
Predicting customer behavior, consumer demand or stock price fluctuations, identifying fraud, and diagnosing patients – these are some of the popular applications of the random forest (RF) algorithm. Used for classification and regression tasks, it can significantly enhance the efficiency of business processes and scientific research.
This blog post will cover the random forest algorithm, its operating principles, capabilities and limitations, and real-world applications.
What is a random forest?
A random forest is a supervised machine learning algorithm in which the calculations of numerous decision trees are combined to produce one final result. It’s popular because it is simple yet effective.
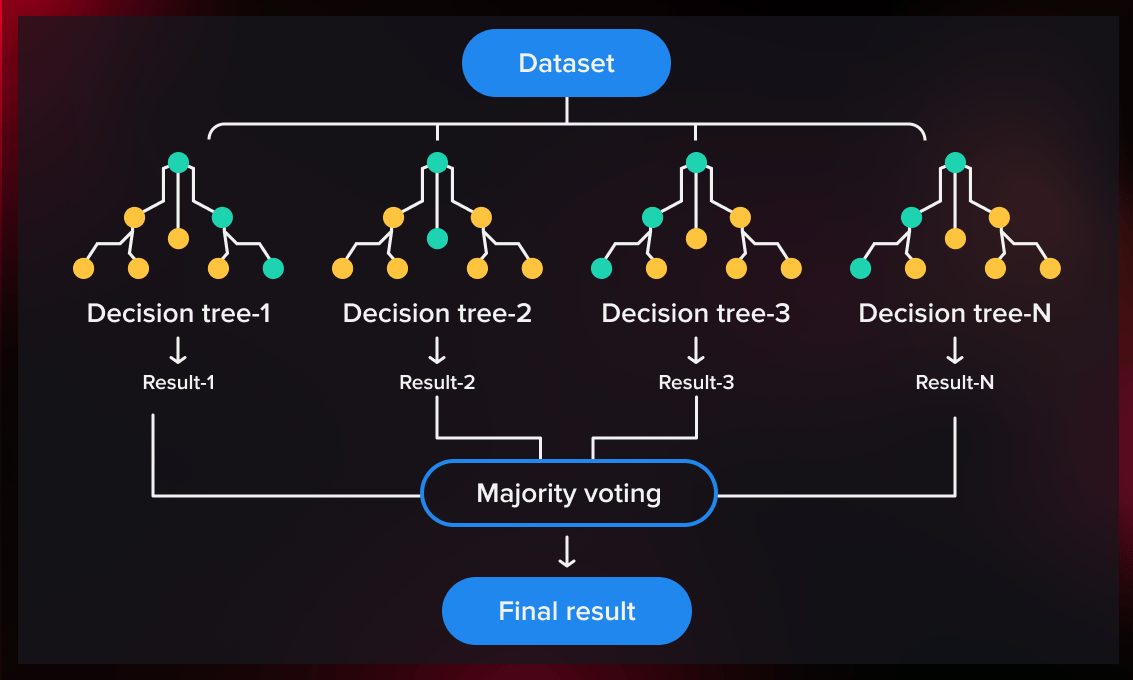
Random forest is an ensemble method – a technique where we take many base-level models and combine them to get improved results. So to understand how it operates, we first need to look at its components – decision trees – and how they work.
Decision trees: the trees of random forests
Decision trees are a category of machine learning algorithms used for tasks like classification and regression. These algorithms take data and create models that are similar to decision trees that you might have encountered in other fields.
A decision tree model takes some input data and follows a series of branching steps until it reaches one of the predefined output values.
