
In 2023, generative artificial intelligence has become so hyped that every self-respecting Big Tech company is running to roll out their own technology. LLaMA 2 is a new open-source language model by Meta that can be seen as an opponent of ChatGPT.
Releasing products that should become the “killers” of well-established products seems to be a recurring strategy of Mark Zucherberg lately. Will LLaMA have the same destiny as Threads, that has already been abandoned by most of its users? Let’s find out.
In this article, you will learn everything you need to know about this new AI tool.
What is a large language model?
A large language model is an artificial intelligence (AI) system that uses deep learning algorithms to analyze and generate natural language. It is trained on massive amounts of text data, such as books, articles, and web pages, to understand the nuances of language and generate human-like responses to queries. Large language models are capable of performing a wide range of language-related tasks, including text generation, translation, summarization, and sentiment analysis. Some of the most well-known large language models include GPT-3, BERT, and T5.
What is LLaMA?
LLaMA is an auto-regressive language model that operates on the transformer architecture, similar to other well-known models. Its function involves taking a sequence of words and recursively generating text by predicting the next word. However, LLaMA distinguishes itself by being trained on a diverse range of publicly available text data that includes various languages such as:
- Bulgarian
- Catalan
- Croatian
- Czech
- Danish
- Dutch
- English
- French
- German
- Hungarian
- Italian
- Polish
- Portuguese
- Romanian
- Russian
- Serbian
- Slovenian
- Spanish
- Swedish
- Ukrainian
The current release is called LLaMA 2. This is not just one model but a collection of models that have been trained on various publicly available resources. This makes them perfect for fine-tuning to a wide range of tasks. Some of the sources that the model was built on include CommonCrawl, GitHub, Wikipedia, ArXiv, and StackExchange.
Since LLaMA 2 is the second-generation of models, it has been trained on more data and contains more parameters.

