
ChatGPT has transformed the way people communicate with machines. Instead of presenting users with numerous pages to sift through and evaluate, it provides written answers to their questions in mere seconds. In this blog post, we dive inside СhatGPT’s brain and explore large language models (LLMs) and other technologies that allow chatbots to communicate like people.
After the initial excitement of using ChatGPT has subsided, the next question that arises is: “How can the machine reply to questions like a human, and what is the underlying mechanism?” The basic schema is the following.
During the learning stage, an ML model was trained to analyze texts and rewarded for each correct answer. Additionally, a self-attention mechanism was integrated to improve the effectiveness of the learning process by prioritizing important combinations and reducing the weight of other features. ChatGPT is based on a combination of models, which we will discuss below, beginning with the most significant, LLM.
What are large language models (LLMs)?
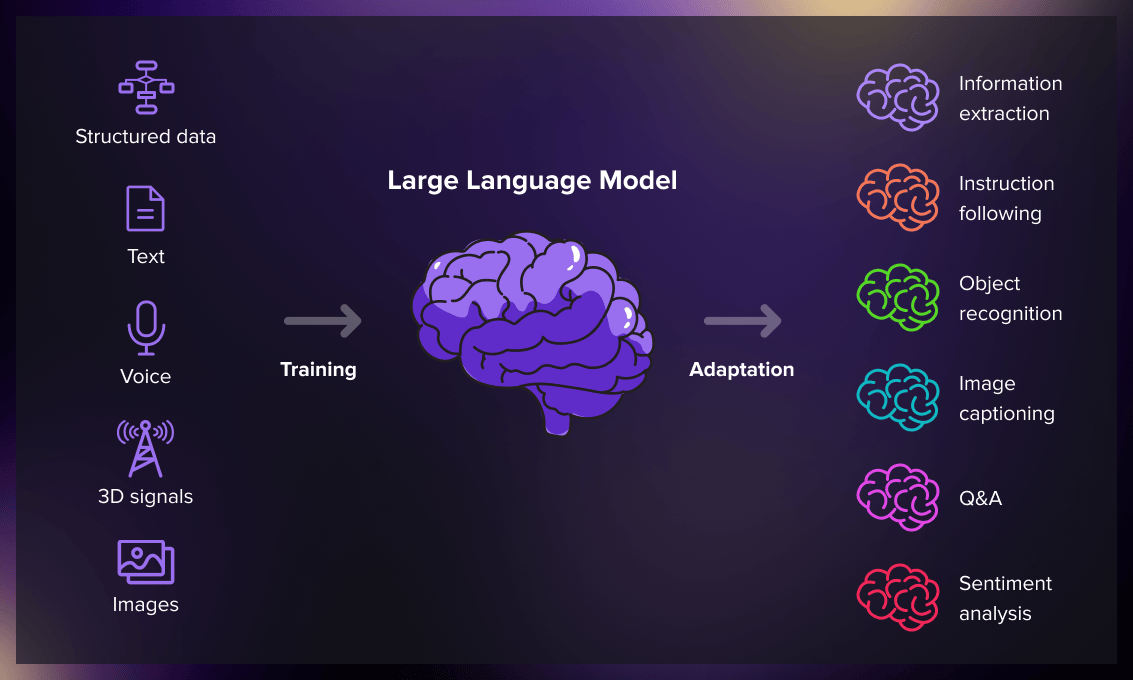
LLMs are natural language processing models that analyze vast amounts of text data and infer connections between words within the text. Over the past few years, advances in computational power have allowed these machine learning models to grow in size and capability. The more extensive the input dataset and parameter space, the more robust LLMs become.
Language models are typically trained using next-token prediction. This technique involves predicting the next word in a sequence using the Long-Short-Term-Memory (LSTM) neural network and masked-language modeling. The latter involves completing a sentence by selecting the most statistically probable word based on the context.
This short video explains the tech behind LLMs:
However, these sequential techniques have some limitations.
For instance, the model may fail to prioritize certain words over others, leading to inaccurate predictions. Besides, input data is processed sequentially rather than as a whole corpus. This limits its ability to understand word connections and deduce the possible meanings.
These issues can be addressed through advanced techniques such as self-attention mechanisms, which enable large language models like GPT-3 to process input data as a whole and derive more nuanced relationships between words.
