
Stable Diffusion has been a buzzword in the last months after it was publicly unveiled by its developer Stability AI on August 22, 2022.
Not only Stable Diffusion generates complex artistic images based on text prompts, but it’s also an open source image synthesis AI model available to everyone. Its free accessibility makes it very different from its predecessors.
In this post, we explain how it works, what prospects it opens, and share tips on how you can use it.
Simply magic?
The best way to introduce Stable Diffusion is to show you what it can do. Let’s start with the free demo version available on Hugging Face.
Text-to-image generation
The idea is simple: let your imagination loose, think of any setting, things, or characters you want to see in the picture, write down a description (called a prompt), and get a bunch of AI-generated images in a matter of seconds.
Here’s what I got on Hugging Face for the following description: “Louis Armstrong playing on a magic flute in a rich 18th-century house in Salzburg.”

Well, not bad. I think I should be more creative in the wording of my text prompts.
Here’s what “A mecha robot in a favela in expressionist style” brought me:

The Hugging Face demo version also allows you to adjust existing images using a text prompt.
DreamStudio Beta
You can also test DreamStudio Beta – the official interface and API for Stable Diffusion designed and powered by Stability AI LTD. It includes the latest updates and improvements.
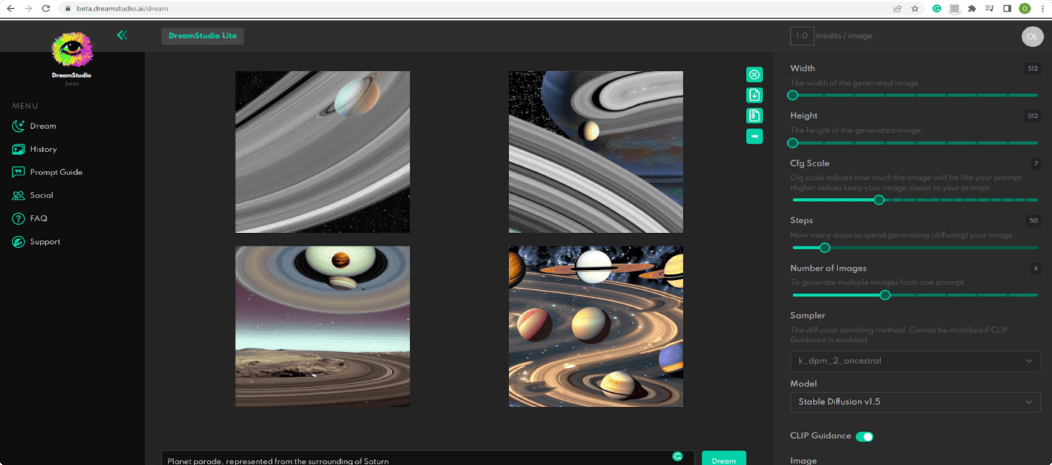
When I signed in DreamStudio Beta and opened the interface, the automatic prompt read, “A dream of a distant galaxy, by Caspar David Friedrich, matte painting trending on artstation HQ.” That sounded whimsical and postmodernist enough for me to try and see the result, which was:

I decided to generate only one image as the demo version gives you a limited amount of credits for image variations.
Alright, what about my own dreams? How about that: “Paul Gauguin’s steampunk painting set in the Arctic in 2300.” The result seems quite plausible: Gauguin’s signature vivid colors coupled with Terry Guilliam-style steampunk elements. I am not quite sure that the AI conveyed the futuristic setting of the year 2300, which, I assume, can be explained by the limitations of the demo version. Yet, the results look quite promising.

How to generate images with Stable Diffusion?
The text-to-image sampling script, “txt2img”, consumes a text prompt and parameters such as sampling types, output image dimensions, seed values, and outputs an image based on that information.
You can choose the seed value randomly to experiment with different outcomes.
You can also change the number of inference steps for the sampler. A larger value requires more time, while a smaller value could lead to visual flaws.
