
Clustering in machine learning refers to the task of grouping similar data points together based on certain characteristics. It allows us to facilitate insights and decision-making when large amounts of data are involved.
In this article, we explore the fundamental concepts of clustering algorithms, their various types, pros and cons, and the scenarios in which each works best.
What is clustering?
Clustering is a fundamental technique in unsupervised machine learning, where the goal is to group similar data points together based on certain features or characteristics. The objective of clustering is to identify inherent structures within a dataset without any prior knowledge of labels or categories.
For example, imagine that you’re a data scientist working at a major supermarket chain. To increase sales, you need to provide different kinds of customers with a personalized offer. Cluster analysis will help with customer segmentation. When you start performing the task you don’t know how many different groups, or clusters of customers, you may have.
Clustering algorithms will discover patterns in data. For instance:
- Parents that often buy childcare products.
- Students that only shop in the discounted section.
- Young professionals that are main consumers of ready-made foods and snacks.
- Families that shop big once a week.
Once you have these clusters, you can offer each a personalized discount.
In clustering, data points that are similar to each other are grouped into the same cluster, while those that are dissimilar are placed in different clusters. The similarity between data points is typically measured using distance metrics, such as Euclidean distance or cosine similarity, depending on the nature of the data.
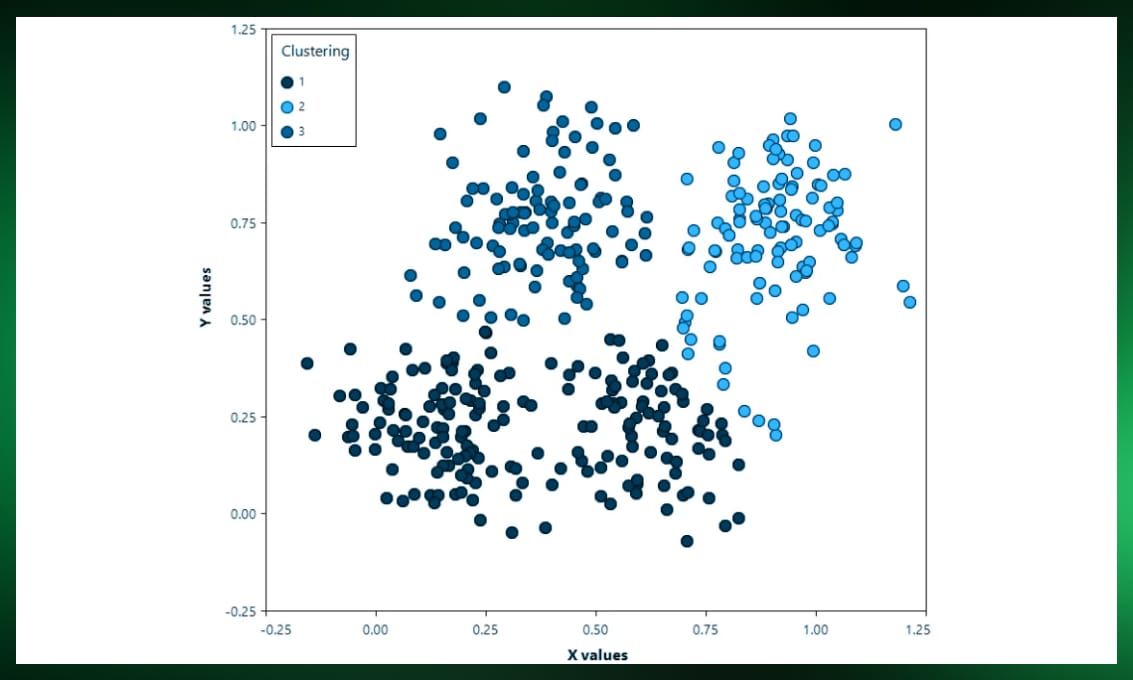
There are various algorithms used for clustering. Some common clustering algorithms include K-means, hierarchical clustering, DBSCAN, and Gaussian mixture models.
Clustering finds applications in various fields such as customer segmentation, anomaly detection, document clustering, image segmentation, and more.