To tackle this problem, in 2017, a team from Google Brain introduced transformers. The transformer deep learning model is trained to perform multiple tasks simultaneously, and attention mechanisms enable it to selectively allocate resources to each task based on their relative importance.
Transformers can process all input data simultaneously, which is impossible with LSTMs. With the self-attention mechanism, the model can assign different levels of significance to various input data segments, regardless of the position in the text sequence. The ability to perform simultaneous processing allowed for significant improvements in embedding meaning into LLMs and made it possible to handle much larger datasets. Just as a greater vocabulary allows educated humans to express themselves more effectively, larger semantic datasets provide chatbots with more opportunities to put together appropriate word combinations.
Self-Attention
OpenAI introduced the first Generative Pre-training Transformer (GPT)l, GPT-1, in 2018. Since then, GPT models have undergone several upgrades, including GPT-2 in 2019, GPT-3 in 2020, InstructGPT, and ChatGPT in 2022. The most significant advancement in GPT evolution before integrating human feedback was the enhancement in computational efficiency, which enabled GPT-3 to train on a more extensive dataset than GPT-2, leading to a more diverse knowledge base and the ability to perform a broader range of tasks.
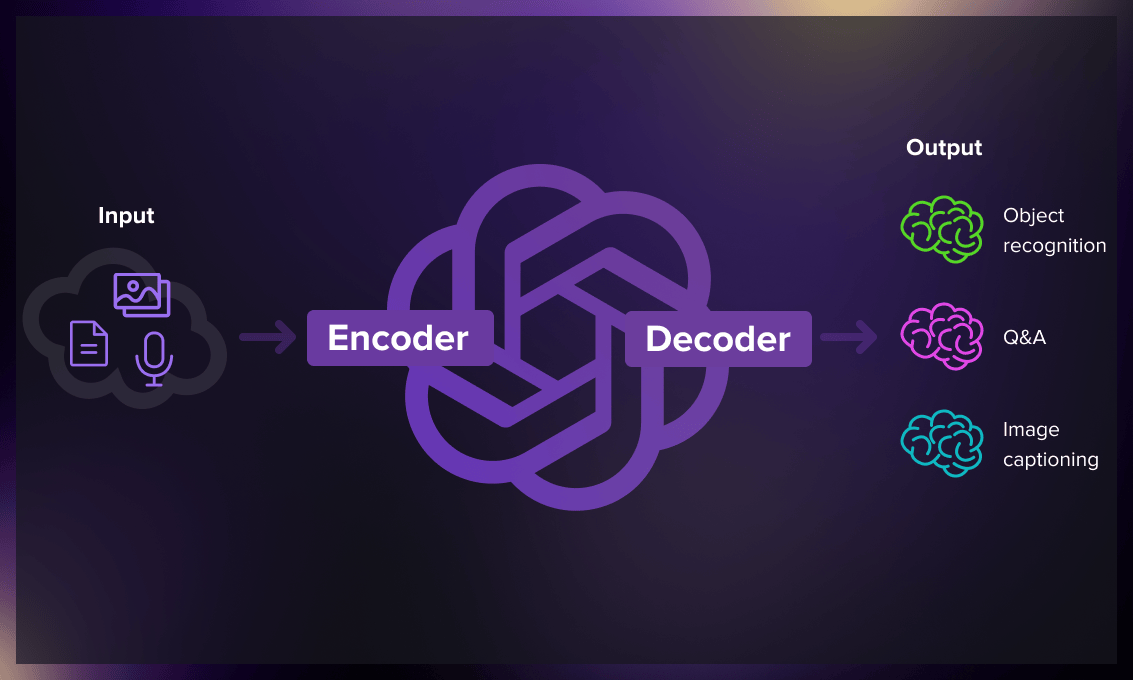
All GPT models use the transformer architecture, with an encoder for processing the input sequence and a decoder for generating the output. The multi-head self-attention assigns different levels of significance to various parts of the sequence, allowing the model to understand meaning and context. Additionally, the encoder employs masked-language modeling to comprehend word relationships and produce more coherent responses.
The self-attention mechanism in GPT converts text pieces (tokens) into vectors representing their significance in the input sequence. This process involves creating a query, key, and value vector for each token; calculating the similarity between the query and key vectors; generating normalized weights using a softmax function; and producing a final vector representing the token’s importance within the sequence.
In GPT, the multi-head attention mechanism goes beyond assigning varying degrees of importance to different parts of the input sequence. The mechanism iterates multiple times, enabling the model to comprehend sub-meanings and more intricate relationships within the input data.
