
We’ve seen many articles on large language models (LLMs) aimed at the general public and decision-makers. Many of them are either overly simplistic or, conversely, cover too complicated technical aspects. In our blog post, we take a balanced approach to explaining the essence of LLMs and their fundamental processes.
This is the first in a series of articles dedicated to large language models, focusing on the following issues:
- Understanding the ground principles of LLMs.
- Approaches to running LLMs.
What are we doing here?
I’ve seen a lot of different perfectly correct explanations of what an LLM is, but in my experience, for a business person it is usually hard to gain useful insights from them. From the questions our customers usually have, I came to the conclusion that it happens not due to the lack of balance between the complexity and accessibility, but due to the concept itself not clearly matching anywhere in their internal world model. As a result, they either do not understand what problems they can solve with LLMs, or think about these models as magic black boxes.
So instead, I will take a step back and introduce a slightly different vision of LLMs. This vision will clearly and logically outline their possible applications and limitations, potentially saving you from a lot of costly mistakes when planning to use them in your business.
LLM and everything around it
I will introduce several key concepts that will help you understand how LLMs work and what they are really capable of. Later, we will be juggling with them in various use cases so you will better understand how to match them with your business needs. Some of them may be simplified or contain minor inaccuracies, but it will improve your overall understanding of the topic.
You may have heard that an LLM “ predicts the next word” or is like “autocomplete on steroids.” That’s the way you should think about it as we begin. Technically, when you are talking to a LLM-based chatbot, your whole dialog is feeded to the LLM, and it tries to predict the next most probable word. Then the whole text plus this word is feeded and it predicts the next one. And so on.
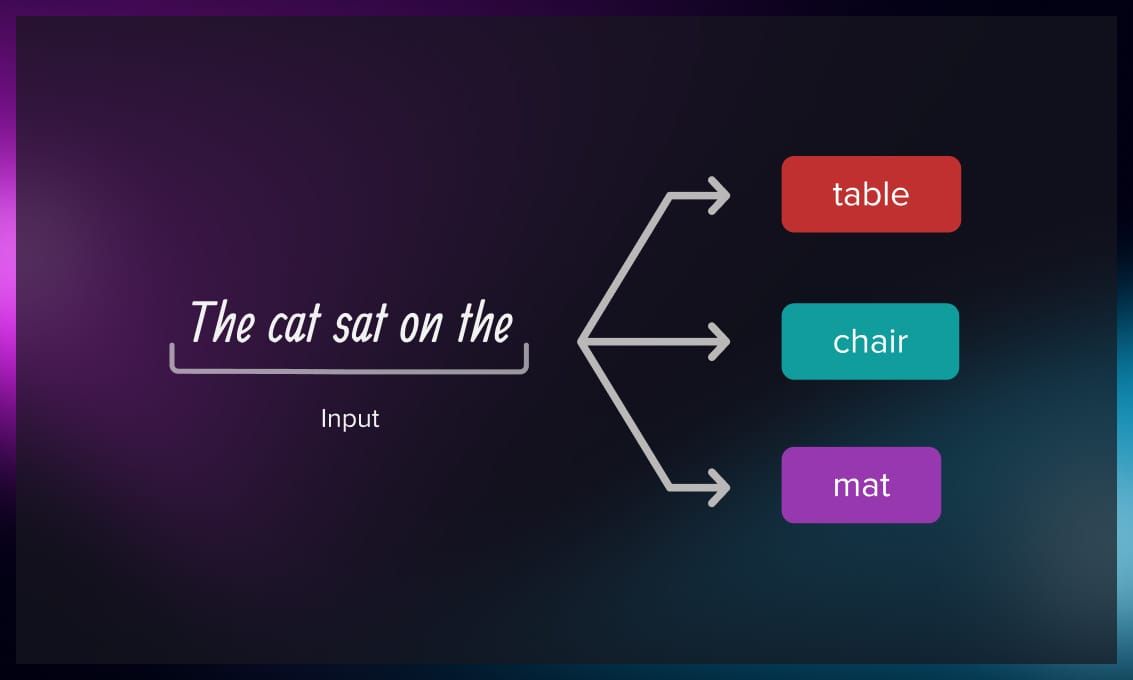
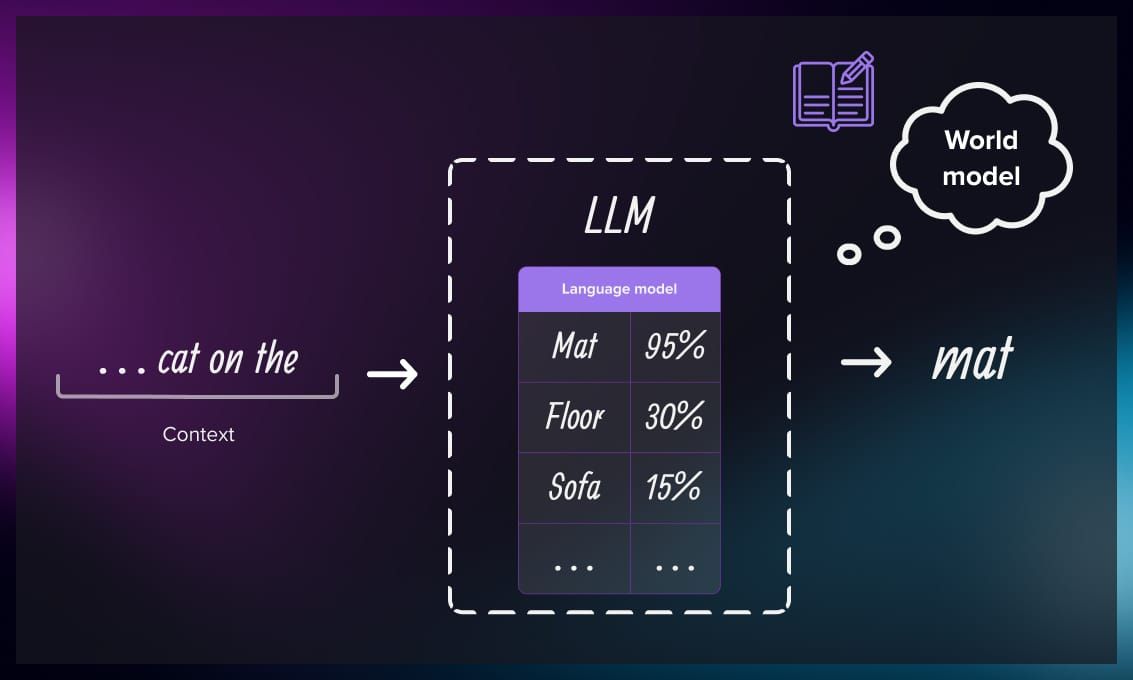
So in reality, LLM does not answer your question; it just reconstructs the most probable dialog that might happen, based on its internal text world model and the conversation history. There are several concepts we can extract from this definition:
- Context window: History of the dialog, text feeded to the model during the generation process.
- Language model: An internal representation of the language or languages that was learned by an LLM via reading massive amounts of text.
- World model: A representation of the knowledge about the outer world accumulated in the LLM. Don’t forget that it is reconstructed only from the texts provided, with all its limitations. However modern multimodal models also can use visual and auditory modalities, but it is another story and we will not discuss them here.
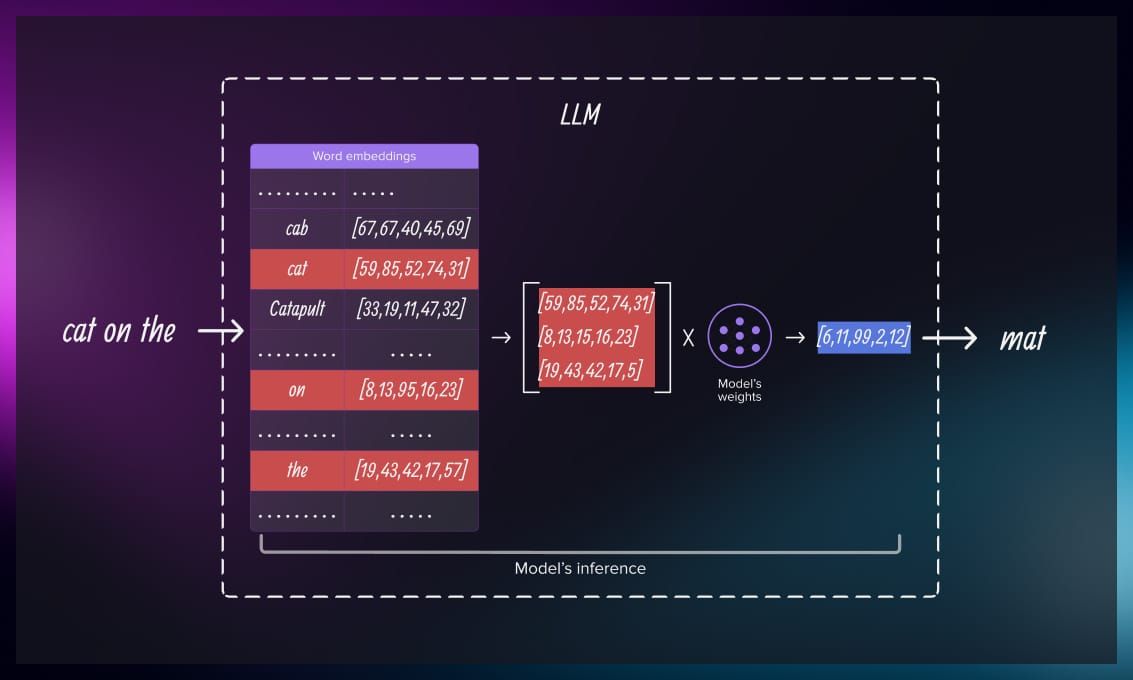
But what exactly is an LLM, as a digital object? It is an instance, a fixed set of numbers, stored in some data array. This set of numbers is also usually called weights. Each time you input text, several things happen: (1) these words are also converted into numbers; (2) they are multiplied many times with the LLMs instance’s numbers; (3) the resulting set of numbers is converted back into output text. This is because computers cannot process information directly; internally, they only work with numbers.
From this explanation, we can derive additional concepts to work with, which will be useful for our goals:
- Word embeddings: The words in a text can be directly represented as numbers called word embeddings; vice versa, these numbers can be converted into words.
- Model inference: A process described above, where we feed some input in the instance of the model and get the output. The Instance by itself does not change in the process.
- LLM model vs. LLM model’s instance: An instance is a specific copy of an LLM model, i.e. a concrete copy of a set of numbers, a file copy, if you wish. The model itself is a concept, an algorithm, and some code around it that builds a model’s instance. I’ve intentionally separated these two concepts: most of the time, I will mean a model’s instance when talking about LLM models, but keep this in mind for the cases when it will be used separately.
But how exactly is this instance created? Of course, through the training procedure—that’s why this field of knowledge is called machine learning. For that, we need two main things:
- Model training: An infinite process, where the model’s instance is feeded with tons of data again and again, and numbers inside this instance are updated up until its word predictions are either good enough, or we are out of time/resources to train.
- Data, or dataset: A set of texts used for the training process.
As you can see, the model’s training and inference are different processes. Training consumes data and updates the model instance’s weights, the other takes context and calculates output using fixed weights. The last thing we need to focus on is that the training is an infinite process in its nature: an engineer needs to define the criterion for when to stop it. But we can in a sense sidetrack that with:
- Fine tuning: A process in which we pick a trained instance of a model and continue the training process with our own data, letting the model’s instance familiarize itself with it. We can do it, as the training process itself is infinite, as you remember, right?
For example, you can feed it with internal documentation of your company so the instance’s weights are updated. Then, if you try to use this LLM later, it will have the knowledge of the information presented in your data even if it is not put in the context window. NB! It is not the only way we can ask a model about something it hasn’t seen in the training data, but we will discuss it later.
Essentially, that’s everything we need to know to move forward. To sum it up, the whole process is as follows:
- We pick a model.
- We select a very big training dataset, a collection of billions of texts.
- The model’s instance is created through the training process with the data provided
- Inside it, a world representation, based on textual information, is constructed.
- We can interact with the instance by placing our request in the context window.
- Text is converted into a word embedding and processed, after which the output word embeddings are converted back into text.
- The process where the model generates an answer is called the model’s inference.
- If we need to ask the model about things it hasn’t seen before, we can perform fine tuning or use other techniques.
Usually, the first few steps are skipped as they are quite expensive. Instead you can pick any existing pretrained open-source model and use it for your needs. But in any case, you need to understand which one to choose and what route to take, and we will discuss these points further.
Running locally, using APIs or options other than LLMs?
Before making such a decision you should understand that “not all LLMs are created equal.” They come in various sizes, costs per token, inference speeds and biases. Some of them are better in one task and some of them are better in others. Some of them are optimized to be run on particular hardware. Some of them are open-sourced and can be instanced somewhat easily, and some of them are Closed AI. Some are so big that you should forget to run them locally in the upcoming years, which comes with high costs per API token, but is compensated with a wide versatility and astonishing accuracy. So it might be complicated to decide what route to take, but hopefully we will cover most cases in this guide so you can understand where to fit it in your business.
Running models locally
While in almost any case it will be easier and, in order of magnitude, cheaper to develop an LLM-based system with external APIs, there are several major points to consider that might change your mind:
- The biggest issues are privacy and security. As you can imagine – if you are running an LLM locally, you are not sending data anywhere, i.e. not exposing it externally. Of course, this holds if your LLM is also for internal use only. If your LLM can be accessed from outside, you are still compromising your data privacy, although the extraction process is more complicated and not 100% accurate.
- There are plenty of network errors you can get then working with external APIs. Moreover, some of them might have rate limits which might be unsuitable for your task.
- You can fine-tune models to perform much better on your particular tasks. We will be talking about the fine-tuning procedure relevance later.
- You can ensure long-term availability of local LLMs and their offline availability. If you and the model behind the external API do not have access to the older versions instances, this might break your pipelines.
- Some particular problems can be tackled with smaller LLM models. Running these locally can be cheaper in the long run and not that expensive to instance.
Additionally, here are minor or more rare benefits of local LLMs:
- You have control over the data which was used in the training process (of course, this is true only if you train your own LLMs instance from scratch or heavily fine tune one). So you can control the safety of your model in terms of biases, or, vice versa, integrate your own biases in your model, if needed.
- If latency or real-time processing are crucial to your project, local models might be also better. But in most cases it is negligible.
Use of APIs
Anyways, if you are not that focused on data safety, in most cases, using external LLMs APIs will be more beneficial:
- They are much easier to start using. This reduces initial development time and costs by at least by several times.
- Most expensive ones are more accurate out-of-the-box than any available open-source models. You can tackle many different problems without too much thinking, and do it very fast.
- You do not need to think about extra GPU infrastructure for the model instances. But you still need to run extra code for the developed project somewhere.
- Easy scalability. You can deploy extra model instances in a few clicks and balance the load if it is needed. For most services, you don’t even need to think about it, as they scale automatically.
- Cost-efficiency at low scale. If you do not need to perform queries too often, using external models is always much cheaper.
Other benefits are not that noticeable for APIs integration in businesses.
Mixed approach
Last but not least, do not forget that the most efficient way to handle LLMs is using a mixed approach:
- Use external APIs to tackle the most complicated problems or issues where data security is not that important.
- Use internal models for the most sensitive information processing.
- For some particular problems, you can use extra tricks. For example, you can save API calls history, process it and store it in easily accessible cashes to reduce the number of costly API calls in the future. We will not focus on them right now, as they are more tech-specific.
Other approaches
But maybe we can solve our problems locally with some cheaper approaches without local LLMs? As you can imagine, machine learning has existed for many decades, and we were still able to solve a lot of problems efficiently before their emergence. The main issue with text models has always been text variability, which was often overcome by using a lot of extra manual labeling and tons of use cases.
As you know from the previous section, the LLM is learning the World Model via text, which includes a Language Model within it, i.e. it covers language and text variability in all its diversity. This means that it reacts better in unusual situations and can handle unknown contexts much easier. But for production purposes, we often reduce the language context to very narrow specifications, so for some applications, this benefit is lost in the process.
For example, if you are trying to build any chatbots, LLM would be better, as it is hard to guess 100% the users’ requests, in which form, which order these requests will have and what context from previous conversations or external resources will be needed. But for much more straightforward tasks, for example text summarization, text classification, language detection, or topic modeling, where you do not need to have such a high accuracy, you can get by with relatively cheap classical models.
As for the transformer models, although some of them are not that big as even small modern LLMs, they can be pretty efficient in narrow tasks if handled correctly. For example, Bloomberg spent about $10 million on AWS SageMaker to train their own BloombergGPT specifically for financial tasks. If you remember, training or even fine-tuning your own model is quite expensive and should be considered only in critical applications. As a result, this model had worse metrics than specialized fine-tunes of rather old and compact models like BERT (2018) and RoBERTa Large (2019), which was cheaper to build by a mile. As you might guess, it still was worse than GPT-4 for the same task, but not by much. So if data safety is a problem for such a task, this should be the cheapest option in this case.
Conclusion
In this article, we have examined the operational principles of LLMs and the different ways of running them: locally, using APIs, a mixed approach, and other methods.
In our next blog post, we will explore the fine-tuning of LLMs and the risks to be aware of.
Read more:

.jpg)