What are clustering algorithms?
Let’s explore some prominent types:
Partitioning methods
Partitioning methods divide data into non-overlapping clusters, with each data point belonging to exactly one cluster. Notable examples include K-Means and K-Medoids algorithms. While K-Means is efficient and straightforward to implement, K-Medoids offers robustness against outliers due to its use of representative points (medoids) within clusters.
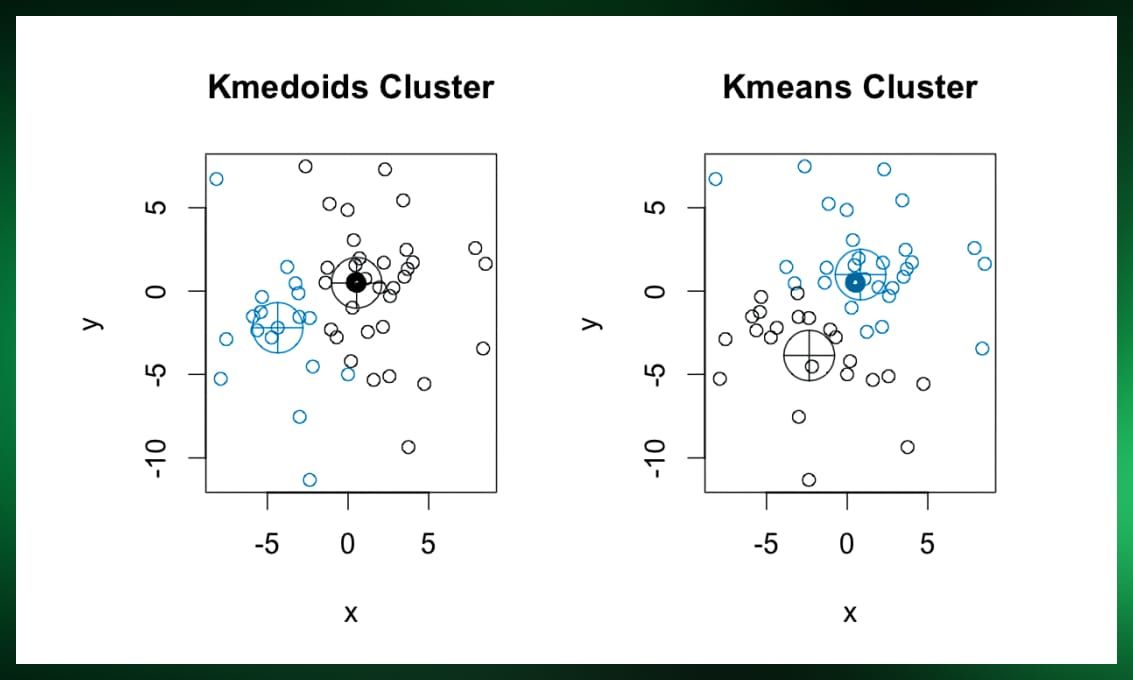
Hierarchical methods
Hierarchical clustering builds a tree-like hierarchy of clusters, either from the bottom up (agglomerative) or top down (divisive). Agglomerative methods iteratively merge similar clusters until a stopping criterion is met, whereas divisive methods recursively split clusters into smaller ones. These methods provide valuable insights into hierarchical structures present in the data, but they can be computationally intensive.
Density-based methods
Density-based clustering, exemplified by algorithms like DBSCAN and OPTICS, groups together points based on their density within the dataset. DBSCAN, for instance, identifies dense regions separated by areas of lower density, making it robust to outliers and capable of detecting clusters of arbitrary shapes.
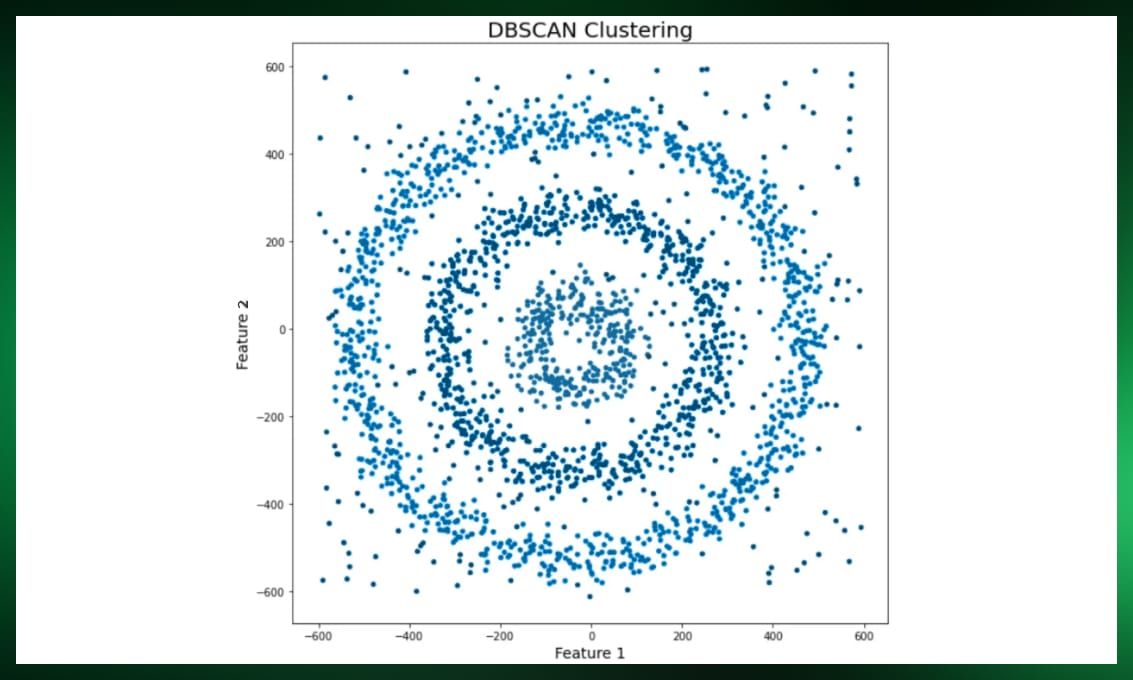
Distribution-based methods
Distribution-based clustering assumes that data points are generated from a mixture of probability distributions. Gaussian Mixture Models (GMM) is a classic example, where clusters are modeled as Gaussian distributions. GMM is effective for capturing complex data distributions but may struggle with high-dimensional data and requires careful initialization.
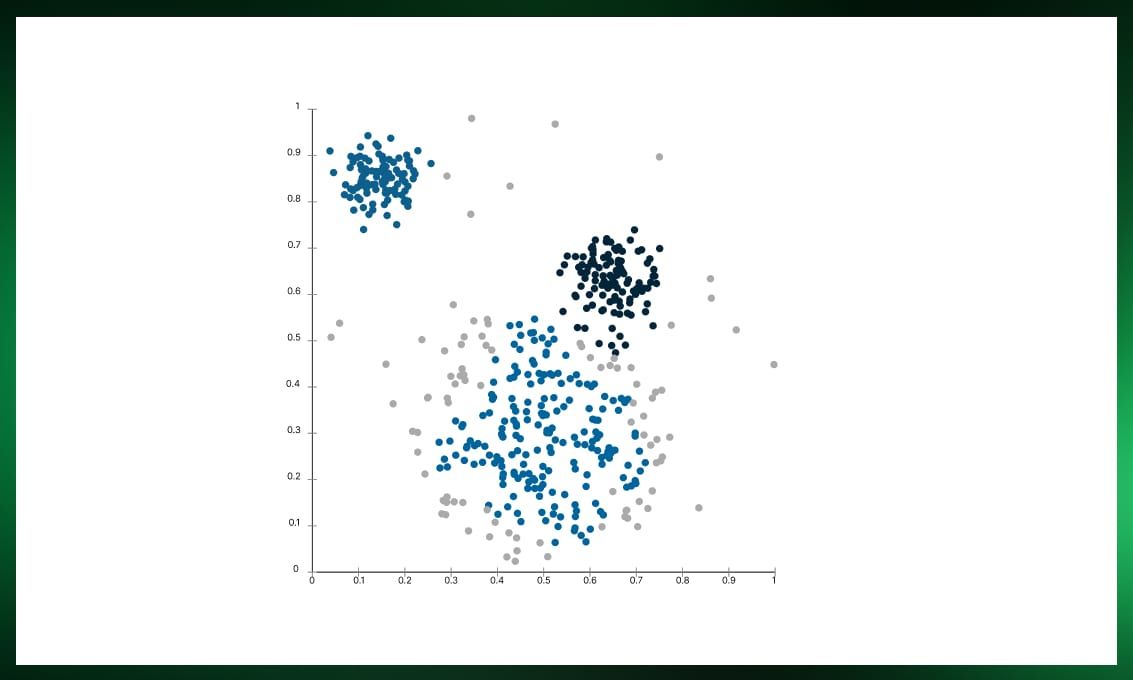
Spectral clustering
Spectral clustering treats data points as nodes in a graph and leverages spectral graph theory to partition them into clusters. This method is particularly useful for datasets with nonlinear boundaries and can handle high-dimensional data efficiently. However, it may not scale well to large datasets.
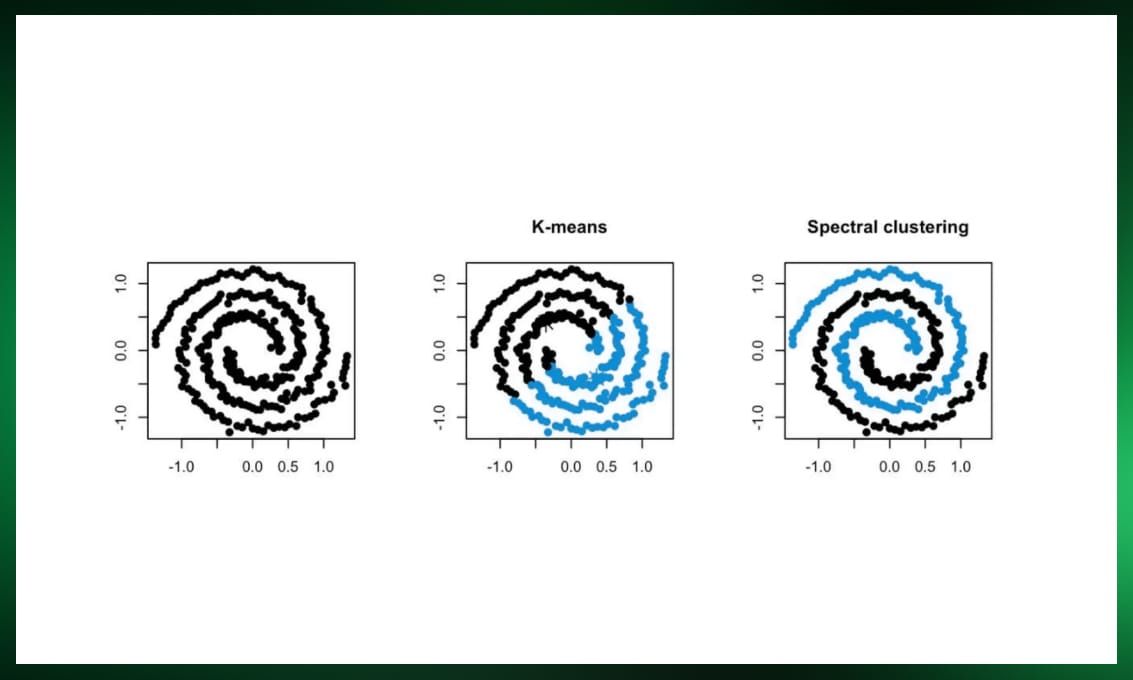
Each type of clustering algorithm comes with its own set of advantages and limitations:
- Partitioning methods like K-Means are scalable and easy to interpret but require specifying the number of clusters beforehand.
- Hierarchical methods offer insights into hierarchical structures but can be computationally expensive.
- Density-based methods are robust to outliers but struggle with varying density levels.
- Distribution-based methods capture complex data distributions but may be sensitive to initialization.
- Spectral clustering handles nonlinear data well but may not scale to large datasets.
Popular clustering algorithms
Clustering algorithms are essential tools in the data scientist’s arsenal, providing insights into the underlying structure of data.
K-Means clustering
K-Means clustering is a widely-used partitioning method that aims to partition data points into K clusters. The algorithm iteratively assigns each data point to the nearest cluster centroid and updates the centroids based on the mean of the data points assigned to each cluster.
The choice of K, the number of clusters, is crucial and often determined using techniques like the elbow method or silhouette score. K-Means finds applications in various domains, including image segmentation, document clustering, and customer segmentation. However, it struggles with clusters of different sizes and shapes and requires specifying the number of clusters beforehand.
Hierarchical сlustering
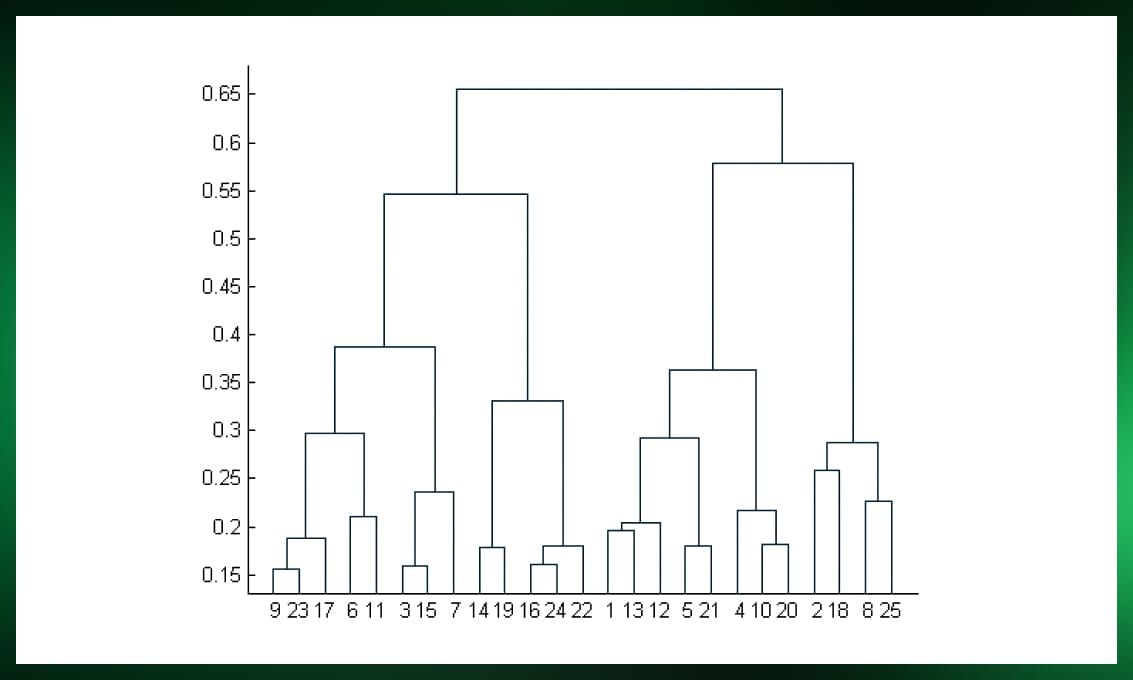
Hierarchical clustering builds a tree-like hierarchy of clusters, offering insights into the hierarchical structure of data. Two main methods, agglomerative and divisive, are commonly used:
- Agglomerative methods start with each data point as a singleton cluster and iteratively merge the closest clusters until a single cluster remains.
- Divisive methods start with the entire dataset as one cluster and recursively split it into smaller clusters.
Dendrogram visualization is often used to represent the hierarchical relationships between clusters. While hierarchical clustering provides valuable insights into the data structure, it can be computationally expensive, especially for large datasets.
Density-based clustering (DBSCAN)
Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is a density-based clustering algorithm that groups together data points based on their density within the dataset.
It requires two parameters:
- epsilon (ε), the radius within which to search for neighboring points,
- minPts, the minimum number of points required to form a dense region.
DBSCAN is robust to outliers and capable of detecting clusters of arbitrary shapes, making it suitable for datasets with varying density levels. It finds applications in anomaly detection, spatial data analysis, and more.
Gaussian Mixture Models (GMM)
Gaussian Mixture Models (GMM) assume that data points are generated from a mixture of several Gaussian distributions. The algorithm iteratively estimates the parameters of these Gaussian distributions, including the mean and covariance matrix, to maximize the likelihood of observing the data.
GMM is effective for capturing complex data distributions and finding clusters with overlapping boundaries. However, it may struggle with high-dimensional data and requires careful initialization.
Spectral clustering
Spectral clustering treats data points as nodes in a graph and leverages the eigenvectors of the graph Laplacian to partition them into clusters. It offers insights into the underlying geometric structure of the data and can handle nonlinear boundaries efficiently.
Spectral clustering finds applications in image segmentation, community detection, and more.
Practical applications
Clustering algorithms are powerful tools with a wide range of practical applications across diverse domains.
Customer segmentation in marketing
By grouping customers with similar characteristics together, businesses can tailor their marketing strategies to specific segments, leading to more effective campaigns and higher customer satisfaction.
For instance, in the example above, a retail company may use clustering to identify different customer segments based on demographics, purchasing behavior, and preferences. This segmentation can then inform targeted marketing initiatives, personalized recommendations, and product development strategies.
Image segmentation in computer vision

In the field of computer vision, image segmentation plays a crucial role in tasks such as object detection, image understanding, and medical imaging. Clustering algorithms are often employed to partition images into meaningful regions or objects based on similarities in color, texture, or intensity. This enables computers to analyze and interpret visual data more effectively.
For example, in autonomous driving systems, clustering algorithms can segment images captured by cameras into distinct objects like cars, pedestrians, and road signs, facilitating real-time decision-making and navigation.
Anomaly detection in cybersecurity
Detecting anomalies in large-scale networks is a critical challenge in cybersecurity. Clustering algorithms offer an effective approach to identifying unusual patterns or behaviors that deviate from normal network activity. By clustering network traffic data, anomalies such as intrusion attempts, malware infections, and data breaches can be detected and mitigated in a timely manner.
For instance, anomaly detection systems powered by clustering algorithms can flag unusual patterns in user access logs, network traffic, and system behavior, enabling cybersecurity professionals to respond swiftly to potential threats and vulnerabilities.
Document clustering in natural language processing
In the realm of natural language processing (NLP), clustering algorithms are used to organize large collections of text documents into coherent groups based on semantic similarities. This enables tasks such as document categorization, topic modeling, and sentiment analysis.
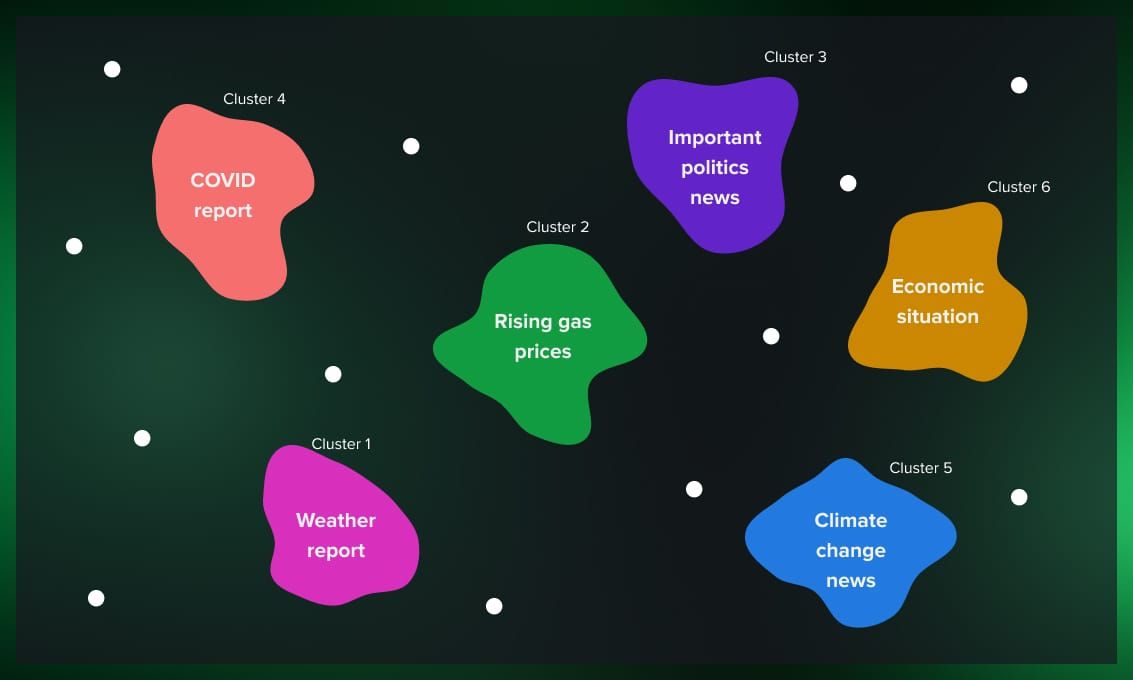
For example, news aggregators may employ clustering algorithms to categorize articles into topics such as politics, sports, and entertainment, allowing users to discover relevant content more efficiently. Similarly, clustering can aid in organizing and summarizing research papers, customer reviews, and social media posts, facilitating knowledge discovery and decision-making.
Best practices and tips
In this section, we will share some of the best practices that will help you to achieve the best results with clustering algorithms.
Preprocessing data
Before applying clustering algorithms, it’s essential to preprocess the data to ensure its quality and suitability for clustering. Some key preprocessing steps include:
-
Data cleaning. Remove any irrelevant or redundant features, handle missing values, and address inconsistencies in the data.
-
Normalization or standardization. Scale the features to a common range to prevent biases towards certain features and ensure equal contribution from all variables.
-
Dimensionality reduction. Reduce the dimensionality of the data if it’s high-dimensional, using techniques like Principal Component Analysis (PCA) or feature selection methods. This can help improve the clustering performance and reduce computational complexity.
-
Outlier detection and treatment. Identify and handle outliers appropriately, as they can significantly impact the clustering results. Consider techniques such as outlier removal or transformation.
Evaluation metrics for assessing clustering performance
Evaluating the performance of clustering algorithms is crucial for assessing their effectiveness and selecting the most suitable approach. Some commonly used evaluation metrics include:
-
Silhouette Score. Measures the cohesion and separation of clusters, ranging from -1 to 1, with higher values indicating better clustering. It considers both intra-cluster similarity and inter-cluster dissimilarity.
-
Davies-Bouldin Index. Quantifies the average similarity between each cluster and its most similar cluster, with lower values indicating better clustering. It evaluates the compactness and separation of clusters.
-
Adjusted Rand Index (ARI). Compares the clustering results to ground truth labels, providing a measure of similarity between the true labels and the clustering output. It ranges from -1 to 1, with higher values indicating better clustering agreement.
Overcoming challenges
Clustering algorithms may encounter challenges, especially when dealing with high-dimensional data and selecting appropriate distance metrics. Here are some tips to address these challenges:
-
Dimensionality reduction. As mentioned earlier, reduce the dimensionality of the data using techniques like PCA to overcome the curse of dimensionality and improve clustering performance.
-
Feature engineering. Engineer informative features that capture the underlying patterns in the data, helping the clustering algorithm to better differentiate between clusters.
-
Distance metric selection. Choose an appropriate distance metric based on the nature of the data and the characteristics of the problem. Common distance metrics include Euclidean distance, Manhattan distance, and cosine similarity.
-
Experimentation and iteration. Experiment with different clustering algorithms, parameters, and preprocessing techniques to find the optimal solution. Iteratively refine the approach based on evaluation results and domain knowledge.
Clustering algorithms are an effective tool that drives innovation across many domains: from marketing to self-piloting vehicles. If you want to continue learning about ML, keep reading our blog.
Read more:






