
This is the second article in our series “LLMs for Business.” In it, we explore how to fine-tune large language models and use them safely so they don’t harm your business.
Read the first blog post “LLMs for Business: How to Run Them.”
Fine-tuning vs. context usage
As you can see on my simplified LLM working schema, the main way to get something done with an LLM is to put information in context. This way, you can just feed your request there, maybe provide some additional information or documents, and that’s it. But there are a few downsides to this:
- Context is not unlimited, so if you have a question regarding a really long document, you cannot put everything there.
- The longer the context, the more costly calculations are.
- The longer the context, the more “distracted” LLM gets. With very long queries, it is more complicated for it to understand what exactly you want it to do.
- According to various experiments, LLMs tend to “forget” things from the beginning of the context the longer it is.
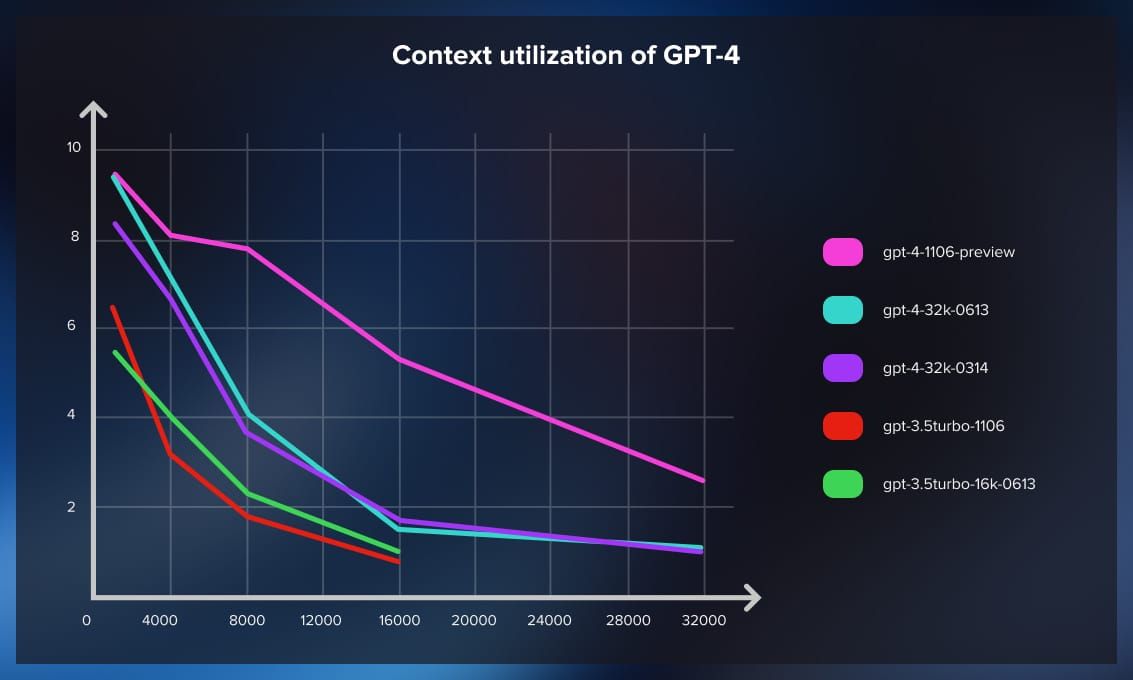
This graph shows fact retrieval accuracy with increasing context length. Essentially, with modern LLMs, you cannot feed more than 8,000 tokens (approximately 6,000 English words, or 12-15 standard text pages) and be reasonably sure that the LLM will not lose any information when generating output. Retrieval results become significantly worse at double the context length. Just to remind you, this graph was produced for quite sophisticated models; most open-source models, especially smaller ones, are much more sensitive to context.
To sum it up, context usage is a way to go if you are not planning to overcomplicate it, i.e. solve direct problems with not that much extra information. For example, you can ask an LLM to reply to an email using specific guidelines, or conduct an automated sentiment analysis. Just be sure not to overfeed the model with too much information in its context, and perform internal benchmarking with your specific data to ensure you get correct results.
If you want to solve more complex tasks, there are several ways to do so. Let’s go through them one by one.
RAG
The main idea behind this method is to reduce the number of things you put into your context to overcome all the cons listed above. This is achieved by simple yet effective strategy:
- Convert information from all documents and instructions you have into vectors (word embeddings). The mechanism is the same as in the LLMs description section, although you usually use separate models for that.
- Put these vectors into the vector database. The main difference from a regular database is that when searching for objects, you filter them by vector similarity with your request vector, not the exact match of the table column.
These steps are performed only once.
Once you’ve got a query for your LLM, you convert it into embeddings and search for the most similar ones in your database. This helps you pick only relevant information from your database and feed it into the LLM context, instead of feeding the entire pool of instructions. Of course, I am leaving out many technical questions on how to properly build such a system out of scope, but let’s focus on the business side of things.
It is most helpful to use RAG when:
- You want to dynamically change the content. For example, you want to expand your database regularly or personalize fragmentary data access for particular users, which can be easily done with a standard database management tool.
- You do NOT want everyone to know about certain parts of the data, as with fine-tuning, it would be exposed to everyone using your LLM.
- You do not want to finetune the model in the first place, as it is quite expensive or it does not solve your particular problem.
- You want to get references to particular documents in your LLMs answers. For example, to validate its output.
While this technique can be effective, we can see that it has a limited accuracy in real life applications. While for some tasks 50-70% requests satisfaction might be good enough, be careful applying it to more sensitive tasks and move on to other techniques described below.
Knowledge maps
On the fundamental level, this technique uses ideas similar to RAG but introduces additional levels of abstraction and expertise required for its setup. As a result, you usually get a much higher accuracy rate for your system than by using pure RAG.
The main idea of this approach is to form a structured knowledge map of the data you have in a way that would be helpful in solving your particular problems. Imagine you are trying to teach a person to solve your task and you need to structure your data in a convenient way for that person to use. That will be a knowledge map. Under the hood it might be a table, a graph, a table of contents, a decision tree, a script with conditions and links to instructions, or anything else. Basically it is data processing which gives your files and folders a lot of extra expert-based context for the LLM to properly juggle around when processing your queries. As you can imagine, it has a much better accuracy than
You want to apply knowledge maps in the following cases:
- The problem you are trying to solve is usually solved via several concrete steps that require expertise, not with a simple semantic search.
- You are planning to query more complicated and domain-specific search requests. To properly answer them, an LLM should not only find where it is stated in your documents database, as it is usually done by RAG, but also to get some domain knowledge from documents related to the request before forming the answer.
- You are ready to invest your domain experts’ time in order to build such a system.
- Basic RAG solution has shown an underwhelming accuracy.
- You want at least 90-95% accuracy in LLMs’ answers without incurring significant additional costs. For example, high accuracy might not be as critical in musical recommendation systems, but it is crucial in judicial applications.
So before building such a system you should understand exactly what you are developing, who will be using this system and what usage scenarios they will have. Starting with these questions will help you make the right decision. We will see more examples at the end.
Fine-tuning
Fine tuning is a time-consuming and quite expensive process. But there are several reasons you might want to perform it:
- You want the LLM to have deeper knowledge about your specific application area and be more focused on it. When the model instance is initially trained it is feeded with all kinds of data, and the more a phenomenon is present in the dataset, the more accurate representation of this phenomenon and its properties will be learned. For example, if you want to ask an LLM a general question about cats, it will easily answer. However,if you ask it about one specific rare species of an animal, it will most likely provide you with either a bland answer, or hallucinate, making up facts. By integrating extra information in your dataset and fine tuning it, you can fix that problem.
- You want the LLM to learn a specific style or to match this style with concrete context. To some extent, you can do so by integrating detailed instructions in the context, but it still works much better with fine-tuning.
- If you want to use smaller models for narrow tasks. In this case, fine-tuning will not be that expensive.
- If your experiments have shown that even with RAG your model hallucinates more than you like. By performing fine-tuning and using this tuned model’s instance in your RAG setup, you will decrease hallucination rate.
As I’ve already mentioned, the main limitation of fine-tuning is that it usually costs too much for smaller tasks. Moreover, it indirectly exposes the data you performed fine-tuning on for everyone using your LLMs instance.
