
Deep learning has been a game changer in the field of computer vision. It’s widely used to teach computers to “see” and analyze the environment similarly to the way humans do. Its applications include self-driven cars, robotics, data analysis, and much more.
In this blog post, we will explain in detail the applications of deep learning for computer vision. But before doing that, let’s understand what computer vision and deep learning are.
What is computer vision?
Computer vision (CV) is a field of artificial intelligence that enables computers to extract information from images, videos, and other visual sources.
As a scientific discipline, computer vision is concerned with the theory behind artificial systems that extract information from images. As a technological discipline, computer vision seeks to apply its theories in the development of practical computer vision systems. The overall goal of computer vision is to develop systems that can automatically recognize, process, and interpret visual content to solve tasks in a variety of areas. Computer vision is used for video surveillance, public safety, and, more recently, for driver assistance in cars, and the automation of processes such as manufacturing and logistics.

What is deep learning?
Deep learning (DL) is a machine learning method based on artificial neural networks (ANN). Deep learning involves training artificial neural networks on large datasets. These networks consist of many layers of information processing units (neurons) that are loosely inspired by the way the brain works.
Each neuron performs its own simple operation on input from other units and sends its output to other units in subsequent layers until we get an output layer with predicted values. Deep neural networks can have many parameters (more than 10 million in some cases), which allows them to learn complex, non-linear relationships between inputs and outputs.
There are several types of NNs:
- convolutional (CNN)
- recurrent (RNN)
- generative adversarial (GAN)
- recursive
The most crucial type of neural network for computer vision is convolutional neural networks. They have been successfully used in many different areas like aerospace and healthcare.
What are convolutional neural networks?
Convolutional neural networks (CNNs) are artificial neural networks with convolutional layers. The main benefit of CNNs is that they can learn features directly from raw pixel values without requiring any hand-engineered features or previous knowledge about the world.
The following process is used for image recognition. The network is given an image, which consists of pixels. In the first convolutional layer, filters are applied to every pixel in the image to create a feature map. This map is then fed into another layer of filters, which produces another map and so on until the last layer makes its prediction.
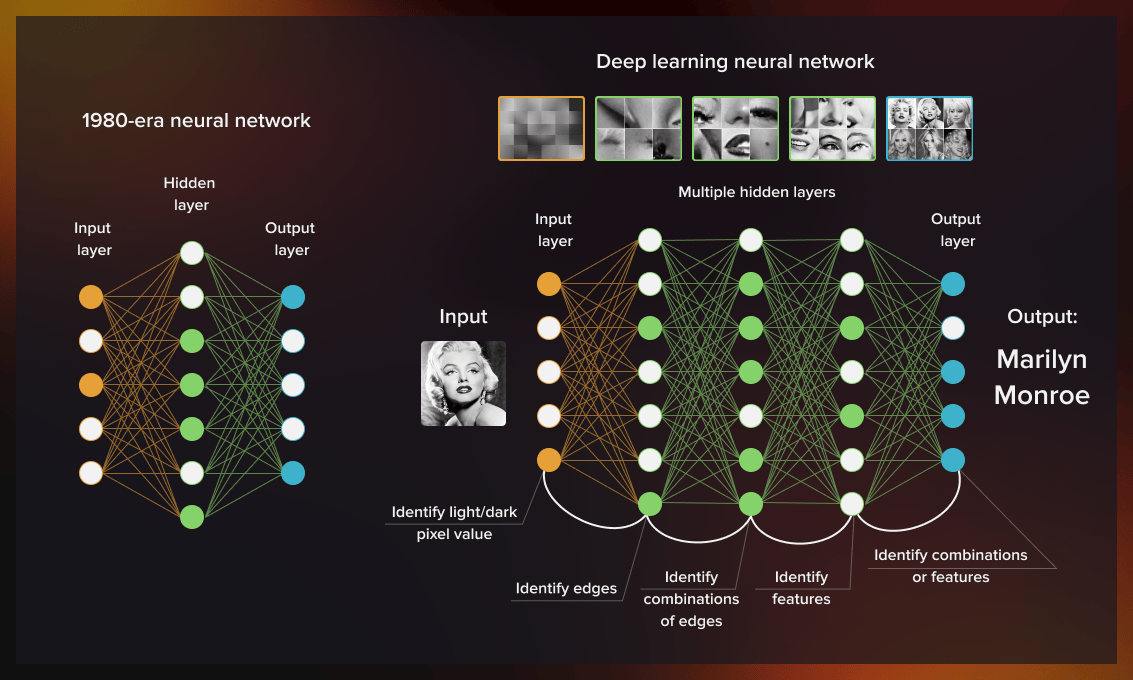
History of computer vision
In 1959, the first digital image scanner converted images into numerical grids to enable computers to recognize pictures. A few years later, Lawrence Roberts, generally considered a pioneer of the internet and computer vision, fostered a discussion about the possibility of deriving 3D geometric data from 2D images. Following that, several academics began working on low-level vision tasks such as segmentation and recognition.
