
Machine learning models are mainly developed offline but must be deployed in a production environment to process real-time data and handle the problem they were designed to solve.
In this blog post, we will explore the fundamentals of deploying an ML model, discuss the challenges you may encounter, and provide steps to streamline the process for greater efficiency.
What is the machine learning model deployment?
Experts estimate that up to 90 percent of ML models never reach the production stage. It is not uncommon for models that performed excellently during the development stage to encounter issues like data skews, scalability limitations, or sudden drops in prediction accuracy when launched into production.
Even for the few machine learning models that do make it to production, the deployment process can be time-consuming, as they require constant attention to ensure quality and efficiency of predictions.
While the main objective of building a machine learning application is to address a problem, an ML model can only fulfill this purpose when dealing with real data. Therefore, deployment is just as crucial as the development phase for any AI project.
Deployment involves transitioning an ML model from an offline environment into an existing production system. This step is pivotal for the model to fulfill its intended purpose and effectively tackle the challenges it was designed for. Deployment establishes an online learning mechanism where the model is continuously updated with new data.
Below is a helpful video with tips on how to manage deployment.
The specific process of ML model deployment may vary depending on the system environment, the model’s type, and the DevOps practices adopted by individual organizations. The best fit depends on factors such as scalability requirements, budget constraints, data privacy regulations, and more.
For example, a tech startup working with AWS will have a different model deployment process than a financial institution using on-premises servers. A small fintech firm might use AWS SageMaker to host, train, and deploy their machine learning models, benefiting from AWS’s built-in scalability and flexibility. On the other hand, a financial institution might need to use Docker containers to ensure that their model is packaged with all its dependencies and can run on any machine in their private data center network.
A healthcare company dealing with patient data under HIPAA regulations will have a different deployment process than a marketing company working with publicly available data. A medtech company needs to ensure all data used by their models is encrypted, both at rest and in transit, and that access is strictly controlled to comply with HIPAA regulations, whereas the marketing company might simply need to anonymize identifiable data to comply with privacy regulations.
A software development agency that has fully embraced DevOps practices, such as continuous integration and continuous deployment (CI/CD), will have a different deployment process than an e-commerce company where the development and operations teams work separately.
Deploying ML models in production

In general, the deployment process can be divided into the following steps.
Prepare the model
This step involves training and validating the ML model using appropriate datasets.
After that, you have to optimize and fine-tune the model for performance and accuracy.
Finally, you save the trained model in a format compatible with the deployment environment.
Choose a deployment environment
At this stage, your task is to select a deployment environment suitable for your specific requirements, such as cloud platforms (e.g., AWS, Azure, Google Cloud) or on-premises infrastructure. When choosing the deployment environment, consider scalability, cost, security, and integration capabilities
Containerize the model
Now it’s time to package the ML model and its dependencies into a container (e.g., Docker container). Containerization ensures that the model, its dependencies, and the runtime environment are encapsulated together, facilitating portability and reproducibility.
Deploy the containerized model
Before deploying the containerized ML model, you have to set up the necessary infrastructure in the chosen environment. Once it’s deployed, ensure its access to the required resources (e.g., compute power, storage) and then configure the networking and security settings appropriately.
Monitor and scale
Implement monitoring mechanisms to track the performance and behavior of the deployed model in real time. Next, set up alerts and logging to detect and address issues promptly. Note that it’s essential to design a scaling strategy to accommodate increased demand or changes in workload.
Continuous integration and deployment (CI/CD)
To automate the deployment process, you need to establish a CI/CD pipeline that will ensure smooth updates to the model. Additionally, automate testing, version control, and deployment stages to streamline the deployment workflow.
Post-deployment maintenance
The deployment doesn’t end with the actual launch.You have to regularly evaluate the model’s performance in the production environment and continuously monitor data quality, drift, and potential biases. The model needs constant improvement as new data and feedback become available.
Which ML model deployment methods to use?
You choose deployment methods depending on the specific task at hand and the business problem you need to solve. Below, we look at the main methods.