Utilization of various techniques
At this point, we already have a good understanding of capabilities and limitations of modern LLMs and have developed various methods to address them. are proprietary “know-how” for companies, seen in their products as a competitive advantage. For example, they may utilize techniques from traditional information retrieval systems, information theory and other fields. Today, there is no “silver bullet” for every case, so be ready to spend some time adjusting the whole pipeline.
In the first few iterations, your desired product will be working poorly. But once you integrate user feedback in the loop and use it to update both your pipeline structure and prompts you are using, your results will improve steadily. In our experience, this process might converge in 6 to 18 months depending on how much data you have, how many unique user interactions you want, and how much feedback you get.
How not to harm your business with an LLM?
LLMs usage creates extra risks for your business in comparison to more conventional techniques; some of these risks are quite serious and have never existed before. Imagine you have a real estate business, and you’re running a support bot. The main problem here is that LLMs are much more capable of handling complicated dialogs and can engage in out of context conversations, which might lead to:
- Users input out of scope queries such as today’s weather, trip itineraries, the best dinner recipes or even an essay for tomorrow’s literature class. This would put extra load on your system or spend some external APIs tokens. All of this costs you extra money and does not give any benefit in return.
- It can give promises or deals that might be costly for your business, just like in this use case.
- It can misinform, hallucinate, be rude or aggressive to your customer, or provide them with harmful advice.
The list could go on and on. With the classic dialog systems where each request goes through the branching tree of possible responses such outcomes are impossible, but LLMs are opening Pandora’s box in that regard.
Unfortunately there is no 100% reliable way to guardfence this, and even the biggest companies that develop most advanced LLMs are having troubles with that. New ways to jailbreak LLMs and provoke them into inappropriate behavior are being discovered regularly.
There are two main directions you can take to handle this: from a business perspective and from a technical one.
From a business perspective, you should always:
- Incorporate such risks into your business model and estimate the viability of solutions.
- Be sure to include limitations into your legal documents, like “offers from this chat are not final”, etc.
- Think carefully about the most financially and reputationally damaging ways to abuse your LLM-based system and ask LLM developers to give those extra attention and incorporate into specific guardrails.
From a tech perspective, be ready to spend extra development time on:
- Establish semantic similarity thresholds. Basically, you carefully write down a detailed list of all possible scenarios in a single document. Then the user posts their query to evaluate its semantic similarity using a cheap local model (not necessarily an LLM) to decide whether to pass it forward.
- Set clear bot instructions. Next, instruct the bot explicitly to avoid engaging in off-topic discussions. This involves configuring the bot’s prompt to include directives like, “If the question is unrelated to this niche, you should say ‘I’m sorry, this question is off-topic. I cannot answer that.’” Such instructions encourage the bot to consistently decline irrelevant requests, acting as a second filtration layer.
- Leverage real user interactions. Finally, consider the power of real user interactions. By collecting and analyzing data from actual user-bot interactions, you can fine-tune the binary classifier. This classifier is designed to accurately distinguish between on-topic and off-topic queries. This approach not only provides a faster and more precise filtering mechanism but also enhances the overall user experience. And, of course, do not forget to update the previous two points based on these users’ interactions if needed.
This is the bare minimum you want to spend your time on in any case. Of course, it will require extra data collection tools and extra backend logic development, but it will at least give you some layer of protection.
Deployment options: Summing up
Here’s a short memo, cost estimates, and some additional points to consider.
1. Local deployment
- Pros: Complete data privacy, no reliance on external connectivity or services availability, long-term cost efficiency if the load is sufficient.
- Cons: Significant upfront investment in infrastructure and expertise. Reduced accuracy in more complicated tasks compared to advanced models via API.
- Cost estimates: Varies on the particular problem complexity, but usually tens to a few hundreds of thousands USD per problem to set up if you want to do everything properly. Plus, several hundreds USD per month to operate a local machine with a single GPU, which can also add up depending on your scale.
2. API integration
- Pros: Easy to set up and scale, lower initial costs, lower operational costs if you have a small system load, and access to advanced model capabilities.
- Cons: Ongoing operational costs might be higher as it is paid per token not per month, potential privacy concerns.
- Cost estimates: initial setup will be a few thousands to few tens of thousands dollars. Operational costs will be approximately the same or lower if you are not making a lot of requests to LLM. Up to 10-20 times more expensive than a local model with the same throughput capabilities if you have enough requests to reach your local GPU setup limits.