The LLaMA models have been designed primarily for research purposes and are available under a non-commercial license and commercial use if the product that uses it generates less than $100,000 of income. Their release is intended to aid researchers in analyzing and resolving problems related to biases, risks, the production of harmful or toxic content, and hallucinations. Users can also use Llama-2-chat to chat with the model. The tool uses reinforcement learning from human feedback.
According to Meta, LLaMA outperforms the existing open-source model benchmarks such as Chinchilla-70B and PaLM-540B. The fine-tuned model, Llama-2-chat, leverages publicly available instruction datasets and over 1 million human annotations. Compared to GPT-4 LLaMA is less efficient but it remains the most powerful of all open-source models.
How to start using LLaMA?
To start using the model, you need to download it on the official website. You can find the official inference code in the facebookresearch/llama repository.
How is LLaMA different from other AI models?
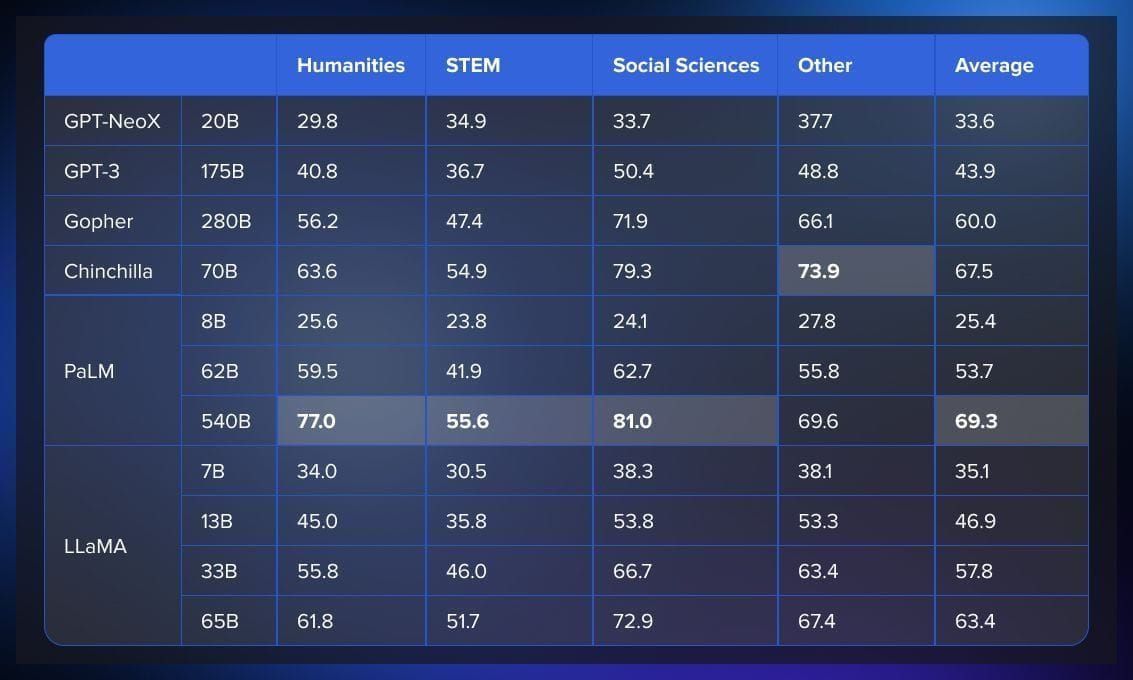
According to the paper published by Meta AI, in terms of common sense reasoning, LLaMA-65B outperforms other SOTA models in PIQA, SIQA, and OpenBookQA benchmarks.
LLaMA consistently outperforms GPT3, Gopher, Chinchilla, and PaLM in Closed-Book Question Answering & Trivia benchmarks. It also performs well in reading comprehension tests such as RACE-middle and RACE-high.
However, LLaMA was not fine-tuned on any mathematical data and performed poorly compared to Minerva in mathematical reasoning tests. In code generation tests using HumanEval and MBPP benchmarks, LLaMA outperformed both LAMDA and PaLM in HumanEval@100, MBP@1, and MBP@80.
Finally, in terms of domain knowledge, LLaMA models perform worse compared to the massive PaLM 540B parameter model, which has wider domain knowledge due to its larger number of parameters.
What is the difference between LLaMA and ChatGPT?
The two generative AI models have a lot in common. They are both built on the transformer architecture and leverage machine learning to understand and generate texts. Users can communicate with models in the chats, providing them with prompts that describe the tasks that they need the models to perform.
However, there are also vast differences. Meta strives to make their model resource-effective, so it is more compact than ChatGPT. Moreover, unlike Open AI, the company made their model open source. It means that researchers that were previously limited in resources to be able to afford access to other LLMs will be able to use LLaMA freely and contribute to its development. At the same time, it is also a limitation; while ChatGPT welcomes commercial projects, LLaMA is non-commercial use only.
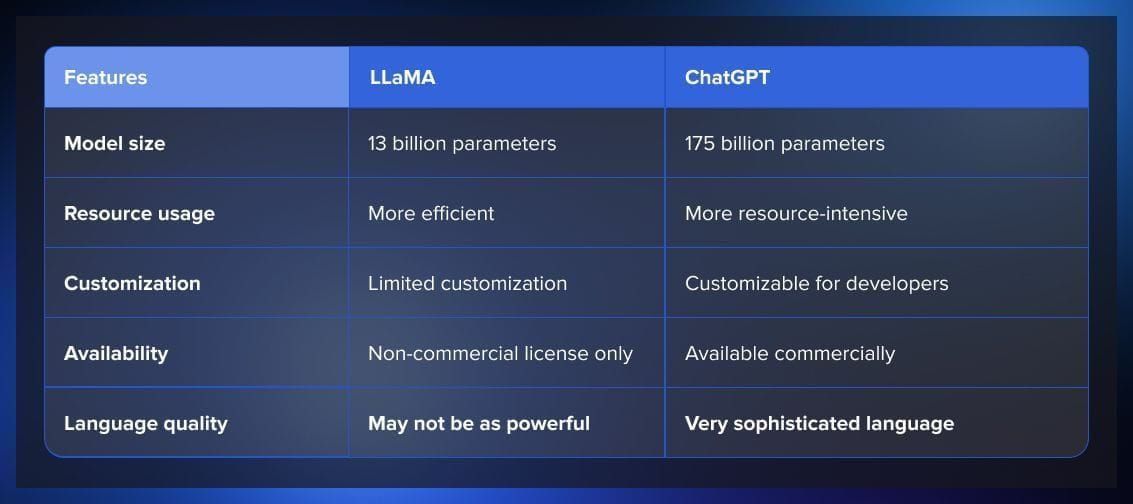
A key difference also lies in how the models work with human language. ChatGPT has been trained on many more parameters than LLaMA (175 billion vs 13 billion), so in many situations it results in more effectiveness. However, the data that was used to train the GPT model was mostly scraped from internet texts and social media content. LLaMA was trained on a wider variety of texts such as scientific papers and news stories. So while it may lose to ChatGPT in informal conversations, it might win where specialized or technical language is necessary.
Why is it important for LLaMA to be open source?
There was a lot of conversation in the community about the AI alignment of large language models and how it is important for the public to be able to access them and have control over what data is used for AI training. Making LLM models open source can contribute to Big Tech companies being more transparent and more accountable in this domain.
Moreover, it is important to make large language models open source because it provides alternatives to closed commercial products and gives organizations more control over the model, its training data, and its applications. Open source models also allow for more customization and can be tuned for specific tasks. The release of open source models is a reaction to the closing or threat of closing AI work by big tech companies, and it enables smaller companies to have access to LLMs without being dependent on one or two vendors.
Making the model open source can help Meta develop the model efficiently while reducing the costs. Moreover, it can create an image of a brand that is invested in public security and trust ― in the recent years, Meta has faced a lot of criticism in this domain.
However, there are also concerns about large language models becoming public. LLMs are very powerful and can potentially have a huge influence on the public that we can’t even imagine beforehand. But open-source projects are hard to regulate, especially when multiple locations of potential users are involved. Therefore, it is easy to imagine the scenario where the immense power of LLMs are abused or misused.
Read more about AI tools and models:

.jpg)

_(1).jpg)
_(1).jpg)
.jpg)
.jpg)