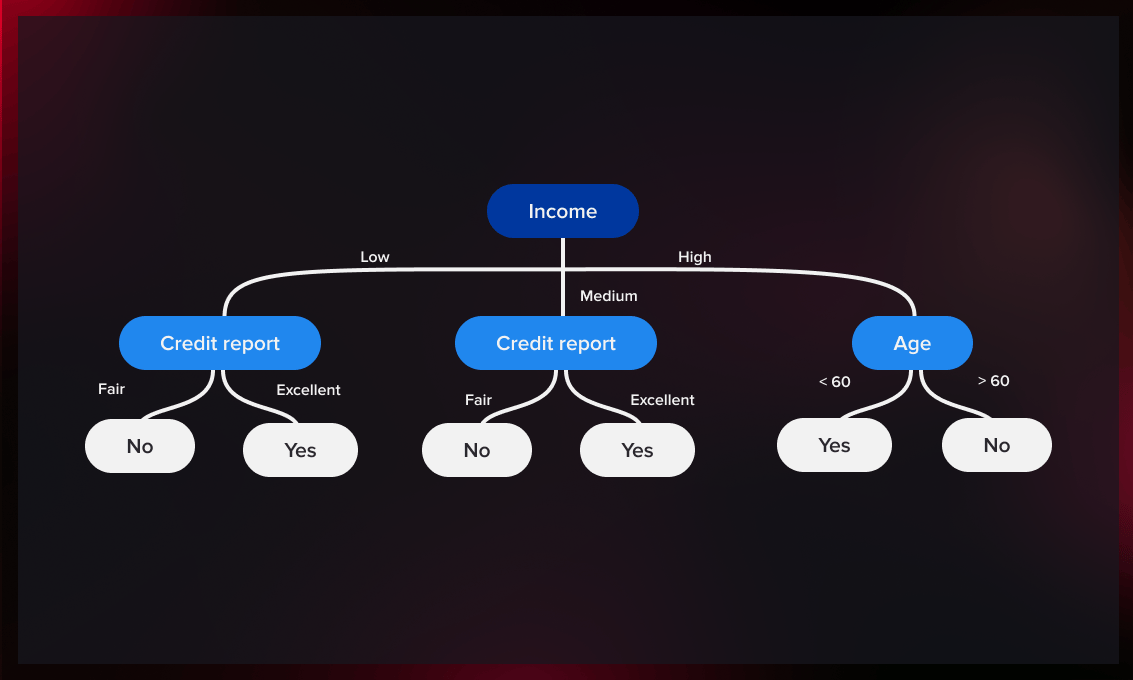
Some of the most common types of this algorithm are classification and regression trees.
Classification trees
The technique is used to determine which “class” a target variable is most likely to belong to. Thus, you can determine who will or won’t subscribe to a streaming platform or who will drop out of college, and who will finish their studies successfully.
Regression trees
A regression tree is an algorithm where the target variable is not a predefined value. An example of a regression problem is the prediction of house prices – a continuous variable. This is determined by both continuous parameters such as square footage and categorical factors such as the type of home, location of the property, etc.
When the dataset must be separated into mutually exclusive classes, like black or white, yes or no, classification trees are commonly utilized. When the response variable is continuous such as sales volumes or daily temperatures, regression trees are employed.
To learn more about this topic, you can watch the video below.
Training a decision tree
So that we know on which feature to split first and how, the relevance and importance of each feature must be determined.
This is done by our splitting function of choice. In broad terms, it usually tries to maximize information gain – the information gained (or entropy reduced) by each split done on the dataset.
If you’re not familiar with those terms, you can think of the algorithm as trying to split the data to create the most uniform groups on each split.
After that, we recursively split the dataset until we have reached a certain stopping condition. Frequently, the condition is minimum count – the amount of entries in the dataset for the leaf we want to create.
The resulting tree is our model.
In this video, you will find a more detailed explanation of how decision trees are trained.
How does the random forest algorithm work?
Now that we know what a single decision tree is and how it can be trained, we are ready to train a whole forest of them.
Let’s see how the process happens step-by-step.
1. Split the dataset into subsets
A random forest is an ensemble of decision trees. To create many decision trees, we must divide the dataset we have into subsets.
There are two main ways to do this: you can randomly choose on which features to train each tree (random feature subspaces) and take a sample with replacement from the features chosen (bootstrap sample).
2. Train decision trees
After we have split the dataset into subsets, we train decision trees on these subsets. The process of training is the same as it would be for training an individual tree – we just make a lot more of them.