Ideally, you want your engineers to mix these two. You should decide which of your tasks are more important to solve more precisely and which one can make some errors without causing big problems. After that, get more accurate estimates from your AI engineers.
Recent advances
On September 12, 2024, OpenAI released a new LLM-based model called “o1.” This model once again outperforms all others in most benchmarks, especially those related to reasoning, math, and programming. As this model operates under a somewhat new paradigm, we will briefly discuss its mechanisms, pros and cons, and ways to use it.
The main difference from previous models is that, instead of “straight up putting everything out” and just continuing the text in the manner we discussed earlier, it takes some time to think. Rather than writing the output directly, it creates a “thought process” in a way that is natural for LLMs: it writes a few notes, critiques its own generation, and updates the output accordingly, repeating this process several times before providing you with the final output.
This approach comes with some benefits and a lot of drawbacks. The main benefit, of course, is that it can solve much more complicated tasks, especially if these require some extra logic behind them. But in some cases, it might be a bit worse than the original 4o; see this graph.
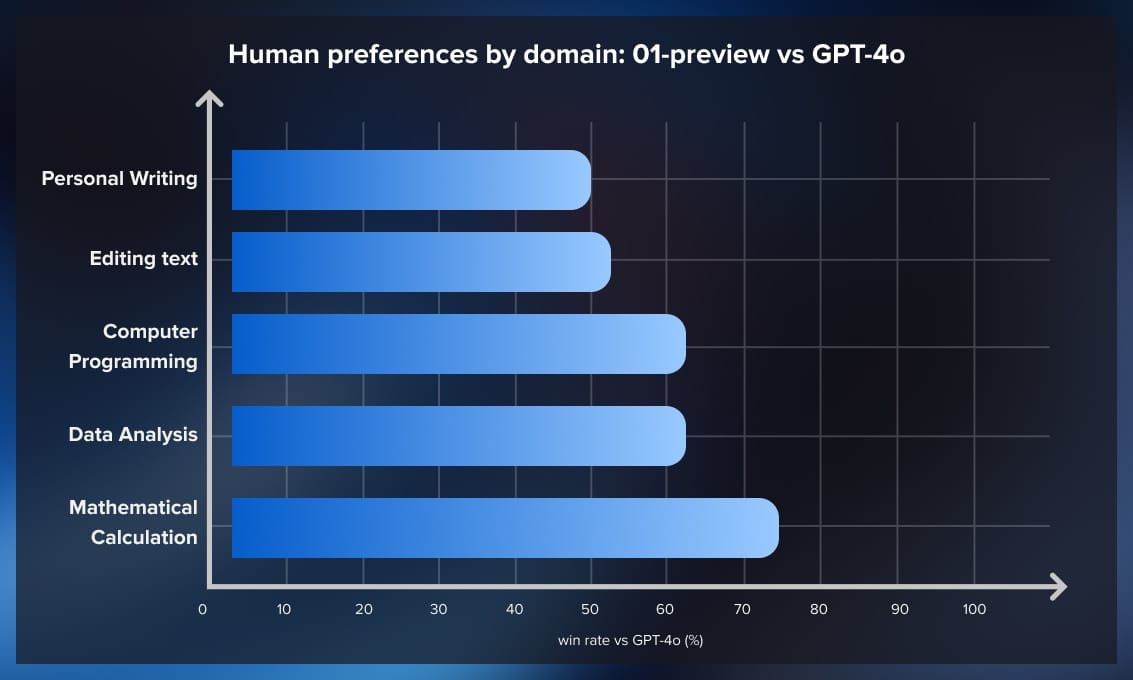
Another overlooked benefit is the reduced need for prompt engineering and related techniques. This model can execute poorly formulated requests and make assumptions about what you mean exactly, which might make integration into your working pipelines easier.
The two main drawbacks of this model stem from its nature: during the thinking process, it is still the same 4o, but it spends a lot of extra tokens to simulate the thinking process. Moreover, you do not have access to these intermediate results. As a result, o1 is almost 50 times more expensive and 20 times slower than 4o, while o1-mini is approximately 7 times more expensive and 9 times slower than 4o.
