
Passport checks at airports, automatic turnstiles in office centers, signature verification – all these tasks require face or object recognition. Historically, deep learning algorithms use a lot of labeled training data for simple tasks like identifying objects in photos or recognizing faces. But in the above situations, we normally do not possess a large variety of photos for each person for training the AI. Therefore, we need an ML algorithm that would be able to perform recognition with a limited number of training examples. This is where one-shot learning comes into play.
In this blog post, we explain what one-shot learning is, how it works, and what practical applications it has.
What is one-shot learning?
One-shot learning is an ML-based object classification algorithm that assesses the similarity and difference between two images. It’s mainly used in computer vision.
The goal of one-shot learning is to teach the model to set its own assumptions about their similarities based on the minimal number of visuals. There can be only one image (or a very limited number of them, in which case it is often called few-shot learning) for each class. These examples are used to build a model that can then make predictions about further unknown visuals.
For instance, to distinguish between apples and pears, a traditional AI model would need thousands of images taken at various angles, with different lighting, background, etc. In contrast, one-shot learning doesn’t require many examples of each category. It generalizes the information it has learned through experience with the same-type tasks by inferring similar objects and classifying unseen objects into their respective groups.
How does one-shot learning work?
If we need to add new classes for data classification to a traditional neural network, this presents a challenge. In this case, the neural network needs to be updated and retrained, which can be either expensive, or impossible due to lack of sufficient data and/or time.
But for tasks such as face recognition, we don’t always need to assign faces into predefined classes (person A, person B, person C, etc.). What we need is just to tell whether the person in front of the border gate counter is the same as in the presented ID. This means that the problem we have to solve is one of evaluating differences rather than classifying.
Sticking to the example of border control, we have two images: camera input and the person’s passport photo. The neural network evaluates the degree of similarity between them.
Let’s take a look at how it is actually done and what types of neural networks are needed.
Matching networks for one-shot learning
One-shot learning for computer vision tasks is based on a special type of convolutional neural networks (CNNs) called Siamese neural networks (SNNs). Classic CNNs adjust their parameters throughout the training process to correctly classify each image. Siamese neural networks are trained to evaluate the distance between features in two input images.
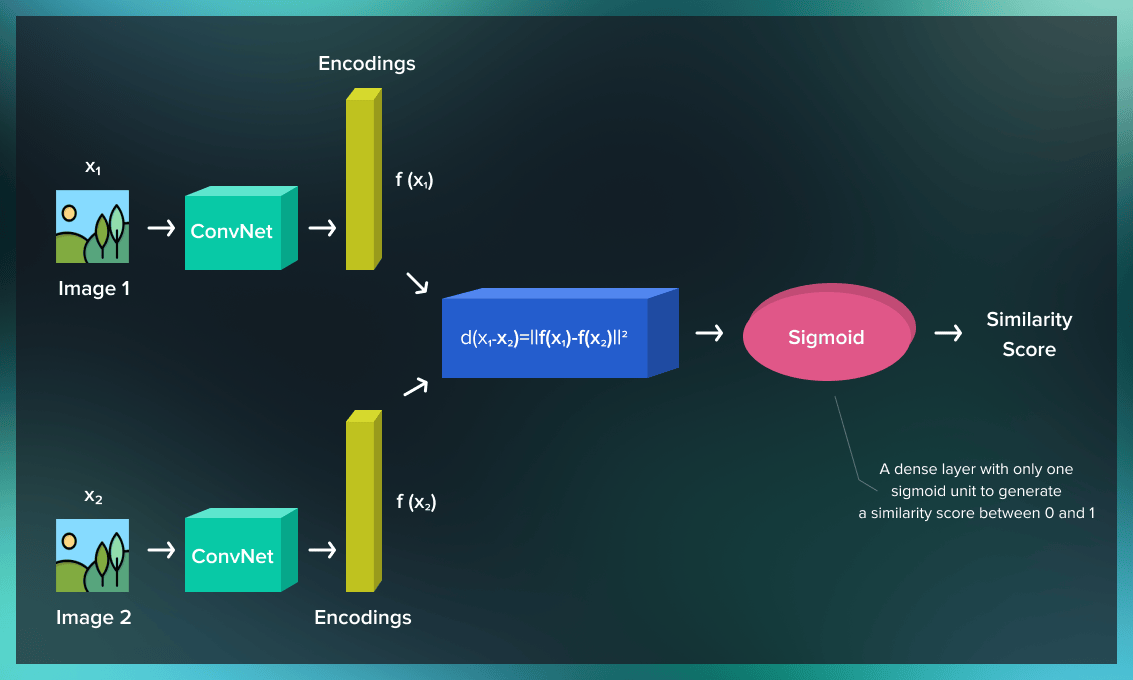
Siamese neural networks run the inputs through two identical instances of the same network. Both are trained on the same data set and then combined to produce an output as a function of their inputs.
Each of the two branches of this convolutional network is responsible for learning the features of one image, while a part with the differentiating layer evaluates how those features relate to each other across frames. The differentiating layer checks whether similar features were learned from both images.
Training an SNN for one-shot learning involves two stages: verification and generalization.
In the verification stage, the triplet loss function is used. The model receives three images – an anchor, a positive image, and a negative image. The encoded features of the first and second images are very similar, whereas the features of the third image differ. To achieve better results for the model training, the triplets of positive, negative, and anchor images must look relatively similar, to help the model learn on the “hard-to-recognize” examples.

In the generalization stage, the model is trained to evaluate the probability that the input pairs belong to the same class. At this step, it’s essential to provide the model with images where the difference is very difficult to recognize. By increasing the complexity of the estimations, we speed up the educating process of the model.

Upon the completion of these two steps, the model is ready to use: it’s now able to compare new images against each other.
Benefits and limitations of Siamese neural networks
When working with these models, keep the following in mind.
Advantages of SNNs
-
When it comes to recognizing images, faces, and other objects with strong similarities, Siamese neural networks have been shown to outperform other types of neural networks in terms of speed and accuracy.
-
The Siamese networks have the advantage that, like other NNs, they can be initially trained on large datasets but, unlike other NNs, they do not need to be seriously retrained to detect new classes.
-
In addition, as both outputs share the same parameters, the model can achieve better generalization performance especially when dealing with similar but not identical objects.
Challenges of SNNs
-
The main disadvantage of Siamese networks is that they require much more computation power than other types of CNNs since there are twice as many operations needed to teach two models during training.
-
There is also a large increase in memory requirements.
The main idea of SNNs is to reconstruct the original objects into a latent space where you can force them to meet some predefined requirements. CNN in images is the main application area for one-shot learning. However, the networks do not necessarily have to be convolutional. Besides, there are no limitations on the type of problem, as long as the constraints can be specified in the latent space.
Note that other neural networks are also successfully used in one-short learning for image and video recognition. These include memory augmented NNs, spiking neural networks, Bayesian NNs, etc.
What is the difference between zero-shot, one-shot learning, and few-shot learning models?
Apart from one-shot learning, there exist other models that require just several examples (few-shot learning) or no examples at all (zero-shot learning).
Few-shot learning is simply a variation of one-shot learning model with several training images available.
The goal of zero-shot learning is to categorize unknown classes without training data at all. The learning process here is based on the metadata of the images, i.e. the features relevant for the image. The process is similar to the human cognitive process. Say, you read a detailed description of a giraffe in a book. There’s a high chance that you will be able to recognize it in a photo or when you see it in the real world.

Applications
One-shot learning algorithms have been used for tasks like image classification, object detection and localization, speech recognition, and more.
The most common applications are face recognition and signature verification. Apart from airport checks, the former can be used, for example, by law enforcement agencies to detect terrorists in crowded places and at mass events such as sports games, concerts, and festivals. Based on surveillance cameras’ input, AI can identify people from police databases in the crowd. This technology is also applicable in banks and other institutions where they need to recognize the person from their ID or a photo in their records. The same process works for signature verification.
One-shot learning is essential for computer vision, notably for drones and self-driving cars to recognize objects in the environment.
Another area is cross-lingual word recognition, where one-shot learning is applied to identify unknown words in the translation language.
It can also be effectively used for detecting brain activity in brain scans.
Latest development: ‘less than one’-shot learning
In 2020, MIT researchers Ilia Sucholutsky and Matthias Schonlau published a paper about ‘less than one’-shot learning. The idea behind this research is amazing. The researchers are trying to design a model that can identify more objects than the number of training examples. This research has the potential of changing the entire landscape of machine learning.
This method uses “soft labels” for training. Instead of telling the AI model that image 1 represents an orange, the researchers provide the system with an estimation based on a probability range. For example, this image is 70% orange, 20% grapefruit, and 10% apple. Thus, soft labels capture some shared features. If engineered properly, soft labels could make predictions about a large number of categories with just two examples.
‘Less than one’-shot learning would make AI more accessible to businesses. Overall, this would be a new page in the development of AI, where artificial intelligence algorithms work in the same way as the human brain.
One-shot learning with memory-augmented neural networks
Another area of current research is using memory-augmented neural networks (MANNs) for one-shot learning.
MANNs are a type of recurrent neural network (RNN). While convolutional neural networks we discussed above have a layer structure, RNNs are based on sequences. These networks have memory where information of previous inputs is stored for the generation of the next output of the sequence.
Memory-augmented neural networks separate computation from memory. They are based on the model called neural turing machine (NTM), in which neural networks’ matching capabilities are combined with the power of programmable computers. The NTM is connected to external memory via a neural network controller.
Research has shown that thanks to the NTM model, MANNs can learn fast and have good generalization capabilities. MANNs can complement the one-shot learning with the knowledge of the logical sequence it lacks. Thus the introduction of this model in widespread use would dramatically increase the quality of forecasts and estimates of NNs and turn a new page in their evolution.
Conclusion
The big advantage of the one-shot learning algorithm is that the classification of images is performed based on their similarity, not on the analysis of a large number of features. This significantly reduces computational costs and time spent on training the model.
In practice, one-shot learning has especially big potential for face recognition anywhere, from the exhibition entrances to the recognition of old manuscripts.
The technology keeps developing. The ‘less than one’-shot learning model and one-shot learning with memory-augmented neural networks are the next step in the development of deep learning and its integration in real life.
Python is a common programming language used for one-shot learning. Serokell offers a range of Python development services to help you make your business more efficient.



.jpg)
.jpg)