Tips for writing text prompts
The key to obtaining awesome images is the right text prompt. Below, you will find some tips for prompt engineering that will save you time and effort and help get the creative result you are looking for.
When you open the application, you see an interface with the blank space in the center and settings on the right.
This is what it looks after you submit the text prompt:
If you are not quite satisfied with the result, keep playing with the text at the bottom and the settings on the right.
1. Opt for English
Stable Diffusion was trained on 2.3 billion English image-text pairs. The other 100+ languages account for 2.2 billion such pairs, so the share of each language is significantly smaller. That means that prompts in other languages do not always provide the necessary outcome.
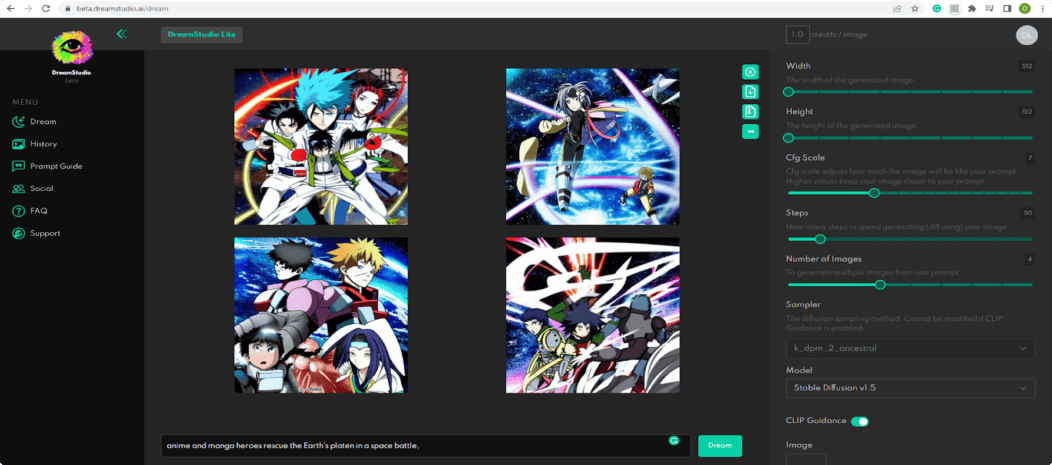
2. Be specific
It’s important to write a very detailed text prompt to get the results you are looking for. Note that the words in the beginning of the phrase weigh more than those at the end.
3. Include the type and genre of art
The images generated by Stable Diffusion range from oil and acrylic paintings to prints, cartoons, and fashion photography. So indicating the type of imagery would bring you much closer to the desired result.
4. Add an artist’s name
You can also use the name of a particular artist, for example, Andy Warhol, Auguste Renoir, or Caspar David Friedrich to create an image in their style.
Some implementations of the Stable Diffusion user interface also provide negative prompts, allowing you to define what the model should avoid when creating images.
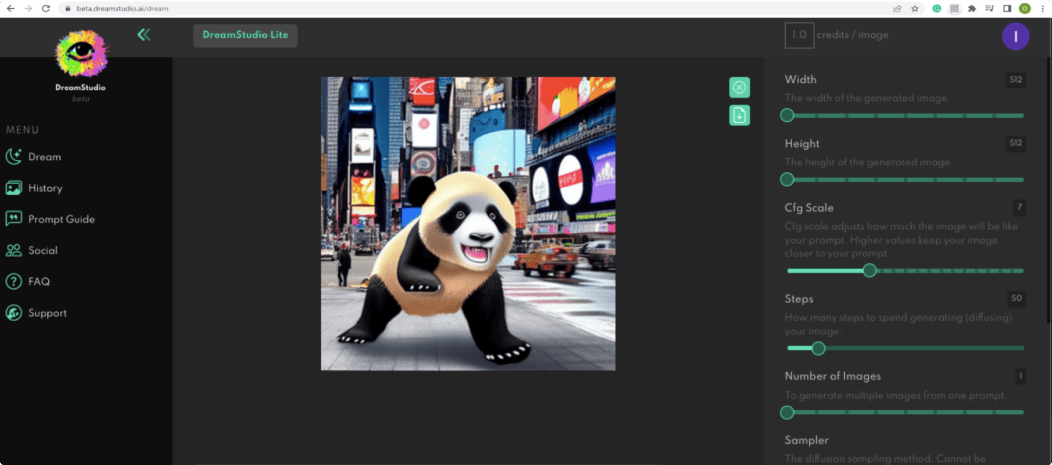
5. Make it trendy
If you want a more artistic image, DreamStudio Beta recommends adding “trending on artstation” and “unreal engine.”