It might be interesting to know that this training process is very scalable: since the trees are independent, you can parallelize the training process easily.
3. Aggregate the results
Each individual tree contains one result that depends on the tree’s initial data. To get rid of the dependence on the initial data and produce a more accurate estimation, we combine their output into one result.
Different methods of aggregating the results can be used. For example, in the case of classification, voting by performance is used quite often, whereas for regression, averaging models are applied.
4. Validate the model
After we complete the training procedure with the training data and run the tests with the test dataset, we perform the hold-out validation procedure. This involves training a new model with the same hyperparameters. In particular, these include the number of trees, the pruning and training procedures, the split function, etc.
Note that the objective of training is not to find the specific model instance that is most suitable for us. The goal is to develop a general model without pretrained parameters and find the most appropriate training procedure in terms of metrics: accuracy, overfitting resistance, memory, and other generic parameters.
The hold-out validation procedure is required for model evaluation purposes only. Another common method to avoid overfitting is k-fold cross-validation. It is based on the same principle: validation of hyperparameters using metrics and overfitting resistance, followed by training a new model on the entire dataset.
Check out this post to learn more how holdout validation works.

After we have trained the model, we can then predict outcomes for new events that have yet to occur (e.g., loans for the financial sector or diseases for medicine).
RF hyperparameters
In the process of training, you will, most likely, experiment with different hyperparameters for the random forest algorithm to see which brings the best result.
Random forests may be defined by a variety of elements, such as the number of trees in the forest or the data subset creation procedure.
Other RF hyperparameters concern the decision trees used in the forest. For example, the maximum number of characteristics utilized to divide a node, the stopping condition for the algorithm, or the split function used (Gini impurity or entropy) .
Decision trees vs. random forests
A decision tree model takes some input data and follows a series of if-then steps until it reaches one of the predefined output values.
In contrast, a random forest model is a combination of many individual decision trees, trained on subsets of initial data.
As an example, if you wanted to use a single decision tree to predict how often certain customers would use a particular service provided by the bank, you would collect data on how often clients have visited the bank in the past and what services they have used. You would specify certain characteristics that determine the customer’s choice. The decision tree would create rules that help you predict whether or not a customer will use the services.
If you put the same data into a random forest, the algorithm would create several trees from randomly selected groups of customers. The output of the forest would be the combination of the individual results of all those trees.
| Decision tree | Random forest |
|---|---|
| An algorithm that generates a tree-like set of rules for classification or regression. | An algorithm that combines many decision trees to produce a more accurate outcome. |
| When a dataset with certain features is ingested into a decision tree, it generates a set of rules for prediction. | Builds decision trees on random samples of data and averages the results. |
| High dependency on the initial data set; low accuracy of prediction in the real world as a result. | High precision and reduced bias of results. |
| Prone to overfitting because of the possibility to adapt to the initial data set too much. | The use of many trees allows the algorithm to avoid and/or prevent overfitting. |
Benefits and challenges of the random forest algorithm
Random forest has its advantages and drawbacks. The former, however, outweigh the latter.
Benefits
- Cost-effective. RF is much cheaper and faster to train when compared to neural networks. At the same time, it doesn’t suffer much in accuracy. For this reason, random forest modeling is used in mobile applications, for example.
- Robust against overfitting. If one tree makes an inaccurate prediction due to an outlier in its training set, another will most likely compensate for that prediction with the opposite outlier. Thus, a set of uncorrelated trees performs better than any of the individual ones taken separately.
- High coverage rates and low bias. The above makes random forest classifier ideal for situations where there may be some missing values in your dataset or if you want to understand how much variance there is between different types of data output (e.g., college undergraduates who are likely to finish their studies and leave, proceed to master’s degree, or drop out).
- Applicable for classification and regression. RF has proven equally accurate results for both types of tasks.
- Can handle missing values in features without introducing bias into predictions.
- Easy to interpret. Every tree in the forest makes predictions independently, so you can look at any individual tree to understand its prediction.
Challenges
There are some challenges associated with random forest classifiers as well:
- Random forests are more complicated than decision trees, where just following the route of the tree is enough for making a decision.