A number of concepts were developed, including approaches to record and/or capture objects and to recognize them by constituent parts. These were based on the assumption that the human eye can recognize objects by breaking them down into their primary constituent units. In the 1980s, Japanese computer scientist Kunihiko Fukushima invented neocognition, the precursor to the modern convolutional neural networks.
All through the 1990s and 2000s, a process called feature engineering was used to manually construct the features to train machine learning algorithms on visual tasks.
A major breakthrough in computer vision was made in 2012 when the AlexNet computer vision algorithm outperformed its rivals by 10% at the ImageNet Large Scale Visual Recognition Challenge. The model did not rely on hand-generated features but on the neural network.
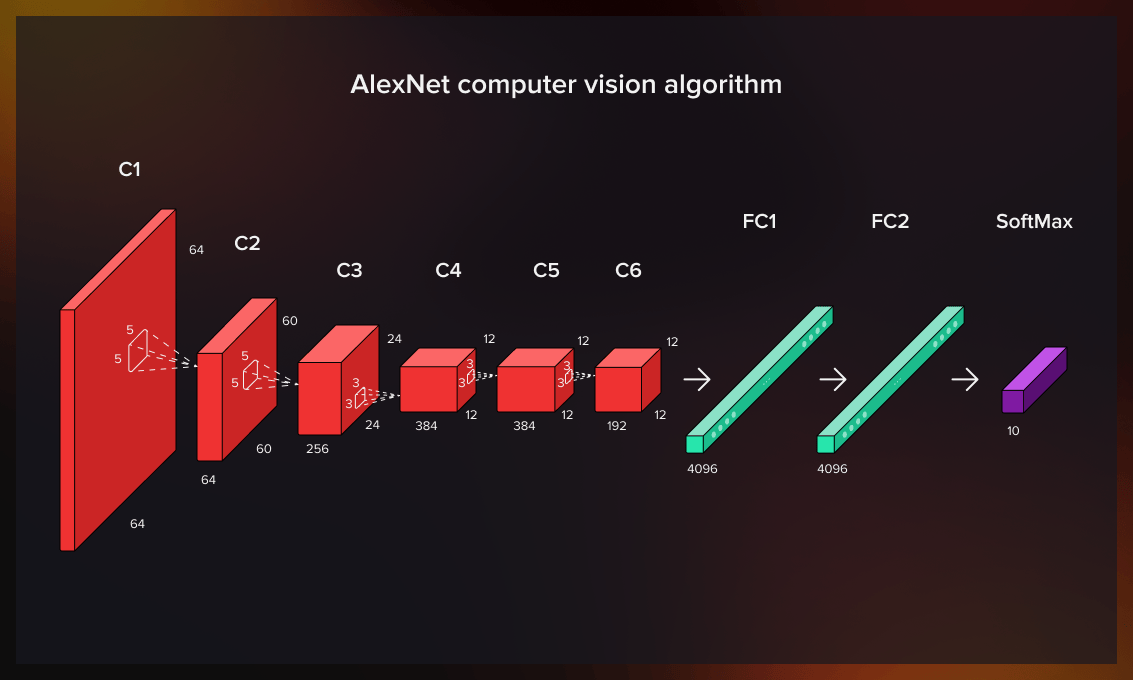
Since then, the efficiency, precision, and overall reliability of computer vision systems have significantly improved thanks to developments in deep learning and computational capacity. Computer vision is now able to recognize objects and patterns almost as effectively as the human eye. As deep learning networks are gaining momentum, CNN architectures are among the most commonly used neural network types.
How is deep learning applied to computer vision tasks?
So how exactly is DL used in computer vision? With the help of convolutional neural networks, deep learning is able to perform the following tasks:
- object recognition
- face recognition
- motion detection
- pose estimation
- semantic segmentation
Object recognition (detection)
Nowadays AI is able to recognize both static and dynamically moving objects with 99% accuracy. How is this done? In general, it is a matter of dividing the image into fragments and letting algorithms find the similarities to one of the existing objects in order to assign it to one of the classes.
Classification plays an important role in this process and the success of object recognition largely depends on the richness of the object database.
One-stage and two-stage object recognition approaches
Before the introduction of the YOLO (You Only Look Once) algorithm, object recognition was performed in two stages. First the image was divided into several bounding boxes, focusing on potential objects. After that, the identification of objects was performed.
In the one-stage approach, the network detects and identifies the image in one go. Watch this short video to see how object recognition works in real time.
Today, we have a choice between one- or two-stage approaches, depending on the goal and what is a priority for us – speed or accuracy. For example, a two-stage object recognition method would be the best solution for analyzing a patient’s mammography screening. In this case, accuracy is more important than speed. Conversely, it is not necessary to see all the details of the car driving directly toward you. In such a situation, the key is to recognize the object’s size and direction so that the driving assistant can brake within seconds to avoid an accident.
If you wish to learn more about object detection and practice doing it yourself, take a look at this 5-hour-long TensorFlow course.
Face recognition
The basic principles of face recognition remain the same as for object recognition. The difference is that the focus shifts to the details necessary to identify a human face in an image or video. For that purpose, a wide database of faces is used. The details analyzed by the algorithm include the contour of the face, the distance between the eyes, the shape of ears and cheekbones, etc.
The most complicated part of the process is to recognize the same persona under different angles, lighting conditions, or with a mask or glasses on. Currently, convolutional neural networks are being taught to use a low-dimensional representation of 3D faces, on which classifiers base their predictions. This approach has the potential to achieve better accuracy than the use of 2D images and a higher operation speed than simple 3D recognition.
What is the difference between face detection and face recognition?
Face detection is the verification of the fact that a human face is present in an image/video. In contrast, face recognition is the identification of a specific person known to the system from the database. Face detection is the first stage of the face recognition process.
Despite the fact that face recognition can significantly simplify many real-world processes like security checks and monitoring in airports, this technology remains controversial. The problem is that the use of data retrieved through face recognition remains unregulated, which sparks privacy concerns.
The extreme example is China’s social credit system that incorporates all aspects of citizens’ lives and is used for judging people’s “trustworthiness.” Data from surveillance systems on the street, as well as information from banks, government agencies, and other institutions is analyzed by a centralized center. Based on that, citizens receive or lose credit points that influence their ability to get work and social benefits.
In the United States, the use of facial recognition by law enforcement is a major issue. Due to this, in November 2021, Facebook announced the shutdown of its facial recognition system and deleted face scan data of more than 1 billion users.
Motion detection
Motion detection is a key part of any surveillance system. This may be used to trigger an alarm, send a notification to someone, or simply record the event for later analysis.
One way to detect motion is by using a motion detector, which detects changes between frames of an image sequence. The simplest form of motion detection is thresholding. This method sets a specific value (threshold) on every pixel in the frame and determines whether the pixel has changed enough from its previous value to be considered as having changed significantly.
Motion detection can also be done using edge detection techniques. Edge detection tools look for edges in an image and then identify pixels that have been marked as being different from surrounding pixels.
Watch this video if you want to dive deeper into the technical side of the motion detection process.
Pose estimation
Human pose recognition is a challenging computer vision task due to the wide variety of human shapes and appearance, difficult illumination, and crowded scenery. For these tasks, photographs, image sequences, depth images, or skeletal data from motion capture devices are used to estimate the location of human joints. Before the advent of deep learning, body pose estimation was based on the identification of body components.
Human pose estimation involves recognizing the position and orientation of a human from an image or sequence of images. This can be done using a single image, but is often done using multiple points to capture different body parts in order to improve accuracy and stability.
The video below gives a good idea of the pose estimation process.
Semantic segmentation
Semantic segmentation is a type of deep learning that attempts to classify each pixel in an image into one of several classes, such as road, sky or grass. These labels are then used during training so that when new images are processed they can also be segmented into these categories based on what they look like compared with previously seen pictures.
The overall goal of semantic segmentation is to separate objects from the background. It can be useful in self-driving cars, robot and human interaction, or other computer vision applications where it is important to understand what is happening in an image while dismissing the noise.
The video below offers a more detailed explanation of how semantic segmentation works.
Key computer vision challenges
Although computer vision has significantly advanced recently, there are several major challenges researchers still have to solve.
One of them is object localization. AI should be able not only to categorize objects but also to determine their positions. Algorithms also need to perform object recognition very fast to meet the requirements of real-time video processing.
Another difficult problem in computer vision yet to be solved is scene recognition. The task consists of several subtopics that require answers to the following questions:
- What is happening in an image?
- What are the visual and structural elements on the scene?
- How do these elements relate to each other?
The solution to this problem is complicated by another aspect. In real-time environments a camera’s input is often based on a series of lines continuously coming from the sensor. They are used to update a constantly changing image on a screen. Algorithms can be confused by a variety of factors, for example, a truck trailer in front of a car.
 Another problem is the correct interpretation of the recognized scene: is the object arriving or leaving, is the door opening or closing. To classify the events correctly, more information should be provided to the system, which is not always possible due to lack of data or limited capabilities.
Another problem is the correct interpretation of the recognized scene: is the object arriving or leaving, is the door opening or closing. To classify the events correctly, more information should be provided to the system, which is not always possible due to lack of data or limited capabilities.
