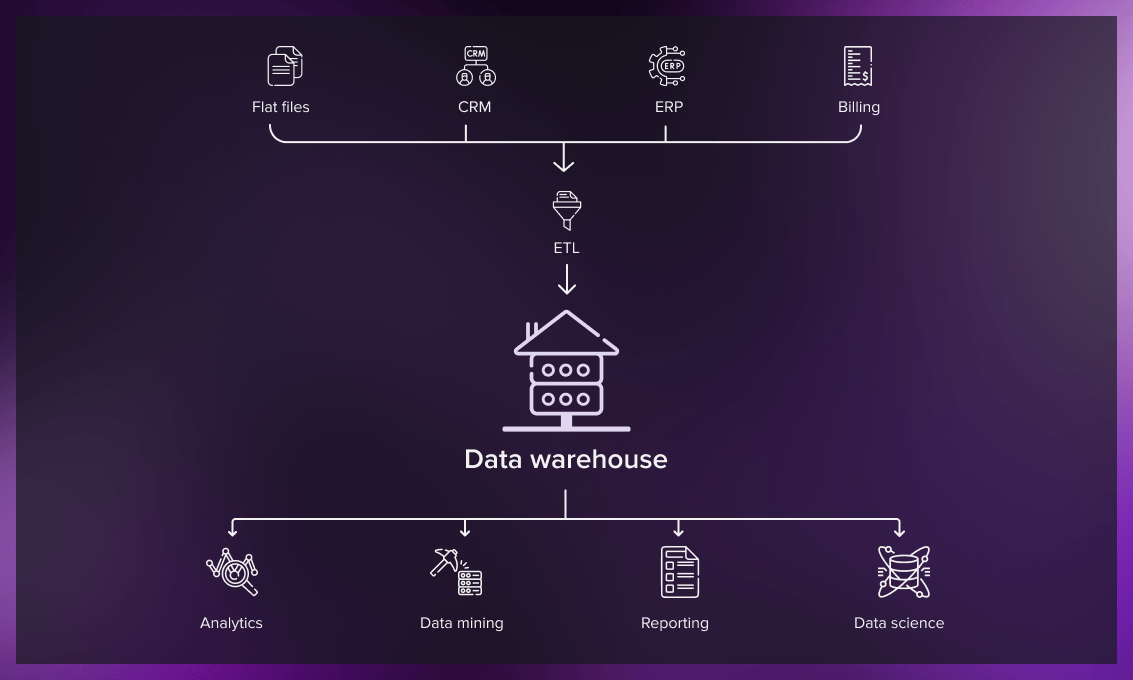
Pros and cons of data warehouses
Pros
The overall benefit of using a data warehouse is improved reporting and analysis capabilities.
Data standardization
Organizations generate large volumes of sales, behavioral, transactional and other data and collect it from various heterogeneous sources. Standardized, integrated data makes it easier for researchers to navigate and work with it.
Improved decision-making
By providing access to all organization’s data in one place, a data warehouse can help improve both strategic and tactical decision making. It enables businesses and scientists to analyze historical key metrics and research results.
For example, by looking at historical trends in customer purchases, managers can make more informed decisions about where to focus their efforts when it’s time to expand offerings or introduce new products or services. Researchers, for their part, can have historical data pertaining to experiments.
Increased efficiency
Data warehousing reduces the time employees spend gathering information and frees time for analysis, which, consequently, leads to improved productivity.
Cons
There are two major drawbacks that can make the use of data warehouses challenging.
Lack of flexibility
Data warehouses work well with structured data but aren’t meant to work with unstructured data, such as social media and streaming data or log analytics.
Сompatability issues
Data warehouses can combine several databases, which may contain different measurements (for example, miles per hour vs. meters per second) or several titles denoting the same data type (females and males vs. women and men). In some cases, the integrated data may not contain all required fields ( e.g. the respondents’ age). All these instances pose compatibility problems.
High costs
The data warehouse requires costly preparation of data. Besides, the more historical data it contains, the more expensive it becomes to maintain.
Security concerns
When it comes to research and commercial data, such storages are of particular interest to hackers. This increases the requirements for the system’s reliability, the storage’s resistance to hacker attacks, and the protection against information leakage.
The table below provides a quick overview of DWH’s advantages and disadvantages.
| Pros | Cons |
| Improved reporting | Compatibility problems |
| High quality of data | High maintenance costs |
| Data integration | Not flexible |
| Optimized search and fast response to queries | Security issues |
What is a data lake?
A data lake (DL) is an extensive centralized collection of unprocessed data, the purpose of which is yet undefined. For example, it could contain clickstream and real-time data. Data lakes are simple to maintain but require expert knowledge to extract necessary figures.