If these limitations and the other limitations for external APIs we’ve discussed before are acceptable to you, and your internal benchmarking results for the new model are much better, you might consider using it. But if not, you can still use various prompting techniques and rely on simpler or internal models:
- Chain of Thought — ask the LLM to provide output step by step instead of a direct answer.
- Few-shot —include a few examples in your prompt.
- Consistency — ask the same question several times in parallel and select the most common answer.
- Role-play — ask LLM to imagine being in a particular human role related to your task,
- Prompt chaining — split your task into several steps yourself and ask them sequentially based on previous outputs.
- Multi-turn — ask a few questions related to the topic before asking the main question you need to form proper context.
- Curriculum — ask several similar questions with increasing difficulty until you reach the desired response.
These and other techniques can be used both when you are using APIs and on-premise models to improve their results. If you are working with on-premise models, you can take an extra step forward and somewhat imitate the process OpenAI did. You can use outputs from these more complicated requests, in conjunction with your users’ or other LLMs’ feedback, to form extra training data batches and fine-tune your internal LLM on them so it works better next time. This will cost quite a bit of extra money in the initial development stage but will reduce running costs to normal on-premise deployment levels, while narrowing the gap with more sophisticated models like the newest o1.
Compliance
As new models advance in their capabilities, more regulations emerge. You might have heard of various EU data regulations established in the past.
The General Data Protection Regulation (GDPR) is a comprehensive data protection law that came into effect in May 2018 across the European Union. It aims to enhance individuals’ control over their personal data and unify data protection regulations within the EU. Key principles include the requirement for explicit consent for data processing, the right to access personal data, the right to erasure (often referred to as the “right to be forgotten”), and strict guidelines on data handling and security.
Under GDPR, organizations are obligated to ensure the lawful processing of personal data, implement appropriate security measures to protect that data, provide clear information to individuals about their data rights, and facilitate access and erasure requests from data subjects.
The EU’s Data Act is a legislative framework promoting data sharing and access among businesses and public sector entities. It obligates data holders to provide access to their data upon request.
Recently, the EU also introduced an act that regulates AI models and especially influences the development of LLMs.
The European Union’s Artificial Intelligence Act (AI Act) that came into force in August 2024 aims to ensure that AI systems are safe, transparent, and respect fundamental rights. It categorizes AI applications based on risk levels and imposes stricter requirements on high-risk systems, such as those used in critical infrastructure or biometric identification. The act has sparked controversy, with its critics arguing that it may create a cumbersome compliance environment that deters investment and development in the European AI sector.
We are already seeing examples of how these regulations are affecting us today. For instance, Apple had to delay launching three new artificial intelligence features in Europe because of the European Digital Markets Act. The company expressed concern that the Act’s interoperability requirements could force them to compromise their products’ integrity in ways that risk user privacy and data security.
Here’s another example. An undisclosed European legal firm decided to implement AI to automate some of their processes and announced this on their website. However, their competitors submitted an official inquiry requesting detailed information about how they handle client data. The firm claimed that the specifics were a trade secret, but the competitors pointed out that they are legally obligated to provide documentation to ensure they are not violating any laws.
In reality, such matters don’t even require court intervention. Under GDPR Article 15, any individual can request information about how their personal data is being used by a company, which then has 30 days to respond. If the company fails to comply, government authorities can investigate, possibly leading to audits or fines.
Although the USA has not yet implemented regulations on AI at the time of this blog post’s publication, it is clear that such laws will emerge in the near future.
California’s legislature recently passed SB 1047, a bill that could have significantly impacted the development and distribution of AI models. It required companies to publicly disclose how they would test for potential critical harms of AI models costing at least $100 million to train and to outline conditions for a full shutdown before training begins.
These disclosures must also be filed with the California Attorney General (AG). Violations could result in civil penalties of up to 10% of training compute costs, increasing to 30% for repeat offenses. Given California’s influence on national standards, SB 1047 attracted considerable attention. Although Governor Gavin Newsom vetoed the bill, he promised to introduce his own legislation in 2025.
How to start preparing your business for the LLMs-driven future today
We believe that everything will be AI-driven sooner rather than later, so it’s best to start preparing as early as possible. Here are the first essential steps you can already take today.