- The RF classifiers tend to be slower than some other types of machine learning models, so they might not be suitable for some applications.
- They work best with large datasets and when there is sufficient training data available.
Applications of random forest
This algorithm is used to forecast behavior and outcomes in a number of sectors, including banking and finance, e-commerce, and healthcare. It has been increasingly employed thanks to its ease of application, adaptability, and ability to perform both classification and regression tasks.
Healthcare
In healthcare, RFs open up many possibilities for early diagnosis that are not only cheaper than neural networks, but also solve the ethical problems associated with NN. Despite their impressive performance in most clinical prediction tests, neural networks are difficult to implement in the real clinical world due to the fact that they are black-box models and thus lack interpretability.
While decision making in neural networks is not traceable, it is completely transparent in the case of random forest. Medical professionals can understand why the random forest makes the decisions it does. For example, if someone develops adverse side effects or dies from treatment, they can explain why the algorithm made that decision.
Finance and banking
In the financial sector, random forest analysis can be employed to predict mortgage defaults and identify or prevent fraud. Thus, the algorithm determines whether the customer is likely to default or not. To detect fraud, it can analyze a series of transactions and determine whether they are likely to be fraudulent.
Another example. It is possible to train RFs to estimate the probability of a customer terminating their account based on transaction history and regularity. If we apply this model to the population of all existing users, we can forecast churn over the next few months. This provides the company with extremely useful business information that helps identify bottlenecks and build a long-term partnership with customers.
If you work in finance, learn about the fintech development services our expert team provides.
Stock market
Predicting future stock prices based on historical data is an important RF application in the financial market. Random forests have proved to perform better than any other prediction tool for stock pricing, option pricing, and credit spread forecasting.
How do you apply RFs in these cases? For instance, if you were analyzing the profitability of various stocks, you might divide them into groups based on their market value and then compare their ROIs. You would keep splitting these groups until each contained only one item or had no items left. This process is known as recursive partitioning. Read this article to learn about the practical implementation of the algorithm written in Python to predict stock prices.
E-commerce
The algorithm has been increasingly used in e-commerce to forecast sales.
Let’s say that you’re trying to predict whether or not an online shopper will buy an item after seeing an ad on Facebook. In this case, there may only be a small number of shoppers who ended up buying after seeing the ad (maybe 5% bought), but there were many more shoppers who didn’t end up buying (maybe 95% didn’t).
Using the random forest classifier on customer data such as age, gender, personal preferences, and interests would allow you to predict which customers would buy and which wouldn’t with relatively high accuracy. And by targeting an advertising campaign to likely buyers, you’ll optimize your marketing spend and increase sales.