Since data lakes store huge amounts of raw data, they enable comprehensive analysis of big and small data from a single location. This makes data lakes suitable for investigations and verification of new hypotheses.
Data is extracted, loaded, and transformed (ELT) at the moment when it is necessary for analysis purposes. Thus, you don’t need to incorporate clickstream data into a relational database. This allows researchers to use historical data in its original form long after it was inputted.
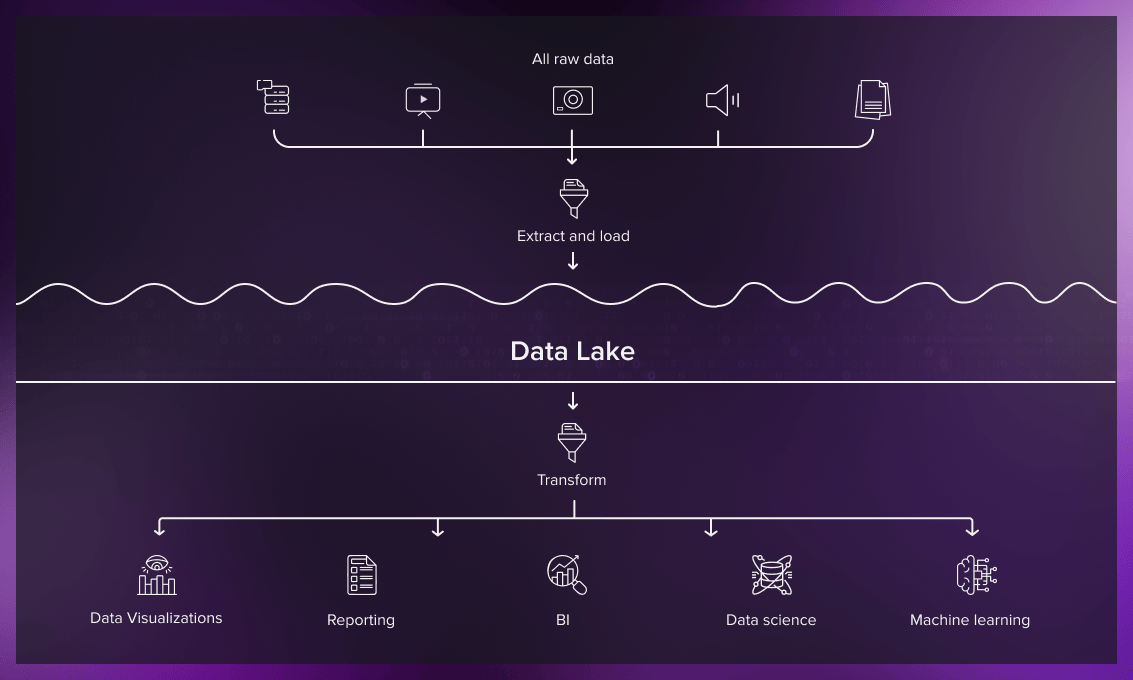
Pros and cons of data lakes
Pros
Flexibility
Data lakes allow you to store data in any format and keep it in its original form, which enables you to benefit from it in the future for new use cases.
Consolidated data
Data lakes can contain both structured and unstructured data and provide a central location to store all types of data.
Cost-efficiency
Since data lakes do not require data structuring, they are considerably less expensive to maintain than data warehouses.
Cons
Poor support of BI cases
Integration with business intelligence and analytics tools can be difficult if data lakes are not properly managed. In addition, query results may be not accurate due to the lack of consistent data structures.
Insufficient data security
Due to the lack of data consistency, it is hard to develop appropriate data security measures for handling sensitive information.
The table below sums up data lakes pros and cons.
| Pros | Cons |
| Data from multiple sources is stored in a raw form and in one place | Unstructured data storage demands more time and effort to retrieve information from it |
| Flexibility: can be schema-free or have multiple schemas | Non-standard formats may need to be reformatted manually |
| Versatility: can store multi-structured data (logs, multimedia, sensor data, chat, etc.) | Does not guaranty data integrity and representativity |
Watch this video comparing data lakes and data warehouses to better understand how they differ.
What is a data lakehouse?
As the name suggests, data lakehouse combines the best elements of data lakes and data warehouses. It’s a new type of big data storage architecture for organized, semi-structured, and/or unstructured data. Data can be stored in a single location and is suitable for ML and BI, as well as data streaming. In data lakehouses, data warehouse-like structures and schemas can be used for unstructured data like in a data lake.
Data lakes of all types are usually the starting point for data lakehouses.
Data lakehouse architecture
The data lakehouse has a layer design, with a warehouse layer on top of a data lake. This architecture, which enables combining structured and unstructured data, makes it efficient for business intelligence and business analysis.