A major obstacle in computer vision is the small amount of annotated data currently available for object recognition. Datasets typically include examples for about 12 to 100 object classes, while image classification datasets can include up to 100,000 classes. Crowdsourcing often generates free image categorization tags (e.g., by parsing the text of user-provided captions). However, it is still very time-consuming to create accurate bounding boxes and labels for object recognition.
Advanced deep learning methods for computer vision
To solve the computer vision challenges mentioned above, there is a range of advanced methods researchers keep working on.
They include:
-
End-to-end learning. This approach is used for deep neural networks (NNs) which are taught to solve a complex task without decompositioning it into subtasks. The main advantage of it is that the learning process is controlled by the NN itself, meaning it is a fully self-taught system.
-
One-shot-learning. This method is based on a difference-evaluation problem and implies that one or few training examples are necessary for the learning process (as opposed to thousands of them in classification models). Such a computer vision system can look at two images it has never seen before and determine whether they represent the same object.
-
Zero-shot-learning. In this case, a model is taught to recognize objects that it has not seen before. Zero-shot methods associate observed and unobserved categories through some auxiliary information. For example, a model has been trained to recognize horses without ever seeing a zebra. It can identify the latter in case it knows that zebras look like striped black-and-white horses.
Computer vision applications across industries
Computer vision has been increasingly used in a wide range of industries that include, transportation, healthcare sports, manufacturing, retail, etc. In this section, we will look at some of the more prominent examples.
Transportation
Thanks to deep learning, large-scale traffic analysis systems can be implemented using relatively cheap surveillance cameras. With the increasing availability of sensors such as CCTV cameras, LiDAR (Light Detection and Ranging) and thermal imaging devices, it is possible to identify, track, and categorize vehicles on the road.
Computer vision technologies are used to automatically detect violations such as speeding, running red lights or stop signs, wrong-way driving, and illegal turning.
CNNs have also enabled the development of effective parking occupancy detection methods. The advantage of camera-based parking lot detection is large-scale deployment, low-cost installation and maintenance.
Healthcare
In medicine, computer vision is used for diagnosing skin and breast cancer. For example, image recognition allows scientists to determine even small differences between cancerous and non-cancerous images in MRI scans.
Deep learning models are applied to detect serious conditions such as impending strokes, balance disorders, and gait problems without the need for medical examination.
Pose estimation helps clinicians diagnose patients faster and more accurately by analyzing their movements. It can also be used in physical therapy. Patients recovering from strokes and injuries need constant supervision. Computer vision-based rehabilitation programs are effective in initial training, making sure the patients perform movements correctly and preventing them from getting additional injuries.
Sports

Computer vision can detect patterns in the position and movement of people across a range of images in recorded or live video transmissions. For example, cameras installed above and below the water surface have been used to determine swimmers’ poses in real time. Without having to manually label the body parts in each video frame, the video footage can be used to objectively evaluate the athletes’ performance. Convolutional neural networks are used to automatically derive the necessary position information and identify an athlete’s swimming style.
Computer vision applications are able to detect and categorize strokes (e.g. in tennis). Stroke recognition provides instructors, coaches, and players with tools for game analysis and more effective development.
In team sports, motion analysis techniques can be used to extract trajectory data from video content. That gives useful analytics for improving team lineups and game strategy.
Manufacturing
Computer vision is a critical component of smart manufacturing. It allows, for example, automated inspection of personal protection such as masks and helmets. On construction sites and factories, computer vision helps monitor compliance with safety procedures.
Smart camera applications provide a scalable way to integrate automated visual inspection and quality control of manufacturing and assembly lines. Robotic arms with object detection significantly outperform humans in terms of accuracy, speed, productivity, and reliability.
Retail
Deep learning algorithms can monitor customer traffic in retail stores. They can identify time spent at different locations and queuing, determine the best spots for free sampling distribution, and evaluate the quality of service. All this data is used for customer behavior analysis to optimize retail store design, and objectively measure key performance indicators across many locations. Computer vision algorithms are also helpful for security. They can automatically analyze the environment to detect suspicious activity such as accessing restricted areas or theft.
Conclusion
Deep learning for computer vision is an extremely promising research area that allows to solve a wide range of real-world problems and simplify various processes in healthcare, sports, transportation, retail, manufacturing, etc.
The field is developing, and some of the directions that have the most potential include the following tasks:
- Integrating a text or object into an image.
- Upscaling images.
- Removing irrelevant objects from images (like cables or road signs in urban landscapes).
- Transferring styles.
Serokell offers a range of custom ML solutions that include deep learning technologies. Contact us to discuss your goals.
Useful resources for further study
In this blog post, we have outlined the basic concepts related to the application of deep learning in the computer vision field.
To learn in more detail about deep learning and its architectures, take a look at our guide to DL and neural networks.
If you wish to dive deeper into the subject, you can also check out the following resources:




.jpg)
.jpg)
.jpg)