You can actually play with words infinitely by including all kinds of epithets like “beautiful”, “gorgeous”, and “awesome” or technical properties such as “dramatic lighting”, “sharp focus”, “triadic color scheme”, etc.
Watch this video on YouTube to see more examples of how different prompts are visualized.
Adjusting images
To get to the editor interface, you need to push the Show Editor button on the right and scroll to the bottom of the menu to see it.
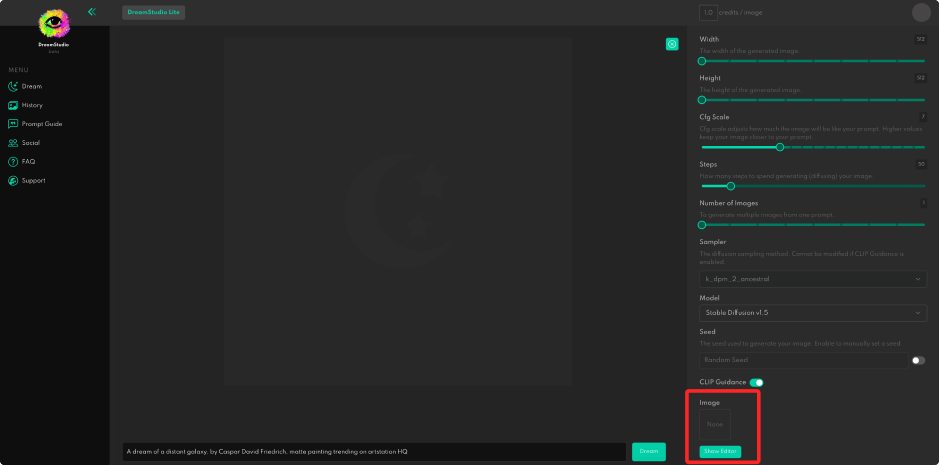
DreamStudio stores all generated images, so you can edit them using the image’s seed number. If you want to recreate some of your recent pictures, go to History, click the “I” button on the image and download it to your PC using the seed number or switch to Editor mode.
Here is a short video explaining how to use seed numbers in more detail.
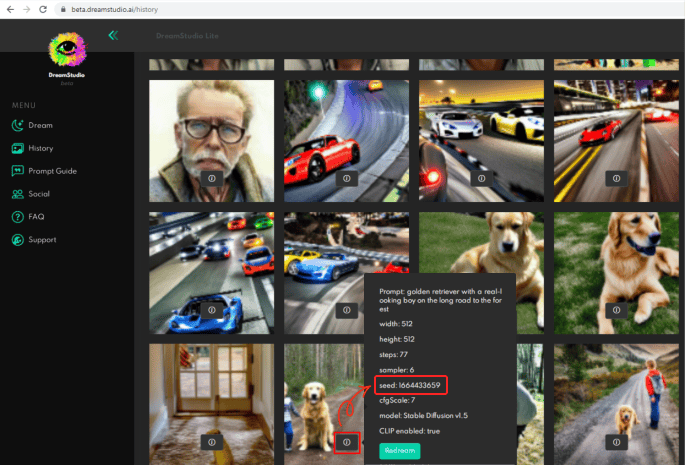
Note the warning from DreamStudio Beta: “These images are stored in your browser only and will be lost when you clear the browser cache.”
You can create similar but slightly different visuals by using the same text prompt. You can find the original wording in History by clicking on the image.
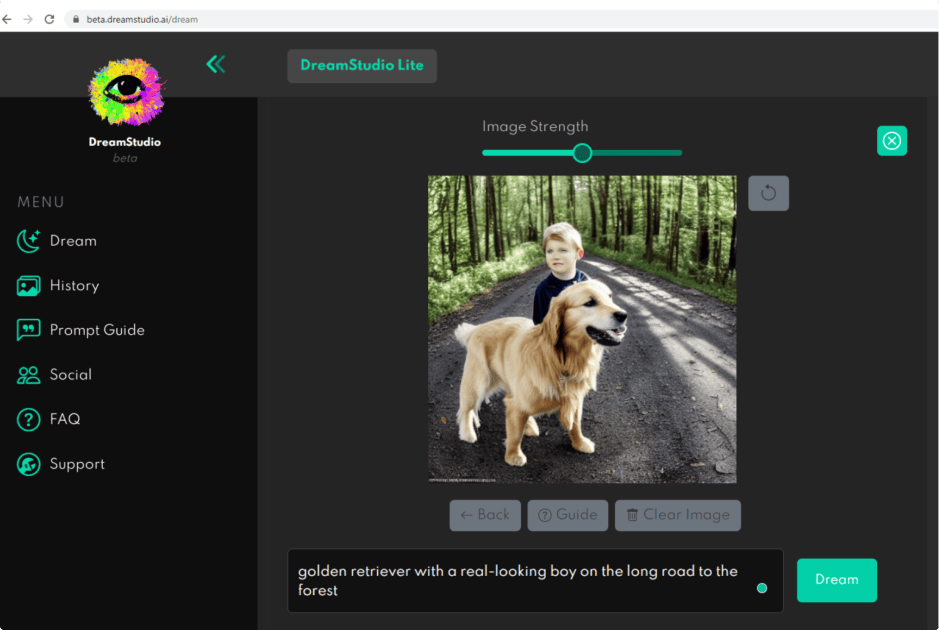
I redesigned the previous seed, and the result is quite satisfactory. However, the boy looks a little strange. I think the picture would be better without him.
This is where the editor mode comes into play. Note that the Editor button in the lower right corner appears only after you have downloaded the image).
I also used the brush tool to clear the area.
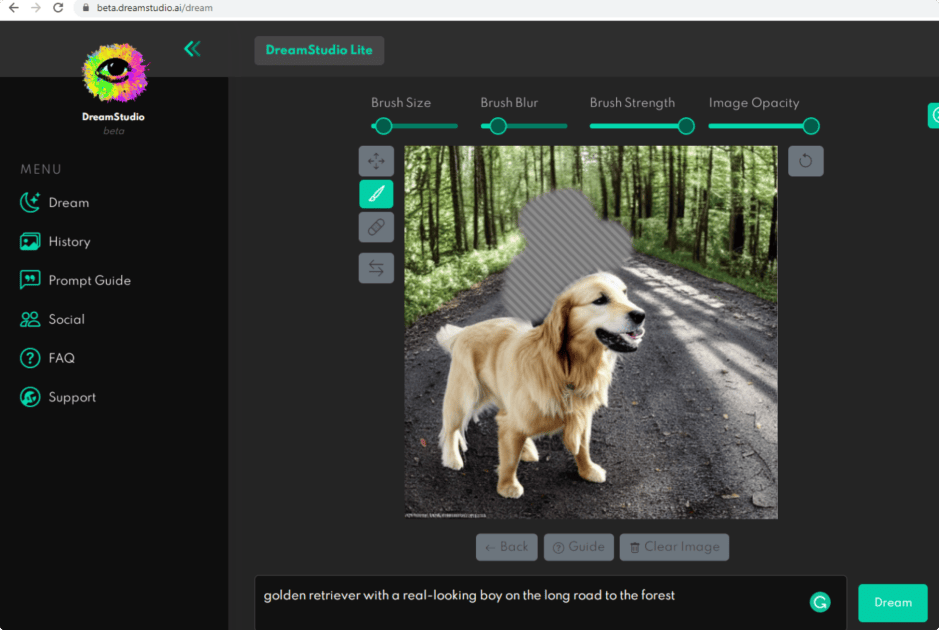
Next, I deleted the words “with the real-looking boy” and clicked Dream again.
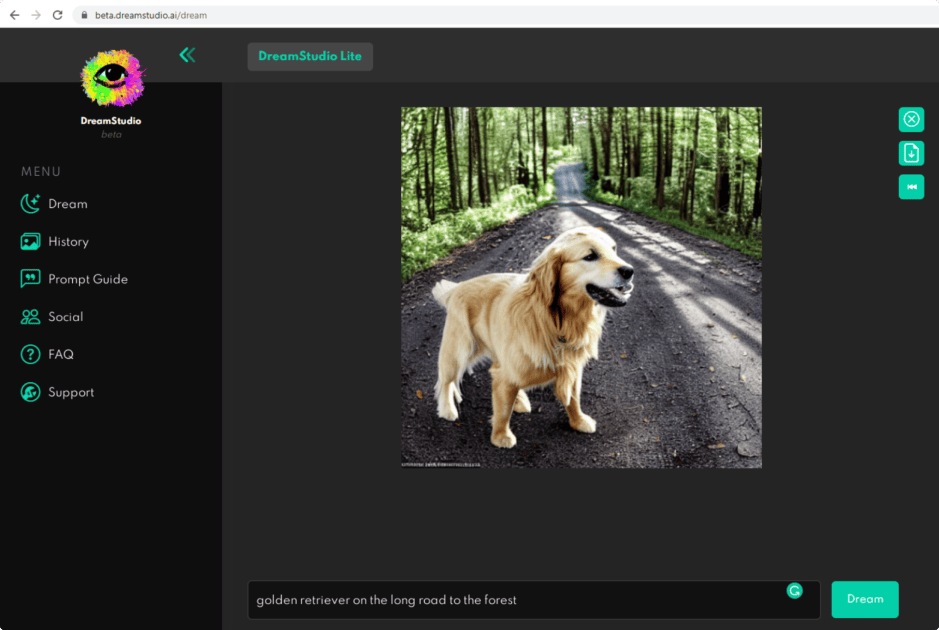
The result looks good to me.
Note: all newly created images are saved in History on the left sidebar.
The video tutorial below gives more tips on how to modify existing pictures. It will help you transform some specific elements without recreating the same image each time.
DreamStudio Beta fees
Although the Stable Diffusion model is open-source, the DreamStudio website is only partially free. First-time users get 200 free credits, and once you use them all, you have to pay a $10 fee per generation. As DreamStudio explains, fees are charged to cover the computing costs required for each generated image. It also points out that its team is working to reduce the price.
Magic explained
We have looked at how to create images with Stable Diffusion. But do you want to know how it works on the technical side?
To understand how Stable Diffusion works, we first need to learn the concept of diffusion models.
Let’s look at the general idea.
Remember how sometimes it’s hard to see the whole picture when you look at it up close, while from a distance it makes sense even though you miss some details?
Roughly speaking, we use the same approach for the deep learning model.
Diffusion models are taught by introducing additional pixels, called “noise,” into the image data. The tiny dots that make up this noise decrease the quality of the image. It is essential that the noise is added in a specific order, regulated by Gaussian distribution. The details of the image gradually disappear until only the noise remains. Then the model learns to undo the noise by gradually de-pixelating and reconstructing the image by synthesizing data.

After training, the model can generate images by applying the mastered denoising technique to randomly sampled noise.
If we select a random number of modification rounds for a given image, we get a slightly different result each time.
The video below explains the math on which diffusion is based:
What is img2img?
Another sampling script included in Stable Diffusion is “img2img”. It inputs a text prompt, a path to an existing image, and a strength value between 0.0 and 1.0 and then outputs a new image based on the original one. The strength value indicates how much noise is added to the input image. A higher value produces images with more variation, but they may not entirely fit the text prompt.
What are the technical requirements for Stable Diffusion?
If you want to experiment on your own computer, Stable Diffusion requires 10 GB of VRAM to generate 512x512 pixel images. Currently the company recommends NVIDIA chips to run the model and promises release optimisations to allow work on AMD, Macbook M1/M2, and other chipsets.
Read this post to learn more about how to run Stable Diffusion on your computer.
Who developed Stable Diffusion?
Stable Diffusion was designed by a London-based startup Stability AI in collaboration with public research university LMU Munich and Runway, a developer of multimodal AI systems.
Stability AI was founded by former hedge fund manager Emad Mostaque. 39-year-old Mostaque was born in Bangladesh and grew up in England. He worked for British hedge funds for 13 years before earning a master’s degree in mathematics and computer science from Oxford University in 2005. According to his LinkedIn page, in 2019 he also co-founded Symmitree with the goal of lowering the cost of technology for people living in poverty. According to Forbes, Stability AI is in talks to raise $100 million from investors. The publication’s sources say investment firm Coatue has shown interest in a $500 million deal.
How was Stable Diffusion trained?
The core dataset was trained on a subset of LAION-5B called LAION-Aesthetics. LAION-5B is an open large-scale dataset for training image-text models. It was developed by the German non-profit Large-scale Artificial Intelligence Open Network (LAION), which has released several large image-text datasets.
While its first dataset LAION-400M, published in August 2021, consisted of 400 million image-caption pairs, its successor LAION-5B, released in March 2022, already includes 5 billion pairs.
LAION-Aesthetics consists of 600 million captioned images that an AI predicted humans would rate at least 5 out of 10 if asked how much they liked them.
What are Stability AI’s goals?
Stability AI says one of its goals is to democratize image generation and make it available to both scientists and the general public.
The press release published on the Stability AI website on August 22, 2022 provides the following details:
- The model is released under a Creative ML OpenRAIL-M license, which allows both non-commercial and commercial use. According to the license terms, the ethical and legal responsibility lies with the user. Any redistribution of the model should be accompanied by the license.
- A default AI-based safety classifier that removes undesirable outputs is included in the model’s software package. Since the model was trained on broad data from the internet, it can reproduce biases of the society or generate controversial content. Stability AI welcomes feedback from the community on possible improvements.
- In the near future, Stability AI will release optimized versions and architectures of Stable Diffusion to improve its performance and minimize potential adverse outcomes.
Stable Diffusion vs. other image generators
The main difference between Stable Diffusion and other image generating models is that it’s a completely free open-source solution to which everyone can contribute. Another definite advantage is that it can run on consumer hardware, unlike DALL-E 2 and Midjourney that are only accessible via cloud services.
Stable Diffusion can create incredibly detailed artwork and has a thorough understanding of contemporary visual illustration. However, it’s not that good at interpreting complex prompts. Stable Diffusion is great for creating complex, creative graphics, but not for simpler items like logos.
The future of image generating models
Being a free, open-source ML model, Stable Diffusion marks a new step in the development of the entire industry of text-to-image generation. Although today many users are only exploring its possibilities, in the future free image generation can change the design and publishing field and bring about new art forms.
Useful links
To dive deeper into the world of Stable Diffusion, check out the links below.
For developers
- Official Stable Diffusion community for developers and creatives
- Development notebook for the Hugging Face diffusers library
- Library of weights, model card and codes
For the general public
- Comparison of AI art generators (article)
- Comparison of images generated by Stable Diffusion and Disco Diffusion (video)
- Stable Diffusion takes over (explanatory video)
Thinking of outsourcing AI development? Serokell is happy to give you a helping hand.