A data lakehouse system usually consists of the following layers:
- Ingestion
- Storage
- Metadata
- API
- Consumption
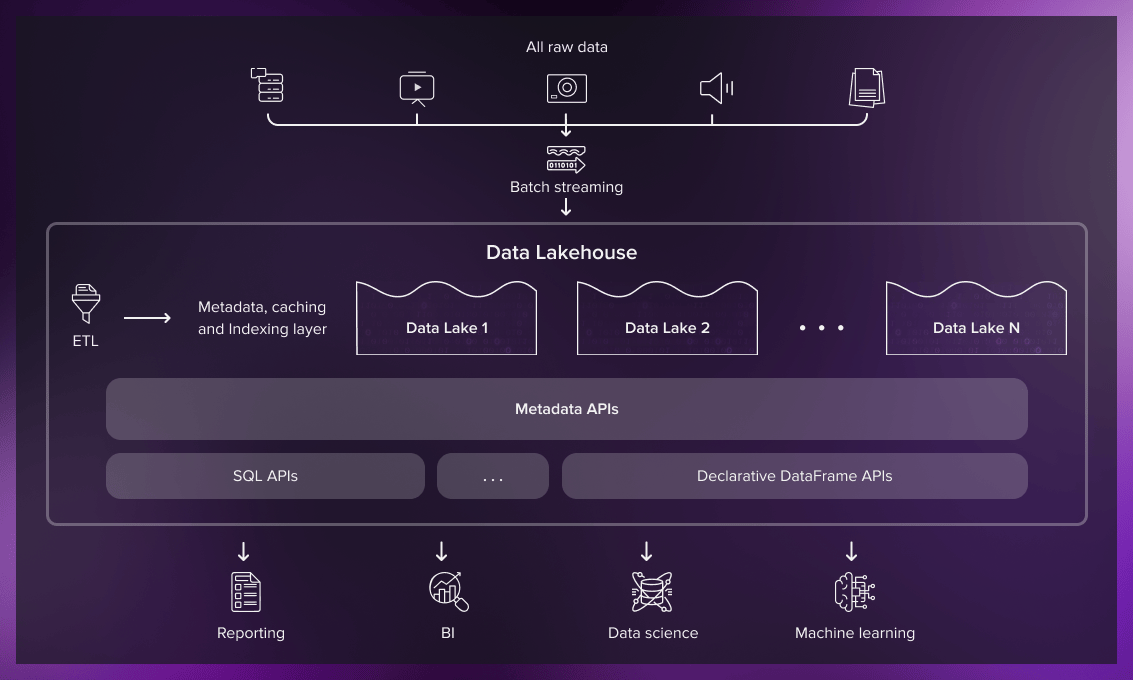
Ingestion layer
The first layer is responsible for collecting data from multiple sources and delivering it to the storage layer. For that, batch and streaming methods are used.
Storage layer
The data lakehouse design allows you to keep different types of data as objects in low-cost object stores like AWS S3. The client tools then can read these objects directly from the store using open file formats.
Metadata layer
The metadata layer is a joint catalog that provides metadata (data describing other data) for all objects stored in a data lake and allows users to apply management features, including ACID transactions, cache, indexing, and data extraction.
API layer
The API layer contains various APIs that allow all end users to process tasks faster and have access to the data necessary for advanced analytics.
Data consumption layer
Numerous tools and applications such as Tableau and Power BI are housed in the consumption layer. Lakehouse architecture makes all metadata and all data stored in a lake accessible to client applications. All users in the company can utilize the data lakehouse for all types of analytics tasks. These include creating business intelligence dashboards and running SQL queries and machine learning tasks.
Data lakehouses might use intelligent metadata layers. These layers act as an intermediary between the user and unstructured data, which can be organized by extracting features from it.
Pros and cons of data lakehouses
Pros
Low cost
By providing a single tier for all types of data, data lakehouses offer a more cost-effective storage solution as teams only have to manage a single data source.
Decreased data duplication
Data lakehouses provide a single multi-purpose data storage platform that can meet all business needs, reducing data duplication.
Openness
Data lakehouses allow access to data using any tool, as opposed to being limited to apps that can only handle structured data like SQL.
Support of BI and ML tools
Data lakehouses enable advanced analytics by providing integration with the most popular BI tools like Tableau and PowerBI. Data lakehouses utilize open data formats (e.g. Parquet) with APIs and machine learning libraries, which allows data scientists to leverage the data.
Easy data governance
By enforcing data integrity, data lakehouse architecture enables implementing better data security schemas than data lakes.
Cons
Possible reduced functionality
It could be a challenge to design and maintain the monolithic design of the lakehouse. Besides, universal designs may have lower functionality than those developed for specific use cases.