Despite notable advancements in natural language processing, GPT-3 still faces challenges in accurately interpreting the user’s intentions. Its outputs can be unhelpful as they contain “hallucinations” based on false information, lack interpretability, or even include toxic and biased content that can cause harm and spread misinformation. ChatGPT addresses some of these problems inherent in traditional LLMs by using innovative training techniques.
How ChatGPT was improved
ChatGPT is the development of InstructGPT, which introduced a new method of incorporating human feedback into the training process. This approach aimed to improve the alignment between the model’s outputs and the user’s intentions. At its core is the Reinforcement Learning from Human Feedback (RLHF) technique, sometimes called Reinforcement Learning from Human Preferences, which we explain in simpler terms below.
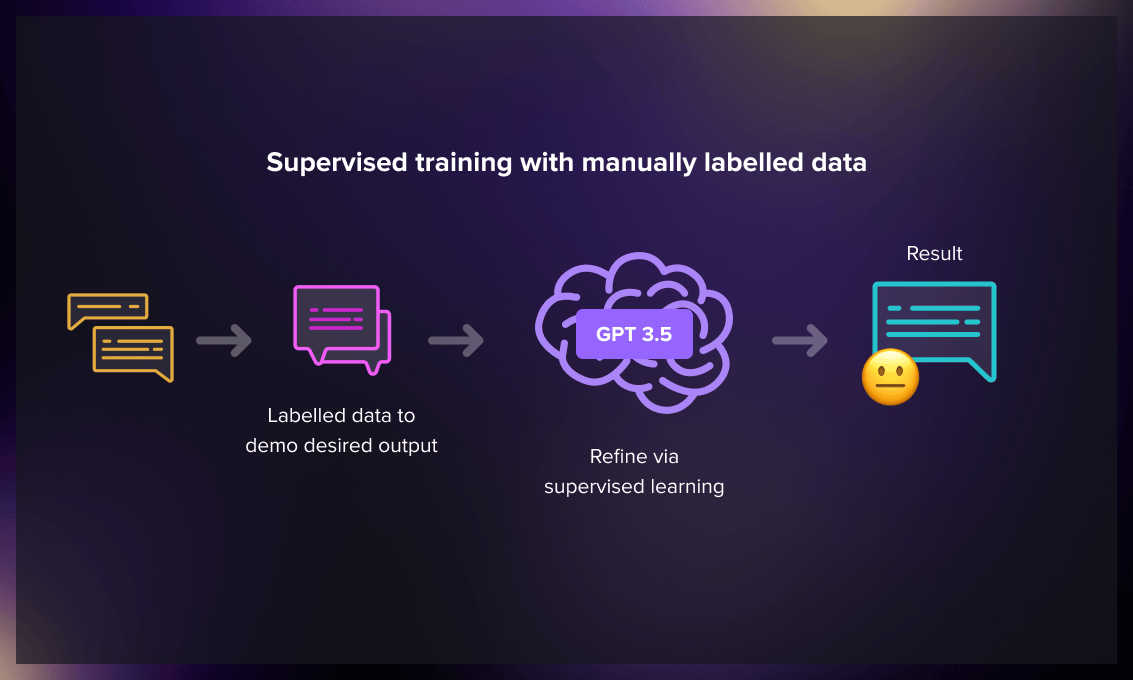
Supervised Fine Tuning model
Initially, the GPT-3 model underwent fine-tuning through supervised training. Forty contractors were recruited to create input/output pairs or prompts based on actual user entries into the OpenAI API. The labelers generated suitable responses to each prompt, thereby creating a known output for the model to learn from. Subsequently, GPT-3 was fine-tuned using this new dataset to develop the SFT (Supervised Fine Tuning) model, or GPT-3.5.
To ensure diversity, a maximum of 200 prompts were allowed from a single user ID, and any prompts that shared extended common prefixes were eliminated. Prompts containing personally identifiable information (PII) were also removed. Additionally, labelers were asked to create sample prompts to fill out categories with minimal actual sample data, including plain prompts, few-shot prompts (instructions with multiple query/response pairs), and user-based prompts.
Labelers were instructed to deduce the user’s intention when generating responses. Prompts were categorized into three main types of information requests:
- Direct (such as “Tell me about…”).
- Few-shot (which involved providing two examples of a story and asking the model to generate another story on the same topic).