Batch deployment
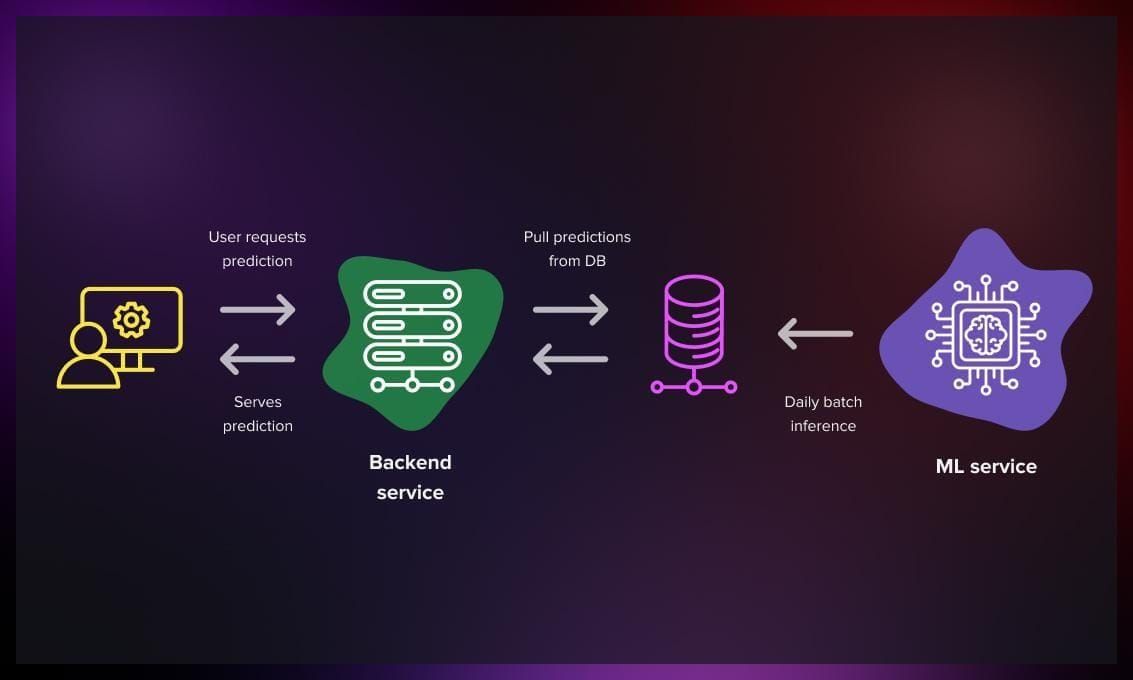
This approach is suitable for scenarios where data is collected over a period of time and processed offline in larger batches.
-
The mode processes a batch of predictions daily; once completed, they are sent back to the service.
-
With this method, the data may become outdated, but it will never be more outdated than the last processed batch, which is generally acceptable for most cases.
Real time
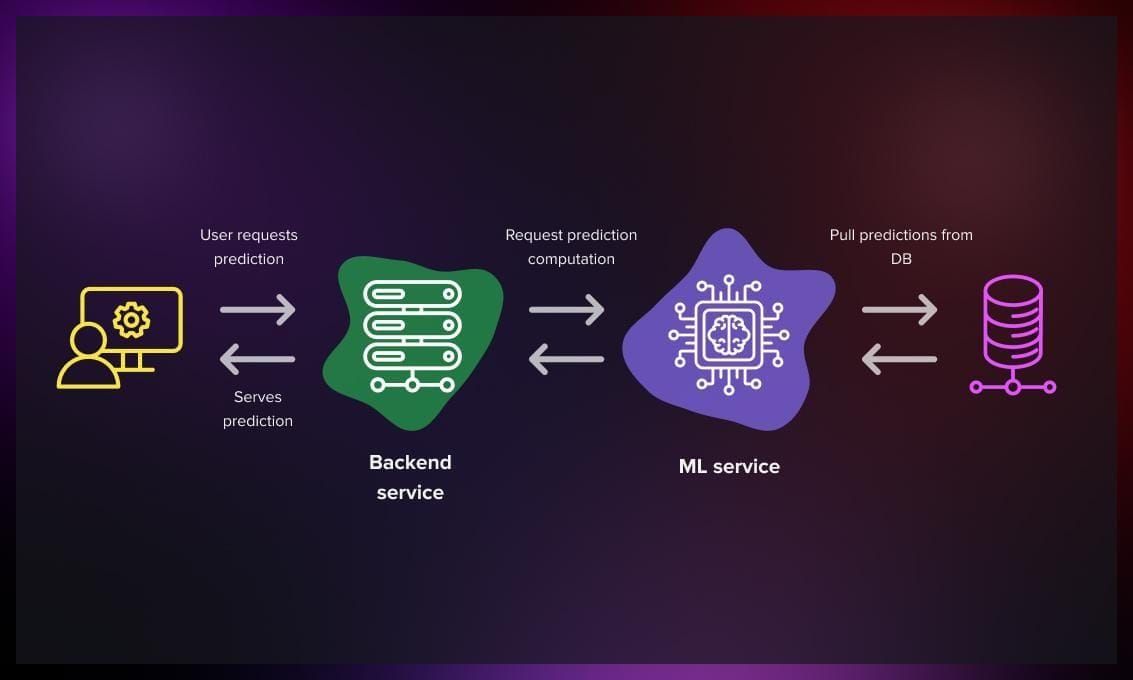
-
This method is particularly effective for generating personalized predictions considering recent contextual information, such as the time of day or recent user search queries.
-
To accommodate simultaneous requests from multiple users, you need to employ multi-threaded processes and vertical scaling by adding more servers.
Streaming deployment
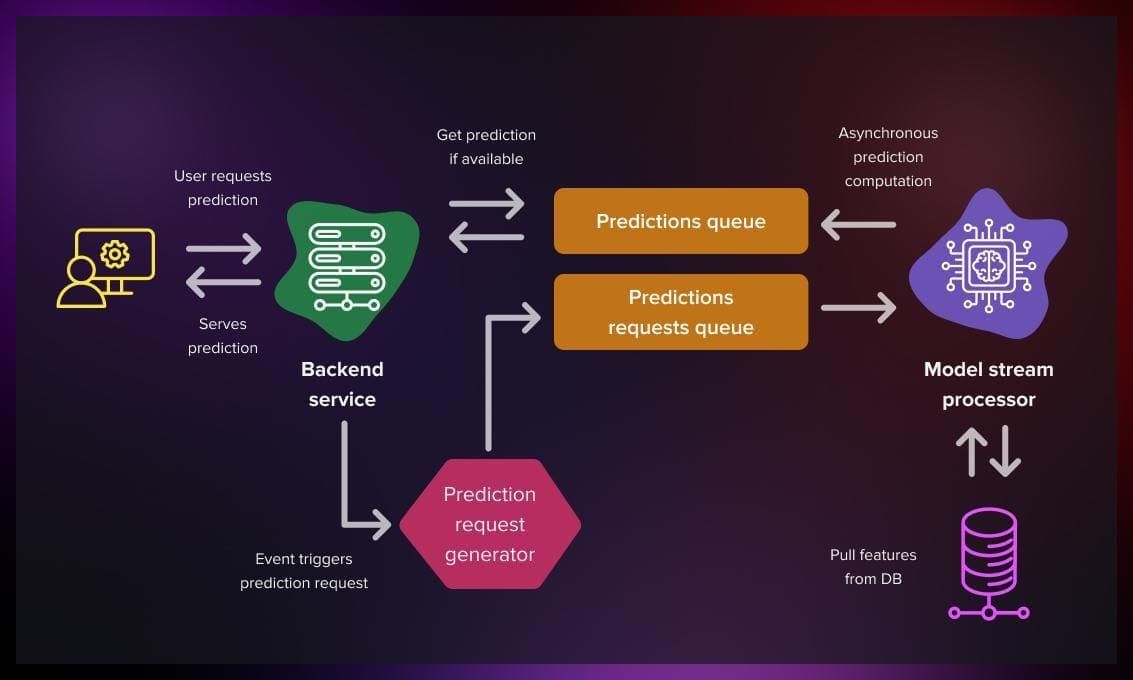
-
Streaming deployment facilitates a more asynchronous process, allowing user actions to initiate prediction computations. This is the principle on which most recommender systems are based.
-
To achieve this, the process is integrated into a message broker, such as Kafka. The machine learning model processes the request when it is ready.
-
This approach reduces the server’s processing burden and optimizes computational resources through an efficient queuing mechanism. Additionally, the prediction results can be placed in the queue, and the server can use them as needed.
Edge deployment
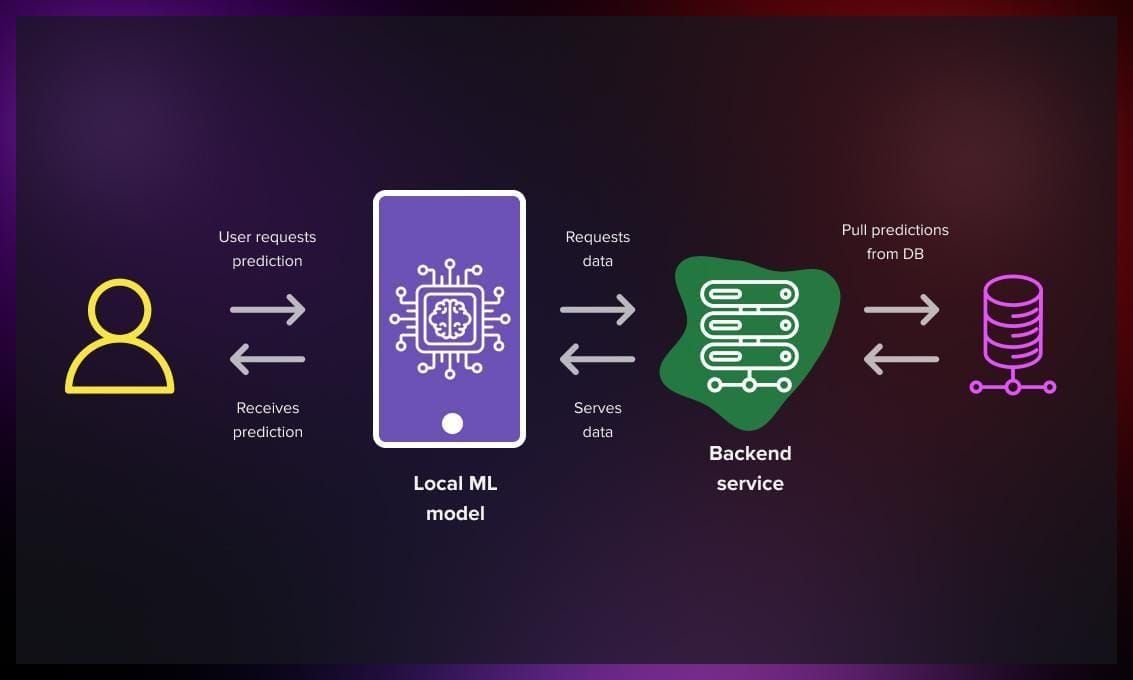
-
Edge deployment enables faster model results and offline predictions.
-
The model can be deployed directly on the client device, for example, a smartphone or IoT device.
-
To achieve this, models are usually required to be small enough to fit on a compact device.
What are the challenges of ML deployment?
ML model development is inherently resource-intensive and complex. Integrating a model developed in an offline environment into a live environment introduces new risks and challenges, which we explore in this section.
Knowledge
Bridging the gap between the teams responsible for building and deploying ML models can be challenging. Data scientist teams build the models, while developer teams handle deployment. Overlapping skills and experience may be lacking, requiring effective collaboration and knowledge transfer between these distinct areas.
Scale
Anticipating the need for model growth and scaling to accommodate increased capacity adds complexity to the ML deployment process. Ensuring the model can handle growing demands and maintain performance becomes crucial.
Infrastructure
Lack of robust infrastructure can impede ML deployment, leading to delays. When infrastructure is not well-prepared, it also increases the risk of unnecessary model retraining.
Security and privacy
ML models often deal with sensitive data, such as customer information or financial records. Ensuring the security and privacy of data during model deployment is crucial. Implementing robust security measures, encryption techniques, access controls, and complying with relevant regulations are necessary to protect the data and maintain user trust
Monitoring
Continuously monitoring and testing the model’s effectiveness post-deployment pose ongoing challenges. Regular monitoring is necessary to ensure accurate results, identify potential issues, and drive performance enhancements.
Check out this video to learn about deploying an ML model with Python.
And in this article, you will find more information on what to be aware of when deploying an ML model.
How to test an ML model?
Below, we will explore several strategies for testing ML models that can be chosen based on specific situations and the benefits and disadvantages they offer.
Recreate deployment strategy
Recreate deployment strategy proves effective when updates are infrequent, and maintenance windows are wide. The process involves stopping the old service and starting up the new one, resulting in downtime during the teardown and spin-up stages.
In a software-as-a-service (SaaS) environment with frequent updates, this strategy can only be practical with the implementation of queues and asynchronous messaging architectures. For instance, when upgrading a service responsible for sending emails, messages can be queued in an outbox until the upgraded version is up and running.
Benefits:
- Simple and straightforward.
- Works well when combined with queues and asynchronous message buffers.
- You don’t need to maintain multiple service versions simultaneously.
Drawbacks:
- Downtime required for the upgrade process.
- In case of issues, the system goes down for a rollback.
Rolling update deployment strategy
The previous strategy works well when there’s only one version of the service. But if you’re using more versions and managing them with a load balancer, you can make your system more reliable with what’s called a rolling update strategy. In simple terms, you start up a new version and once it’s working well, you turn off one of the old ones. This way, your service doesn’t have to go down while updating. This pattern continues until only the new versions of the service are running. This strategy is commonly employed in Kubernetes and other containerized production environments.
Benefits:
- Seamless integration with Kubernetes.
- No downtime during the upgrade process.
Drawbacks:
- Multiple versions of the same service may coexist during the transition period.
- No provision for rollback services with warm backups.

Blue-Green deployment strategy
The blue-green deployment strategy requires additional resources, including two identical production environments and a load balancer. One environment, referred to as “blue,” handles 100% of the traffic, while the other, “green,” remains inactive. Updates are deployed to the idle version, and once the upgrade is successfully completed, the traffic is switched over to the updated version. Traffic alternates between the green and blue environments, ensuring that the previously deployed version always runs on the idle environment. This approach simplifies rollbacks in case of issues.
Benefits:
- Eliminates downtime during upgrades.
- Enables quick and efficient rollbacks.
Drawbacks:
- Requires additional resources to maintain two production environments.
- Introduces complexity in the deployment process.
Canary deployment strategy
The canary deployment strategy is similar to the blue-green deployment approach, where a new version of the service runs in parallel to the existing version. However, it introduces a slight improvement by initially directing only a percentage of traffic to the new version.
A canary deployment does not eliminate downtime entirely but minimizes its impact by providing an early warning mechanism. It restricts the availability of the new version to a subset of users.
If the new service is not responding favorably to this fraction of requests, the rollout can be aborted, reducing the impact on a broader scale. Conversely, if everything appears to function well, the volume of the requests gradually increases until the new version fully serves all requests.
One inconvenience of this method is that a specific subset of users may encounter most production issues depending on how the canary traffic is selected.
Benefits:
- Early detection of problems.
Drawbacks:
- Increased complexity in deployment.
- Canary users may experience a higher proportion of production issues.
Shadow deployment
If identifying problems solely through metrics and the cost of incidents is high, a shadow or mirrored deployment would be a practical option.
In a shadow deployment, the new version of the service is initiated, and the load balancer mirrors all traffic. This means that requests are sent to both the current and new versions, but only the existing stable version provides responses. This setup allows for monitoring the latest version under actual load conditions while avoiding any potential impact on customers.
However, implementing this approach comes with its costs. It usually requires a service mesh like Istio to facilitate the actual request mirroring, and the complexity increases from there. For example, if you shadow deploy a new version of a user service backed by a relational database, all users might be created twice, leading to unforeseen consequences.
Benefits:
- Identifies production problems without impacting customers.
Drawbacks:
- Deployment complexity.
- Architectural complexity.
How to improve ML model deployment?
Model deployment efficacy depends on several factors that seem to be obvious. However, they are not always taken into account. So make sure you pay attention to the following.
Setting goals
As companies integrate machine learning into their operations, they may rush to hire data scientists and machine learning experts to automate or enhance processes, but without a deep understanding of which problems are suitable for ML solutions.
Furthermore, even when the business problem aligns well with machine learning, projects can get stuck in a prolonged experimentation phase as stakeholders wait for an unattainable level of flawless performance.
Establishing communication
Since ML model deployment is a multi-layered process, establishing open collaboration and communication channels between data scientists and the operations team is crucial. Inefficient communication is an infamous stumbling block that you don’t want to face. If you have a lack of in-house resources, consider hiring MLOps engineers to bridge the gap and facilitate team integration.
Model training
The objective of model training is to create a model capable of making accurate predictions on new data by analyzing the connections between data points and recognizing patterns. It is essential to have a clean, substantial, and representative training dataset that aligns with the real-time data the model will encounter in production. However, coming across clean data in a production environment is rare. Therefore, allocating a significant amount of time towards cleaning, labeling, and feature engineering is important to prepare the data appropriately.
Monitoring data observability
In machine learning, the rule is simple: the better your inputs, the better your results. It’s essential to have reliable and clean data and efficient data pipelines to ensure that your machine learning models perform at their best and provide accurate predictions.
That’s why investing in data observability is a smart move. It gives you a complete understanding of your data’s quality and allows for thorough monitoring. By implementing data observability, you can easily spot and prevent unnecessary data from entering your ML models in the first place. This investment pays off.
Automation
By reducing manual effort, you can avoid a number of errors related to data cleaning and preparation tasks. You can use tools or create scripts to automate these processes and also set up model triggers to initiate continuous model training whenever new data enters the pipeline.
Infrastructure
Machine learning models are computationally demanding and require significant resources. You need to evaluate your infrastructure requirements to decide which options will suit you: outsourcing to specialized ML infrastructure providers or setting up on-premises infrastructure.
Useful resources for ML system design
As a conclusion, we have compiled a list of helpful resources that will help you deepen your understanding of ML system design. Check them out!