Analyze
First, analyze your business to pinpoint potential use cases for AI and LLM integration. Some of your processes can be improved with existing tools, while others may be updated in the near future.
Build a roadmap
It’s important to build a roadmap before moving forward. For example, the first steps could involve automating HR, marketing, and customer service tools. They can reduce the workload of these departments by up to 80% with minimal effort.
Collect data
An important aspect to understand is that AI’s capabilities are entirely data-driven. The more data you have, and the better its quality, the higher the performance of your AI solutions will be. The most common challenges medium and large organizations face are information sharding and difficulties merging data. Smaller companies may lack comprehensive processes and have large amounts of uncollected data. To overcome these issues, you need to properly set up your data-related processes. The data you have should be regularly collected, updated, and validated.
Create benchmarks
Another piece of advice is to create your own benchmarks. While there are many benchmarks available online, they can only be used as a starting point for your future LLM integrations. In practice, the actual performance of any model or API depends on the specifics of your datasets. Once your data collection process is in place, you can begin gradually developing your own benchmarks.
Train your staff
Lastly, you need to train your staff. Start by integrating LLM-based tools and chatbots into your employees’ day-to-day workflows. Teach them the basics of data safety, clearly explaining which data can be shared outside the company and which cannot. Once everyone becomes familiar with modern tooling, you can ask them to identify five most impactful areas where these tools could be integrated into their workflows. This will significantly streamline operations and help get around possible future difficulties.
If you still have any questions or challenges about your organization’s shift to an AI-powered future, you can always consult external experts for an audit and support with your plans.
At Serokell, we have a lot of experience in AI and machine learning. Our dedicated team follows best practices and conducts continuous research, which allows us to stay up-to-date with the latest advancements and come up with custom research-based solutions for your specific needs. And we’re just an email away and always happy to help. Contact us here.
Conclusion
While LLMs can be very useful for your business and save you a lot of money and effort, don’t think of them as magical black boxes that can solve everything. They still make a lot of mistakes and cannot be better than everyone in any given situation, at least for now. On the flip side, just think: how accurate is an average employee, and how complicated is their work, especially in less demanding positions? Can an LLM give more accurate answers in such applications? In most cases it can—a 5% error rate is more than appropriate there. Thus, in such applications even some basic LLMs integrations can save you a lot of resources.
Depending on the business and your particular case, even if an LLM will automatically solves 50% of input tasks with 70% accuracy, this might already save you tens of thousands of dollars a month—and with improvements, up to several million easily. Or you can use it for various workflow optimizations that might save several hours a week for each of your employees. Unfortunately, in some cases even 1% of mistakes can be catastrophic, so LLM integrations can be very difficult and expensive, so you must carefully estimate the profit you expect.
We wouldn’t recommend using LLMs for very complicated problems if those cannot be somewhat efficiently solved with existing models at this point. LLMs are developing fast, and you might spend a year or two of development time and investments on things that might be done much more easily in the near future. But you still need to prepare your data and the whole process infrastructure for LLM usage, maybe even try to integrate just to get all processes going, even if LLMs are not showing usable results in your particular cases right now.
While on-premise LLMs might sound a bit adventurous, we still would recommend using this approach if you have at least some user or other stakeholder data. Most of the clients and partners you have will be fine with using their data internally and prohibit you from sending it outside, even if it is anonymized. Almost every company we have seen that bet on on-premise solutions increased their volume in both sales and profits much more than with API-based solutions.
But don’t forget: with the LLM hype opening a new market, a lot of providers are cutting prices in a bid to win over customers. And this is multiplied by technological development. Just a few examples:
- Google reduced prices for Gemini Flash by 80% in August, 2024.
- GPT-4o’s price fell almost in half since its release by the end of summer 2024.
- DeepSeek provided automatic context caching that resulted in up to 10x price reduction in most applications, and tokens are stored for free.
- Anthropic also introduces context caching for Claude and guarantees a 10x price drop from cache, but it is stored for only 5 minutes.
And that’s only in a few months of summer 2024. Just to remind you, the initial version of GPT-4 was almost 12 times more expensive than the current version of GPT-4o. This means that the further we go, the better pricing will be. You can definitely play off it if you do not want to overspend on on-premise development.
Further reading:






