
Despite being vital to machine learning, feature engineering is not always given due attention. Feature engineering is a supporting step in machine learning modeling, but with a smart approach to data selection, it can increase a model’s efficiency and lead to more accurate results. It involves extracting meaningful features from raw data, sorting features, dismissing duplicate records, and modifying some data columns to obtain new features more relevant to your goals.
From this article, you will learn what feature engineering is and how it can be used to improve your machine learning models. We’ll also discuss different types and techniques of feature engineering and what each type is used for.
This article was updated on December 21, 2023 (new libraries added to the section “Tools for feature engineering”).
Why is feature engineering essential?
Feature engineering is necessary for designing accurate predictive models to solve problems while decreasing the time and computation resources needed.
The features of your data have a direct impact on the predictive models you train and the results you can get with them. Even if your data for analysis is not ideal, you can still get the outcomes you are looking for with a good set of features.
But what is a feature? Features are measurable data elements used for analysis. In datasets, they appear as columns. So, by choosing the most relevant pieces of data, we achieve more accurate predictions for the model.
Another important reason for using feature engineering is that it enables you to cut time spent on data analysis.
What is feature engineering?
Feature engineering is a machine learning technique that transforms available datasets into sets of figures essential for a specific task. This process involves:
- Performing data analysis and correcting inconsistencies (like incomplete, incorrect data or anomalies).
- Deleting variables that do not influence model behavior.
- Dismissing duplicates and correlating records and, sometimes, carrying out data normalization.
This technique is equally applicable to supervised and unsupervised learning. With the modified, more relevant data, we can enhance the model accuracy and response time with a smaller number of variables rather than increasing the size of the dataset.
Feature engineering steps
.png)
Preliminary stage: Data preparation
To start the feature engineering process, you first need to convert raw data collected from various sources into a format that the ML model can use. For this, you perform data cleansing, fusion, ingestion, loading, and other operations. Now you’re ready for feature engineering.
Exploratory data analysis
It consists in performing descriptive statistics on datasets and creating visualizations to explore the nature of your data. Next, we should look for correlated variables and their properties in the dataset columns and clean them, if necessary.
Feature improvement
This step involves the modification of data records by adding missing values, transforming, normalizing, or scaling data, as well as adding dummy variables. We’ll explain all these methods in detail in the next section.
Feature construction
You can construct features automatically and manually. In the first case, algorithms like PCA, tSNE, or MDS (linear and nonlinear) will be helpful. When it comes to manual feature construction, options are virtually endless. The choice of the method depends on the problem to be solved. One of the most well-known solutions is convolution matrices. For example, they have been widely used to create new features while working on computer vision problems.
Feature selection
Feature selection, also known as variable selection or attribute selection, is a process of reducing the number of input variables (feature columns) by selecting the most important ones that correlate best with the variable you’re trying to predict while eliminating unnecessary information.
There are many techniques you can use for feature selection:
- filter-based, where you filter out the irrelevant features;
- wrapper-based, where you train ML models with different combinations of features;
- hybrid, which implements both of the techniques above.
In the case of filter-based methods, statistical tests are used to determine the strength of correlation of the feature with the target variable. The choice of the test depends on the data type of both input and output variable (i.e. whether they are categorical or numerical.). You can see the most popular tests in the table below.
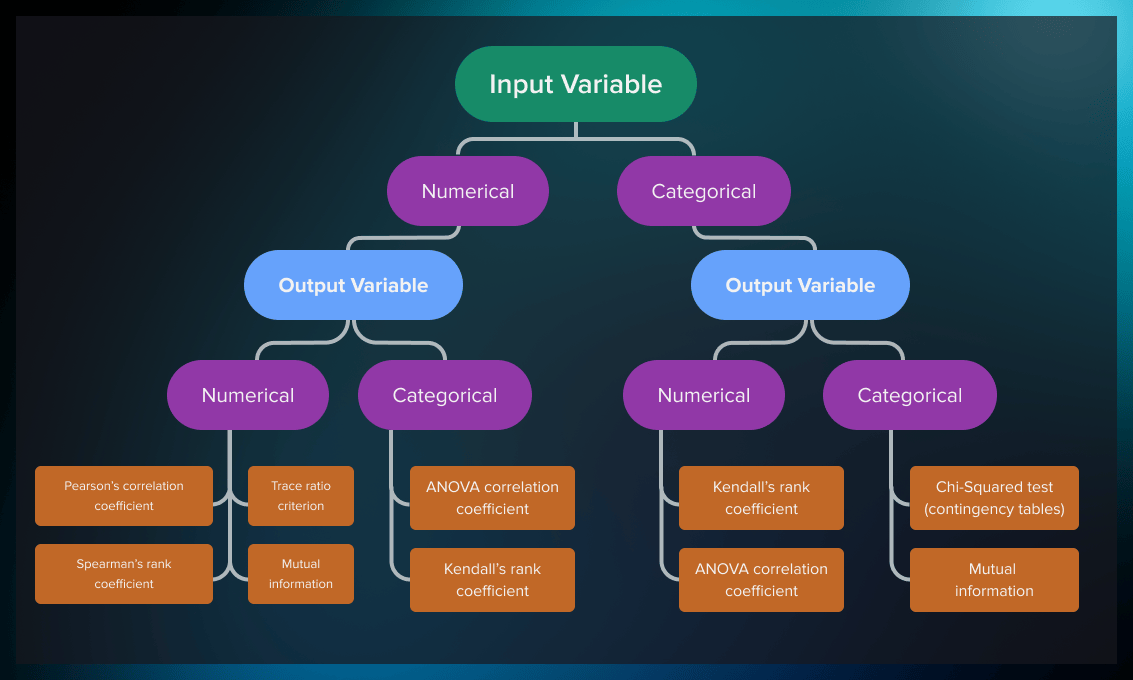
| Input | Output | Feature Selection Model |
| Numerical | Numerical |
|
| Numerical | Categorical |
|
| Categorical | Numerical |
|
| Categorical | Categorical |
|
Model evaluation and verification
Evaluate the model’s accuracy on training data with the set of selected features. If you have achieved the desired accuracy of the model, proceed to model verification. If not, go back to feature selection and revisit your set of attributes.
Feature engineering methods
Imputation
Imputation is the process of managing missing values, which is one of the most common problems when it comes to preparing data for machine learning. By missing values, we mean places where information is missing in some cells of a respective row.
There may be different causes for missing values, including human error, data flow interruptions, cross-datasets errors, etc. Since data completeness impacts how well machine learning models perform, imputation is quite important.
Here are some ways how you can solve the issue of missing values:
- If a row is less than 20-30% complete, it’s recommended to dismiss such a record.
- A standard approach to assigning values to the missing cells is to calculate a mode, mean, or median for a column and replace the missing values with it.
- In other cases, there are possibilities to reconstruct the value based on other entries. For example, we can find out the name of a country if we have the name of a city and an administrative unit. Conversely, we can often determine the country/city by a postal code.
You can find more sophisticated approaches to imputation in this post.
Outlier handling
Outlier handling is another way to increase the accuracy of data representation. Outliers are data points that are significantly different from other observations.
This graph shows how outliers can influence the ML model. By dismissing the outliers, we can achieve more accurate results.
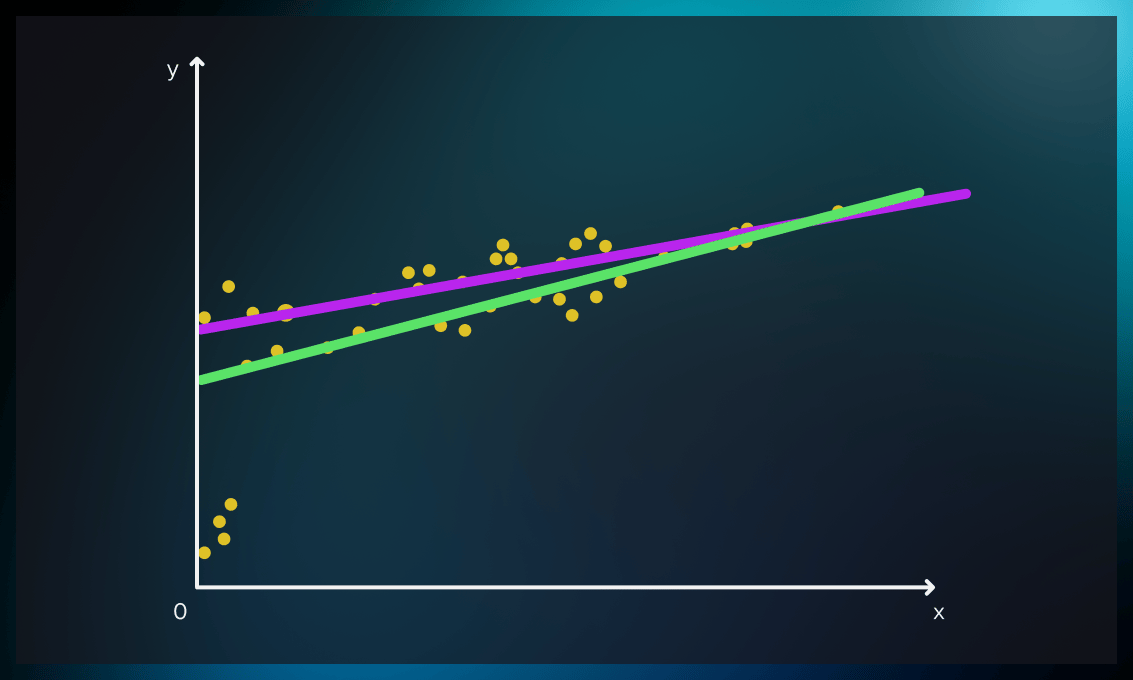
It can be done by removing or replacing outliers. Check out this post for an overview of the five most popular approaches to handling outliers.
One-hot encoding
Categorical values (often referred to as nominal) such as gender, seasons, pets, brand names, or age groups often require transformation, depending on the ML algorithm used. For example, decision trees can work with categorical data. However, many others need the introduction of additional artificial categories with a binary representation.
Binary representation means you assign a value of 1 if the feature is valid and 0 if it is not.
| ID | Male | Female |
| User 1 | 1 | 0 |
| User 2 | 0 | 1 |
One-hot encoding is a technique of preprocessing categorical features for machine learning models. For each category, it designs a new binary feature, often called a “dummy variable.”
Log transformation
This method can approximate a skewed distribution to a normal one. Logarithm transformation (or log transformation) replaces each variable x with a log(x).
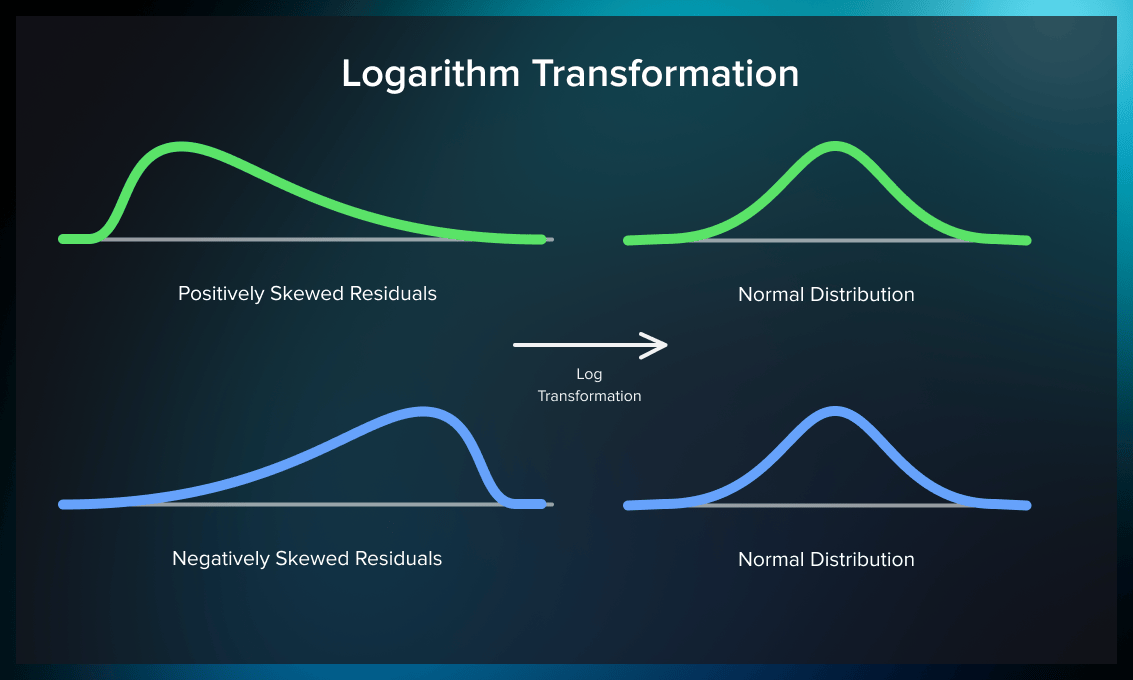
The benefits of log transform:
- Data magnitude within a range often varies. For example, magnitude between ages 10 and 20 is not the same as that between ages 60 and 70. Differences in this type of data are normalized by log transformation.
