
In this article, we’ll explore how Bidirectional Encoder Representations from Transformers (BERT) works, and why it’s called a universal tool for solving dozens of natural language processing tasks
What is BERT?
BERT, which stands for Bidirectional Encoder Representations from Transformers, is a deep learning model introduced by Google in 2018 to help machines understand the complex nuances of human language. Thanks to its Transformer-based architecture, it can grasp the deeper meaning and context of words in the text. This makes BERT especially effective at tasks like text classification, translation, question answering, and language inference.
Natural language often contains words or phrases with multiple possible meanings. BERT analyzes the surrounding context—the words and sentences that come before and after—to determine the meaning. In the past, language models processed text either left-to-right or right-to-left. By reading text in both directions at once, BERT can better understand the full context of each word.
The model comes in two main versions: base and large. The architecture is the same for both, but they differ in the number of parameters they use. BERT large has over three times more parameters to fine-tune compared to BERT base.
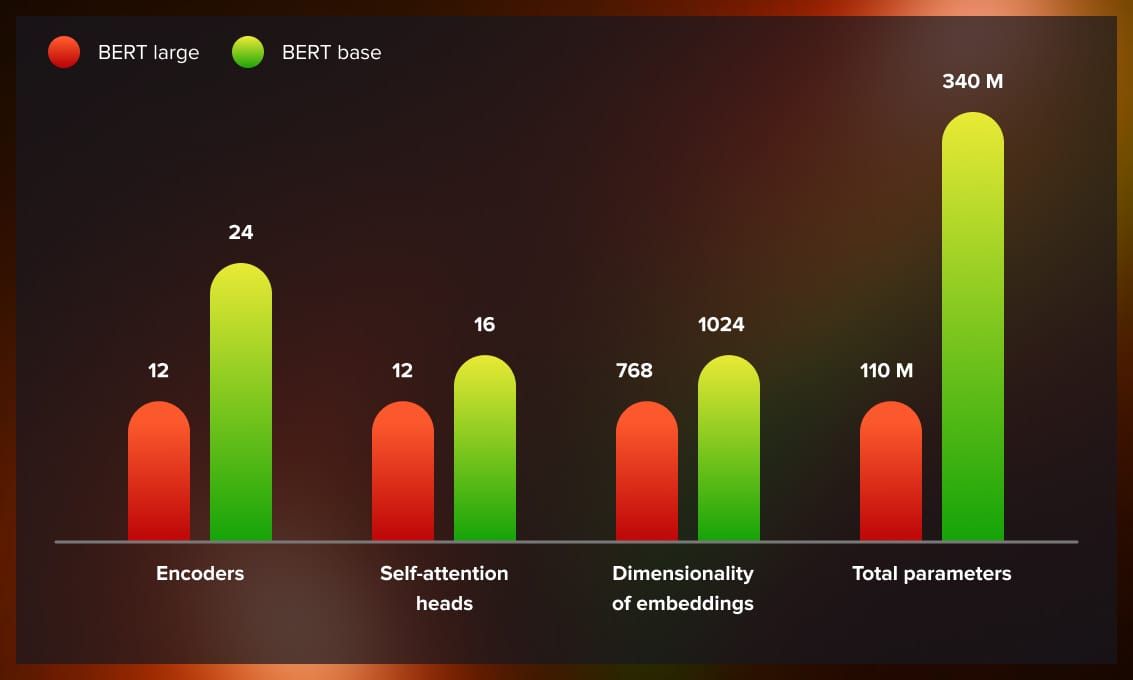
What is the difference between BERT and Transformer?
Introduced in 2017, the Transformer is a neural network architecture that uses self-attention mechanisms to handle sequences without relying on recurrence.
Built on the Transformer architecture, BERT (introduced in 2018) focuses on pre-training large-scale language models (LLMs) to develop deep bidirectional understanding of text.
The main difference between BERT and the Transformer model is their purpose. The Transformer model generates sequences of output from given input. BERT’s aim is to produce high-quality text representations that can be applied to various NLP tasks.
| Purpose | Directionality | Training Task | |
| Transformer | Designed to improve sequence processing, such as machine translation, by avoiding recurrent layers, leading to faster training. | Can be unidirectional or bidirectional, depending on how it's applied. | Originally focused on machine translation. |
| BERT | Pre-trains deep bidirectional representations of text, which can be fine-tuned for various NLP tasks. | Explicitly bidirectional, as it processes input text both left-to-right and right-to-left. | Pre-trained using a "masked language model" task, predicting missing tokens in a sentence. |
Learn more about Transformers in ML in our blog post.
What is BERT used for?
BERT can be used for a variety of language-based tasks, such as:
- Sentiment analysis: For example, determining whether movie reviews are positive or negative.
- Question answering: Helping chatbots respond to user questions accurately.
- Text prediction: Suggesting next words and sentences in a text.
- Text generation: Creating entire articles from several starting sentences.
- Summarization of long documents, for example, legal contracts.
- Polysemy resolution: Figuring out which meaning of a word applies based on the surrounding text (e.g. “bank” as a financial organization or a “river bank”).