- Continuation (which required the model to finish a story based on a provided beginning).
Compiling prompts from the OpenAI API and those hand-written by labelers resulted in 13,000 input/output samples used to train the supervised model.
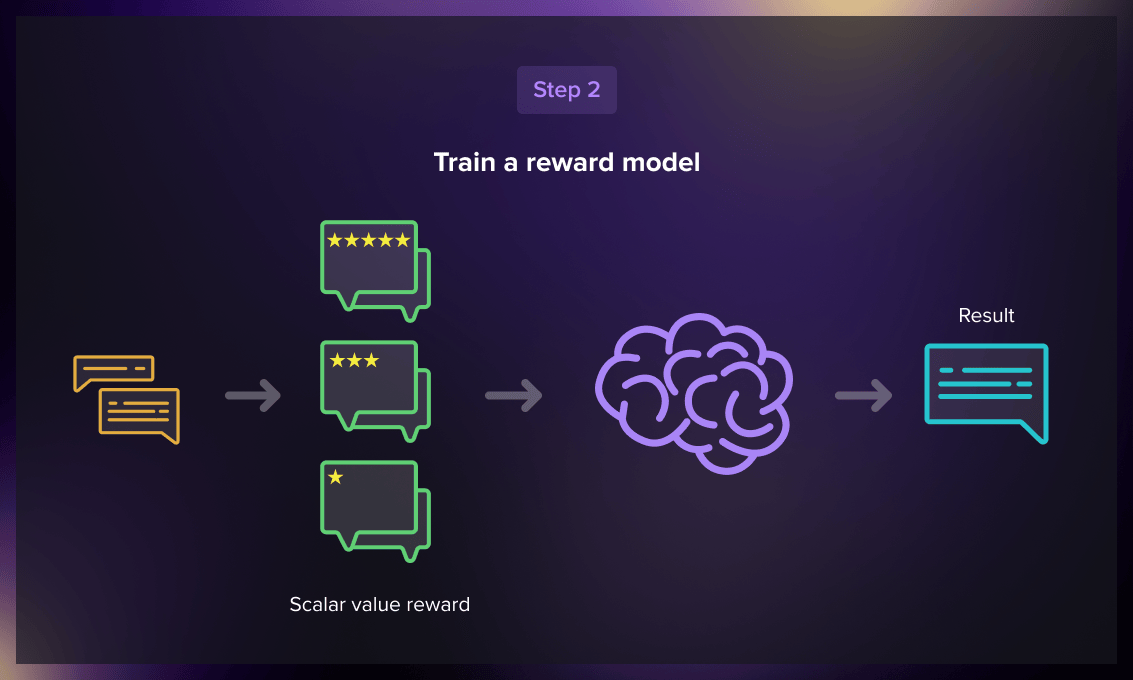
Reward model
The subsequent step involved training a reward model, which takes a series of prompts and responses as input and generates a scalar value reward. This reward was then used to train the model through reinforcement learning techniques, enabling it to learn how to maximize the reward.
The labelers were given 4 to 9 SFT model responses for one input prompt and instructed to rank them in descending order based on their quality. These rankings were then combined to create various output combinations. However, including each combination as a separate data point would lead to overfitting, which means the model would fail to generalize beyond the provided data. To address this issue, the model was trained using each rankings group as a single batch data point.
Reinforcement learning
In the final phase, the model was presented with a random prompt and generated a response using the policy it learned in the second step. The reward model assigned a scalar reward value to the prompt and response pair, influencing the model to update its policy accordingly.
In 2017, Schulman et al. introduced Proximal Policy Optimization (PPO) for updating the model’s policy with each generated response. PPO integrates a per-token Kullback-Leibler (KL) penalty from the SFT model. The KL divergence measures the similarity between two distribution functions and penalizes extreme distances. In this scenario, the Kullback-Leibler penalty decreases the gap between the responses and the supervised fine-tuned model of the model. This is necessary to avoid excessive optimization of the reward model.