- Normalizing magnitude differences and increasing the robustness of the model also reduces the negative effect of outliers.
If we compare graphs on top and bottom, we’ll see that mode, mean, and median are slightly different for normal and skewed distribution.
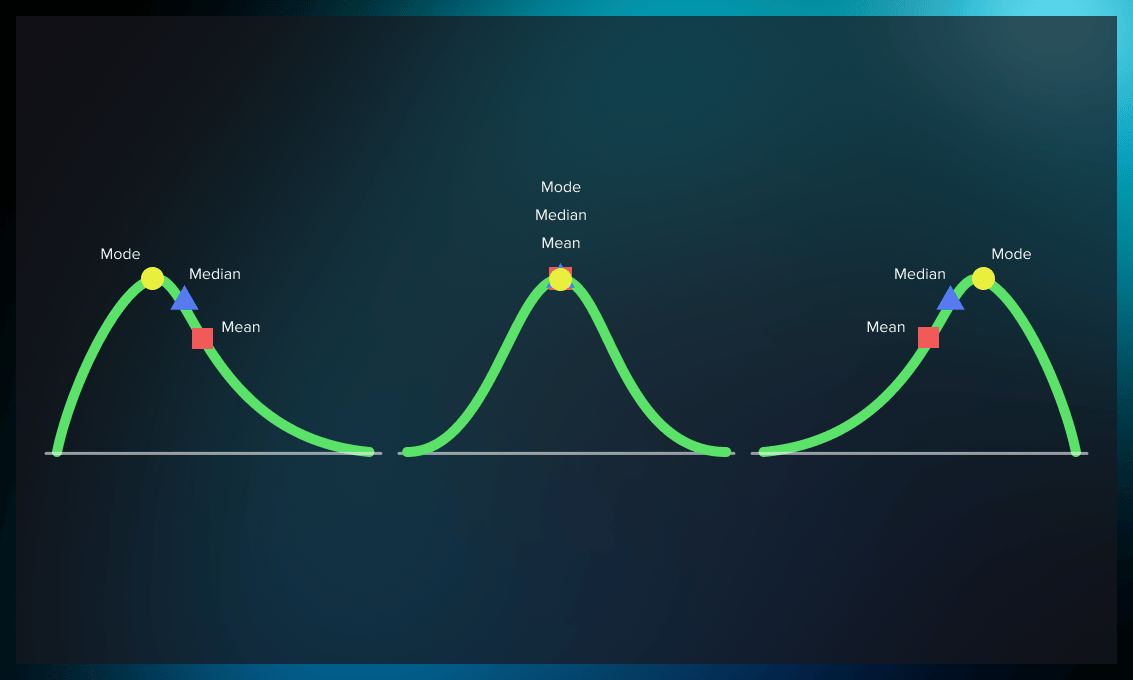
Normal distribution has undeniable advantages, but note that in some cases it can affect the model’s robustness and accuracy of results.
Scaling
Scaling is a data calibration technique that facilitates the comparison of different types of data. It is useful for measurements to correct the way the model handles small and large numbers.
For example, despite its small value, the floor number in a building is as important as the square footage.
As another example, it is easier to perform a comparative analysis of the planets if we normalize values using their proportions against each other instead of actual diameters.
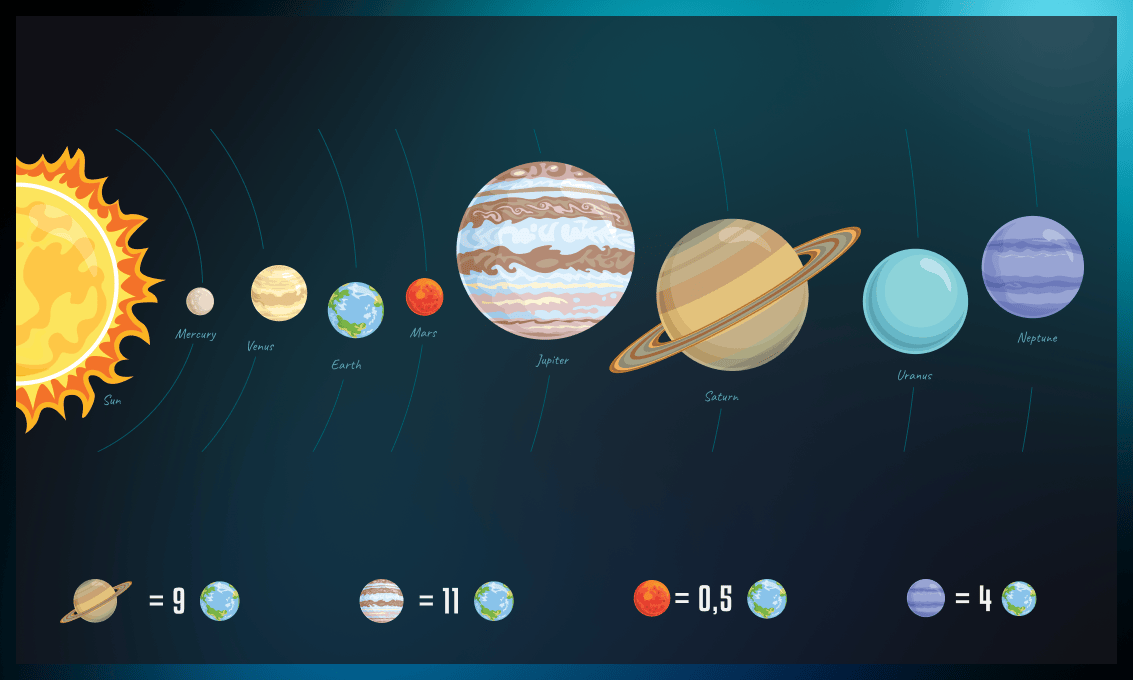
The most popular scaling techniques include:
- min-max scaling
- absolute maximum
- standardization
- normalization
Min-max scaling is represented by the following formula:
The absolute maximum scaling technique consists in dividing all figures in the data set by its max value.
Standardization is done by calculating the difference between the individual numbers and their mean, divided by the range of variation, called the standard deviation (sigma). The following equation describes the entire process:
Normalization is quite similar, except that we work with the difference of each value from the mean, divided by the difference between maximum and minimum values in the dataset.
To implement scaling, you can use Python frameworks such as Scikit-learn, Panda, or RasgoQL. Check out this Kaggle guide for some practical scaling tips.
Tools for feature engineering
Below, you will find an overview of some of the best libraries and frameworks you can use for automating feature engineering.
Scikit-learn
This machine learning library for Python is known for its simplicity and efficiency in data analysis and modeling. Scikit-learn offers many robust tools, including classification, regression, clustering, and dimensionality reduction. What sets Scikit-learn apart is its user-friendly interface, which allows even those with minimal experience in ML to easily implement powerful algorithms. Additionally, it provides extensive documentation and plenty of examples.
Feature-engine
Feature-engine is a Python library designed to engineer and select features for machine learning models, compatible with Scikit-learn’s fit() and transform() methods. It offers a range of transformers for tasks, such as missing data imputation, categorical encoding, outlier handling, and more, allowing for targeted transformations on selected variable subsets. Feature-engine transformers can be integrated into scikit-learn pipelines, enabling the creation and deployment of comprehensive ML pipelines in a single object.
TSFresh
TSFresh is a free Python library containing well-known algorithms from statistics, time series analysis, signal processing, and nonlinear dynamics. It is used for the systematic extraction of time-series features. These include the number of peaks, the average value, the largest value, or more sophisticated properties, such as the statistics of time reversal symmetry.
Feature Selector
As the name suggests, Feature Selector is a Python library for choosing features. It determines attribute significance based on missing data, single unique values, collinear or insignificant features. For that, it uses “lightgbm” tree-based learning methods. The package also includes a set of visualization techniques that can provide more information about the dataset.
PyCaret
PyCaret is a Python-based open-source library. Although it is not a dedicated tool for automated feature engineering, it does allow for the automatic generation of features before model training. Its advantage is that it lets you replace hundreds of code lines with just a handful, thus increasing productivity and exponentially speeding up the experimentation cycle.
Some other useful tools for feature engineering include:
- the NumPy library with numeric and matrix operations;
- Pandas where you can find the DataFrame, one of the most important elements of data science in Python;
- Matplotlib and Seaborn that will help you with plotting and visualization.
Advantages and drawbacks of feature engineering
| Benefits | Drawbacks |
| Models with engineered features result in faster data processing. | Making a proper feature list requires deep analysis and understanding of the business context and processes. |
| Less complex models are easier to maintain. | Feature engineering is often time-consuming. |
| Engineered features allow for more accurate estimations/predictions. | Complex ML solutions achieved through complicated feature engineering are difficult to explain because the model's logic remains unclear. |
Practical examples of feature engineering
Serokell uses feature engineering in a variety of custom ML services we provide. In this section, we share some industry examples from our experience.
Gaining more insights from the same data
Many datasets contain variables such as date, distance, age, weight, etc. However, often it would be best to transform them into other formats to obtain answers to your specific questions. For example, weight per se might not be helpful for your analysis. But if you convert your data into BMI (body mass index, a measure of body fat based on height and weight), you get a different picture, enabling you to make conclusions about a person’s overall health.
Values like date and duration can predict repetitive actions, such as repeated user visits to an online store over a month or year, or reveal correlations between sales volumes and seasonal trends.
Watch the video below to see how real-life feature engineering looks like in Python.
Building predictive models
By selecting relevant features, you can build predictive models for various industries, for example public transportation. This case study describes how to design a model predicting the ridership on Chicago “L” trains. It should be noted that each constructed feature needs verification. Thus, the hypothesis that weather conditions impact the number of people entering a station turned out invalid.
This academic paper demonstrates how feature engineering can improve prediction for heart failure readmission or death.
Another case study shows how to predict people’s profession based on discrete data. Predictor clusters included variables such as geographic location, religious affiliation, astrological sign, children, pets, income, education.
As an additional example, watch this video explaining how feature engineering helps construct a model in TensorFlow to predict income based on age.
Overcoming the “black box” problem
One of the most significant drawbacks of neural networks, especially critical for healthcare, is that it’s impossible to understand the logic behind their predictions. This “black box” effect decreases trust in the analysis as physicians can’t explain why the algorithm came up with a particular conclusion.
The authors of this research paper suggest incorporating expert knowledge in ML models with the help of feature engineering. This way, the model created can be simpler and easier to interpret.
Detecting malware
Malware is hard to detect manually. Neural networks are not always effective either. But you can use a combined approach which includes feature engineering as the first step. With it, you can highlight specific classes and structures for which the ML model should look out at the next stage. Find out more here.
Conclusions and further learning

As we have seen, feature engineering is an essential and extremely helpful approach for data scientists that can enhance ML model efficiency exponentially. If you are ready to dive deeper into this promising area, we recommend reading the following books.
-
Feature Engineering Bookcamp by Sinan Ozdemir
The book takes you through a series of projects that give you hands-on experience with basic FE techniques. In this helpful book, you’ll learn about feature engineering through engaging, code-based case studies such as classifying tweets, detecting stock price fluctuations or predicting pandemic development, and much more.
-
Python Feature Engineering Cookbook: Over 70 recipes for creating, engineering, and transforming features to build machine learning models by Soledad Galli
With this cookbook, you will learn to simplify and improve the quality of your code and apply feature engineering techniques in machine learning. The authors explain how to work with continuous and discrete datasets and modify features from unstructured datasets using Python packages like Pandas, Scikit-learn, Featuretools, and Feature-Engine. You will master methods for selecting the best features and the most appropriate extraction techniques.
-
Feature Engineering and Selection: A Practical Approach for Predictive Models by Max Kuhn and Kjell Johnson
The development of predictive models is a multi-step process. Most materials focus on the modeling algorithms. This book explains how to select the optimal predictors to improve model performance. The author illustrates his narrative with various data sets examples and provides R programs for replicating the results.
-
Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists by Alice Zheng, Amanda Casari
Each chapter guides you through a particular data problem, such as text or image data representation. The authors provide a series of exercises throughout the book rather than just teaching specific topics (FE for numeric data, natural text analysis techniques, model stacking, etc.). The final chapter rounds the discussion by applying various feature engineering methods to an actual, structured data set. Code examples include Numpy, Pandas, Scikit-Learn, and Matplotlib.
You will find more relevant materials on ML-related topics on our blog.

.jpg)
.jpg)