How does BERT work?
BERT is based on the encoder mechanism analyzing sequences of tokens. These tokens are converted into vectors, which are then passed through a neural network, generating contextualized representations for each token.
Traditional language models only predict the next word in a sequence, which prevents them from grasping the broader context. BERT uses two training techniques: the Masked Language Model (MLM) and Next Sentence Prediction (NSP) that allow it to understand the meaning of both individual words and the relationship between sentences.
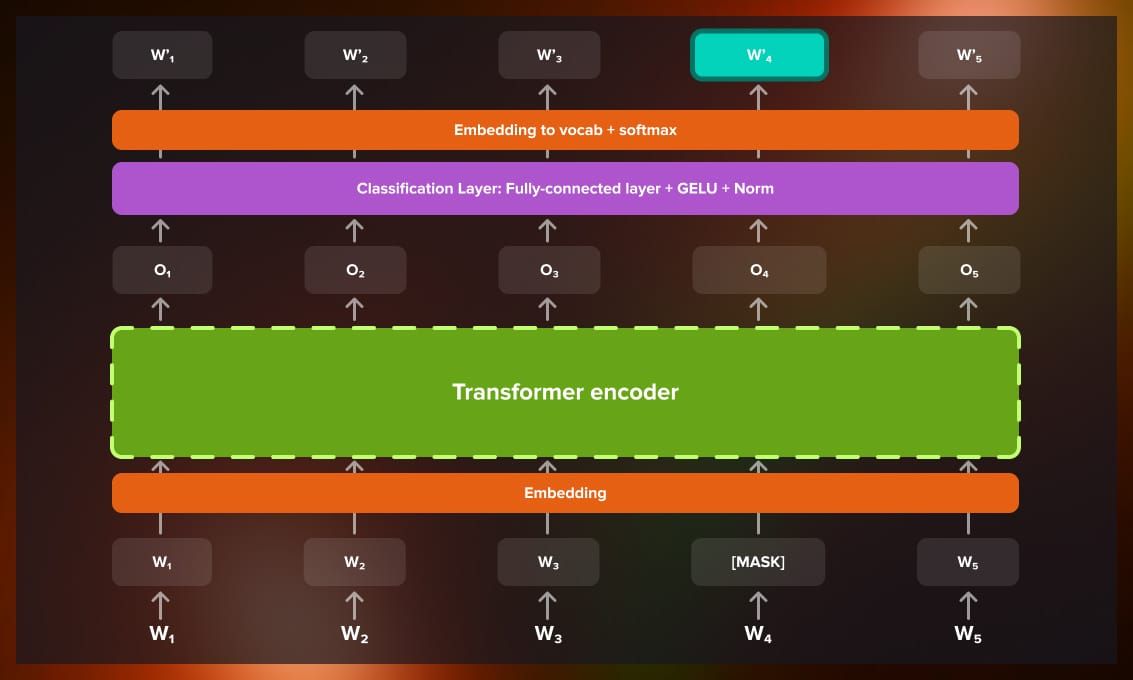
Masked Language Model (MLM)
In BERT’s pre-training, around 15% of the words in a sentence are randomly masked, and the model is trained to guess those missing words based on the context provided by the remaining words.
Here’s how it works:
- Masking words: BERT hides certain words and replaces them with a special token, [MASK].
- Guessing the hidden words: The model then uses the words around the masked token to predict what the missing word is, learning to better understand the sentence’s overall context.
- Learning process: BERT uses a classification layer over the encoder’s output to predict the masked words. These predictions are transformed into vocabulary space using an embedding matrix, and the SoftMax function generates a probability distribution for each masked word.
- Focused training: BERT focuses on predicting the masked words, rather than unmasked ones, which allows it to understand meaning in context.
Next Sentence Prediction (NSP)
BERT is trained to figure out whether one sentence logically follows another. For this, it takes the output from a special token, [CLS], and runs it through a classification layer. This layer turns the information into a 2x1 vector, which is then processed using the SoftMax function to calculate the probability that the second sentence follows the first.
The model is taught to understand sentence relationships using two types of input:
- Half the time, the second sentence actually follows the first in the original text.
- The other half of the time, the second sentence is randomly picked and unrelated to the first.
To help the model figure out which sentences are related, the input goes through some pre-processing:
- A [CLS] token is added to the start of the first sentence.
- A [SEP] token is added at the end of each sentence to mark where they stop.
- Each token is given a sentence embedding to show whether it belongs to Sentence A or Sentence B.
- Positional embeddings are also added to show where each token is in the sequence.

After the input is processed, BERT predicts if the second sentence logically follows the first by using the [CLS] token output and applying SoftMax to determine the likelihood.
Fine-tuning BERT
After BERT has been pre-trained and learned the meanings of words and their relationship in context, it is fine-tuned to tackle specific tasks.
BERT can be easily adapted for different tasks thanks to its self-attention mechanism. One of its advantages is that it can look at a sentence from both directions to better capture relationships between sequences. Unlike older models, BERT handles both stages simultaneously.
Now, let’s look at how BERT is fine tuned for specific tasks.
Sentence pair classification
This task involves understanding the relationship between two sequences, often for natural language inference (determining if one sequence logically follows the other) and similarity analysis (measuring how closely two sequences match).
In these scenarios, both sequences are passed into BERT. Usually, the output from only the [CLS] token is used for classification, as it contains the main information about how the sentences relate. Other token outputs are not needed for this task in most cases.
Question answering
In this task, BERT finds an answer in a paragraph in response to a question. The answer is usually identified by the start and end positions of specific tokens in the text.
The model takes the question and the paragraph as input and outputs token embeddings for each. To find the start of the answer, BERT calculates the scalar product between each token’s embedding and a trainable vector (Tₛₜₐᵣₜ). These values are then passed through a Softmax function to generate probabilities, and the token with the highest probability is chosen as the start. A similar process using another vector (Tₑₙ𝒹) discovers the end token. Training adjusts these calculations through backpropagation to improve accuracy.
Single sentence classification
This task involves passing a single sentence through BERT to handle sentiment analysis and topic classification. This process is rather straightforward: BERT uses the [CLS] token’s output to make the final classification, just like it does for sentence pair tasks.
Single sentence tagging
In tasks like Named Entity Recognition (NER), the goal is to tag each word in a sentence with its appropriate label (such as identifying names, places, etc.). BERT generates embeddings for each token in the sentence, and these embeddings are individually classified to map the tokens to their relevant categories, except for the special tokens [CLS] and [SEP].
BERT variations
BERT is an open-source model, so lots of scientists and research groups keep fine-tuning BERT with the help of supervised learning to adapt it to specific tasks. Here are some of the best known examples.
- PatentBERT: Built specifically for patent classification.
- DocBERT: Used for classifying documents.
- BioBERT: Designed for mining biomedical texts.
- VideoBERT: Combines visual and language models to learn from unlabeled YouTube data.
- SciBERT: Specializes in scientific texts.
- G-BERT: Uses medical codes and graph neural networks to help make medical recommendations.
- TinyBERT (by Huawei): A BERT version that’s 7.5 times smaller and 9.4 times faster than the original one.
- DistilBERT (by Hugging Face): A leaner, more efficient version of BERT with some parts of the original architecture removed to improve speed.
- ALBERT: A streamlined version that uses less memory and trains faster.
- SpanBERT: Improves BERT’s ability to predict spans of text.
- RoBERTa: Trained on a larger dataset and for a longer time to boost performance.
- ELECTRA: Creates high-quality text representations.
What do BERT and GPT have in common?
BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pretrained Transformer) are both deep learning models based on the Transformer architecture. Along with this key point, they have several other similarities.
Pretraining and fine-tuning
Pretrained on large datasets: Both models are pretrained on vast amounts of text data. During pretraining, they learn a general understanding of language patterns, which is later fine-tuned for specific downstream tasks (e.g., sentiment analysis, question answering, text generation).
Self-supervised learning: Both are trained using unsupervised or self-supervised methods, meaning they are trained on raw text data without needing labeled data. BERT uses a masked language model (MLM) objective, while GPT uses an autoregressive language model (LM) objective.
Attention mechanism
BERT and GPT rely on self-attention mechanisms to encode input sequences. This allows them to focus on relevant parts of the input and capture long-range dependencies in text data.
Tokenization
Both models use subword tokenization techniques (e.g., WordPiece in BERT, Byte-Pair Encoding in GPT). This allows them to handle rare or out-of-vocabulary words by combining subwords into complete words during inference.
Transformer layers
BERT and GPT use multiple layers of transformer blocks, which consist of attention heads, normalization, and feed-forward networks. As more layers are stacked, the models learn more complex language representations.
Contextual word representations
Both provide contextual embeddings for words, meaning they consider context when generating word representations. For example, the word “bank” will have different embeddings in the sentences “I went to the bank to deposit money” versus “The river bank is flooded.”
What is the difference between BERT and GPT?
BERT and GPT differ in design and use cases.
BERT is bidirectional, meaning it understands the whole context of a sentence before trying to make sense of it. BERT is trained by hiding some words in a sentence and then trying to predict them based on the surrounding words.
The model is good at tasks where understanding context is key, like answering questions, identifying entities (e.g., names of people or places), or understanding the sentiment of a sentence.
GPT is unidirectional, meaning it only looks at the words before the one it’s predicting. This makes GPT great at generating naturally flowing text: writing essays, generating dialogue, summarizing text, or even coding.
In other words, BERT is a super reader that understands language in depth, while GPT is more like a creative writer.
Conclusion
BERT’s ability to simultaneously process input from both directions allows it to capture context more effectively than traditional models. It uses the Masked Language Model and Next Sentence Prediction, which make it an excellent tool for sentiment analysis, question answering, and text classification. Since its launch, various fine-tuned versions for specialized fields have emerged, and BERT continues to evolve thanks to its open-source nature and contributions from the developer community.

.jpg)
.jpg)