The history of random forest
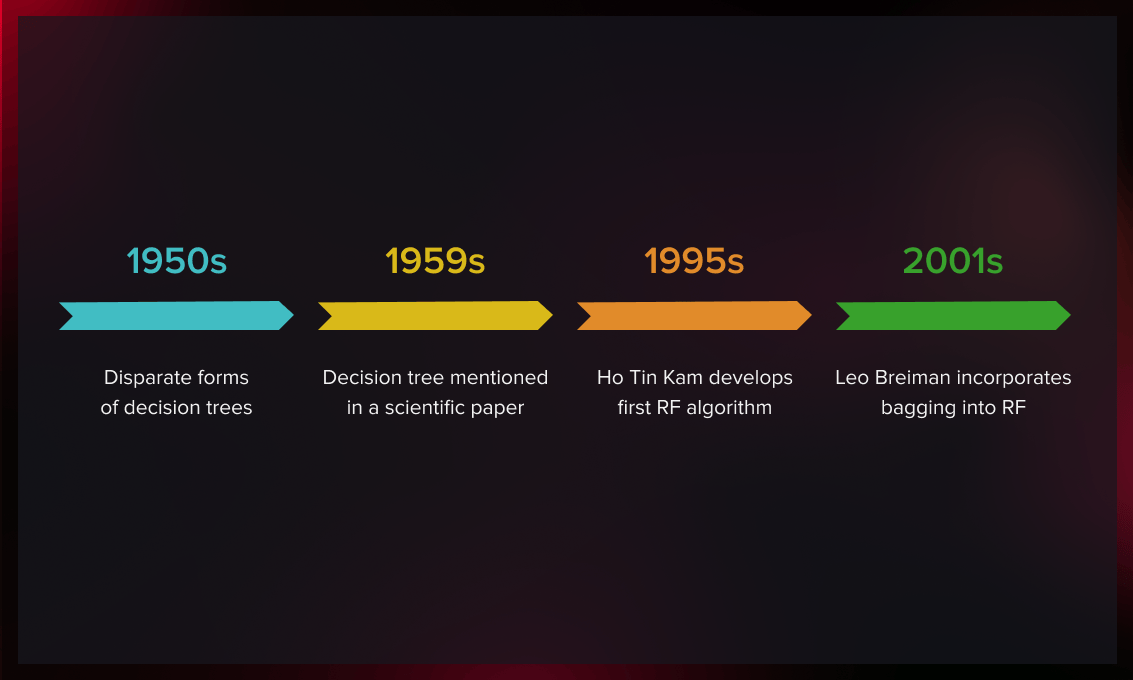
Non-ensemble decision trees have existed in various forms since the 1950s. However, no single researcher can be credited for their discovery. In 1959, a British statistician mentioned in a paper a decision tree as a tool for classifying biological organisms.
The statistics community gradually developed this algorithm throughout the coming decades.
It was not until 1995, that Tin Kam Ho, a Hong Kong and American researcher, developed the first random forest algorithm. To reduce the correlation between estimators, she applied a method in which each tree is exposed to a fraction of the full feature set but still trained with the entire training set.
In 2001, American computer scientist Leo Breiman improved Ho’s algorithm by incorporating bagging. Breiman’s suggested to train each estimator using subsamples from the original training set.
Nowadays, Breiman's version is used in most recent implementations of the random forest method. You can read Leo Breiman's paper here.
Random forest has seen a number of improvements over the past years.
In 2004, Robnik-Šikonja decreased the correlation between trees without them losing explanatory strength by using several attribute evaluation measures instead of just one. He also introduced another improvement by changing the voting method from majority voting to weighted voting. Internal estimations are used in this voting process to find the cases that are most similar to the one being labeled. The strength of the votes of the associated trees is then weighted for these close situations.
Later Xu et al. came up with a hybrid weighted RF algorithm to identify high-dimensional data. Since several decision tree algorithms, such as C4.5, CART and CHAID, were used to generate the trees in RF, it was called hybrid. Eight high-dimensional datasets were used to evaluate the hybrid RF. Compared to the traditional RF, the hybrid technique regularly outperformed the old method. Thus not only is the random forest classifier widely used, but it is also an evolving method whose efficiency is increasing day by day.
Key takeaways
- Random forest is an ML ensemble algorithm based on aggregation of several decision trees. It is accurate, efficient, and relatively quick to create.
- RF overcomes the drawbacks of the decision tree algorithm by reducing the overfitting of the dataset and improving accuracy.
- Due to its simplicity of use and accuracy of results, it has been one of the most popular classification algorithms among data scientists for decades.
- It is used in a variety of domains, such as finance and banking, e-commerce, healthcare, etc. The algorithm is employed to predict things like consumer activity, risks, stock prices, and the likelihood of developing disease symptoms.
Random forest classifiers handle large datasets. Since not all data needs to be processed, they work with random samples of data without sacrificing accuracy. Also, you can easily add or remove features from the model that are not useful for predicting your outcome variables.
To learn more about some of the machine learning aspects mentioned in this post, check out these articles on our blog:
- Classification Algorithms: A Tomato-Inspired Overview
- Regression Analysis Overview: The Hows and The Whys
- Machine Learning Algorithm Classification for Beginners
- Where to Find the Best Machine Learning Datasets
If you would like to be updated whenever we release new articles about machine learning and data science, follow us on Twitter.

.jpg)


.jpg)
.jpg)
.jpg)