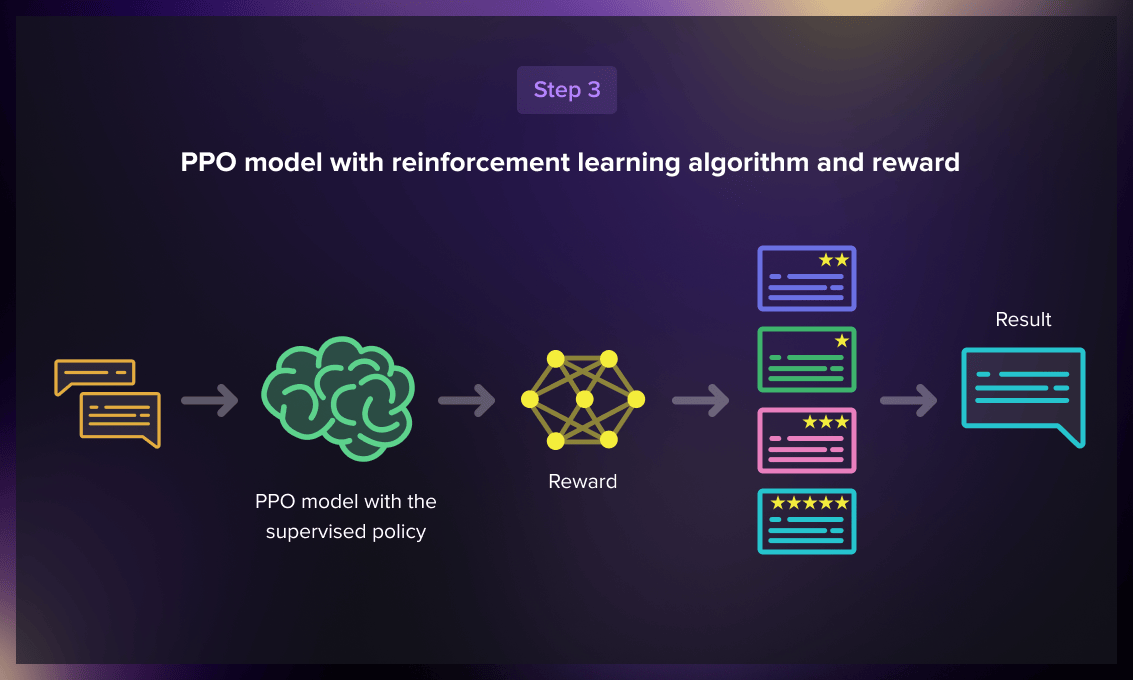
How was the model evaluated
Before training, a test data set previously encountered by the model was set aside. It was then used to evaluate if the model is better aligned than its predecessor, GPT-3.
The evaluation criteria included the following:
- Veracity. This criterion relates to the model’s propensity to generate false information. The PPO model’s outputs showed minor enhancements in truthfulness and informativeness when evaluated using the TruthfulQA dataset.
- Usefulness. This metric measures the language model’s ability to understand and execute user instructions. According to labelers, InstructGPT’s outputs were preferred over GPT-3’s 85 ± 3% of the time.
- Harmlessness. This aspect evaluates the LLM’s proficiency in avoiding inappropriate, derogatory, and offensive content.
How is ChatGPT going to evolve?
The development of ChatGPT will depend on how the current limitations of large language models will be overcome. These include not only technical aspects but also ethical concerns about its potential biases.
The main challenges related to scaling large language models are the following:
1. High costs for architecture, processing, and experimentation
The large scale of language models makes them costly to operationalize. They require significant computational resources for distributing parameters across multiple processing engines and memory blocks. Additionally, experimentation costs can add up quickly, exhausting resources even before the model makes it to production.
2. Language misuse
LLMs are trained on huge amounts of data from diverse sources. However, collecting heterogeneous data can lead to biases from the data sources’ cultures and societies. Verifying the credibility of such large amounts of data can also be time-consuming. Partial and false data can result in discriminatory and erroneous outcomes.
3. Fine-tuning for specific tasks
While large language models are generally accurate for large-scale data, repurposing them for particular domains and tasks can be challenging. Fine-tuning existing models for specific downstream tasks is necessary, but getting it right takes time and effort. Accurately determining the correct data, hyperparameters, and base models is crucial to maintaining explainability.
4. Hardware challenges
Even with a budget for large-scale distribution, creating an optimal hardware plan for large language models is challenging. No one-size-fits-all hardware stack exists, and optimized algorithms are necessary for computational resources to adjust to scalable models. Besides, finding computing experts for large language models can be difficult.
Watch this video explaining the potential risks of large language models:
Despite these challenges, one thing seems certain: ChatGPT will continue to gain traction as ordinary users and developers come up with new ideas for its applications. The question now is how we will ensure that these applications remain ethical.

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)