Underdeveloped concept
Data lakehouses are a relatively new technology and need further development. The current state of tech doesn’t allow rolling out all their capabilities.
Data warehouses vs. data lakes vs. data lakehouses: comparative analysis
The difference between the three storage options can be summarized as follows.
Data in the data warehouse is easy to use, but harder to store. The opposite is true for the data lake: it’s easy to ingest and store data there, but using and querying it may pose problems. If you have different data, some of which is better suited for the first option and some for the second, the optimal solution would be a lakehouse. It provides structured storage for some types of data and unstructured storage for others while keeping all data in one place.
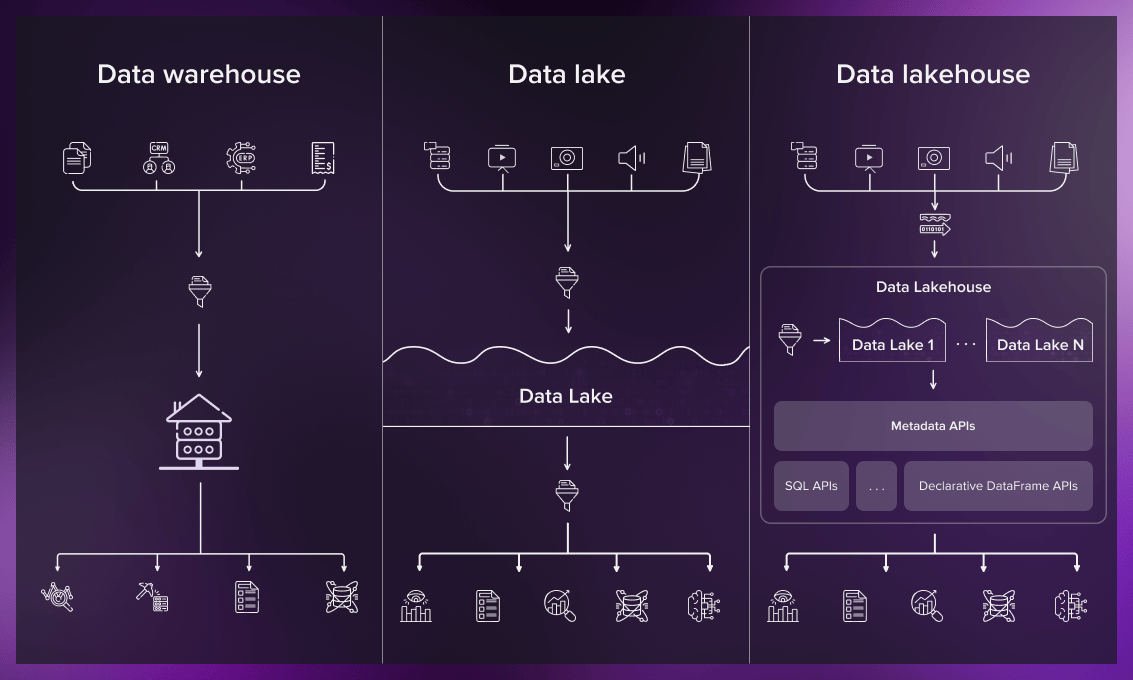
The table below gives a brief overview of the three architectures.
| Data lakes | Data warehouses | Data lakehouses | |
| Type of data | Semi-structured and unstructured data | Structured data | Structured, semi-structured, and unstructured data |
| Purpose | Applicable for machine learning and artificial intelligence tasks | Best for data analytics and BI, but limited to particular problem-solving | Flexible storage, can be used for research, data analytics and ML |
| ACID compliance | Non-ACID compliant: data integrity issues | ACID-compliant: ensures the integrity of data | ACID-compliant: ensures consistency of data read and written by multiple sources |
| Cost of storage | Cost-effective, fast, flexible | Expensive, time-consuming | Cost-effective, easy, allows for a lot of flexibility, reduced data duplication |
Watch this recap video that explains the difference between data lakes, data warehouses, and data lakehouses.
Сonclusion
A data lakehouse allows you to aggregate and update data in one place. The storage is secure and enables quick access to data and the use of various analytical tools, combining the benefits of data lakes and data warehouses.
You can store both structured and unstructured data in data lakehouses. Their flexible storage architecture makes it easy to extract and analyze any metrics to evaluate new hypotheses.
If your company wishes to utilize pioneering technologies to build effective solutions based on data analysis, data lakehouses are an option you should not overlook.
Serokell provides data storage consultancy and software development with Python. Contact us to get a tailor-made solutions for your business.

.jpg)
.jpg)


.jpg)
.jpg)