
In earlier posts on our blog, we discussed various types of machine learning, including supervised and unsupervised learning. Today, we continue the series by exploring one of the most versatile and widely used machine learning techniques—hybrid, or semi-supervised learning.
In this article, you will learn about how semi-supervised learning works, what its benefits are, and what algorithms to use.
The definition of semi-supervised learning
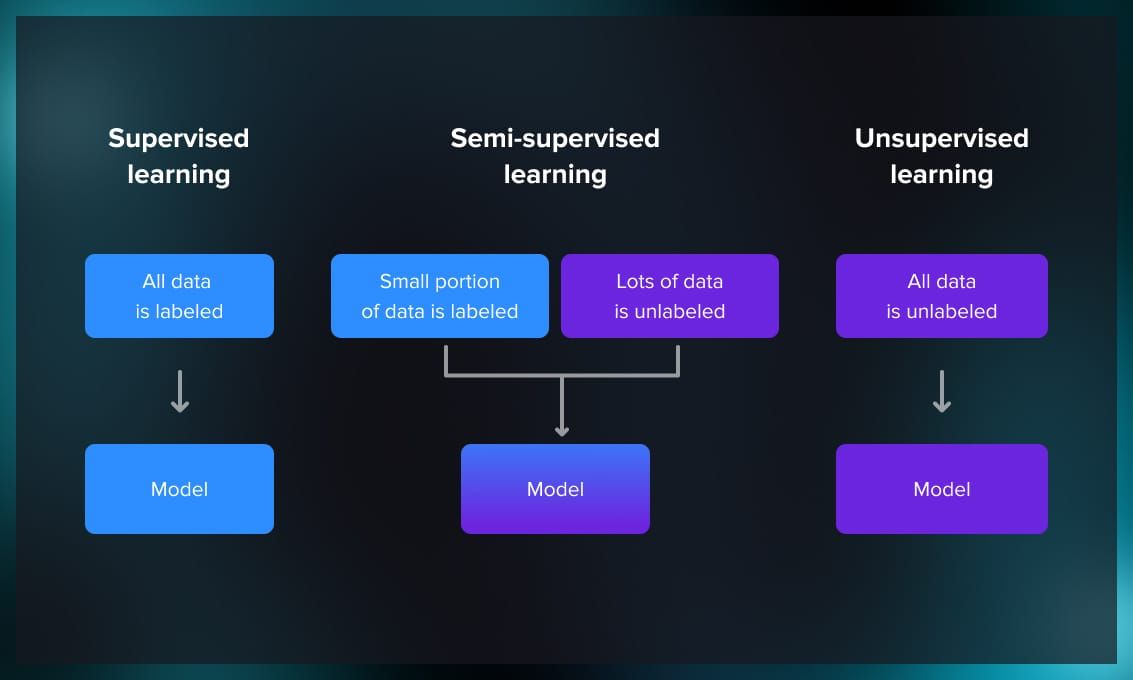
As you might already know from our previous articles about supervised and unsupervised learning, a machine learning model can use labeled or unlabeled data for training. Supervised learning uses labeled data, while unsupervised learning employs unlabeled data.
Labeled data helps achieve maximum accuracy but it isn’t always possible to have a sufficiently large dataset of manually prepared data. Semi-supervised, or hybrid, learning is a machine learning technique that combines the use of labeled and unlabeled data for training to enhance model performance.
Hybrid learning allows us to overcome these challenges and operate in the situations where there is not a lot of labeled data available without compromising on quality.
How does semi-supervised learning work?
Hybrid learning relies on several principles: self-training, co-training, and multiview learning. Each method can be used to train an efficient ML model.
Self-training
In self-training, a model is initially trained on a small labeled dataset. It then predicts labels for the unlabeled data, and confident predictions are added to the labeled set for subsequent training iterations.
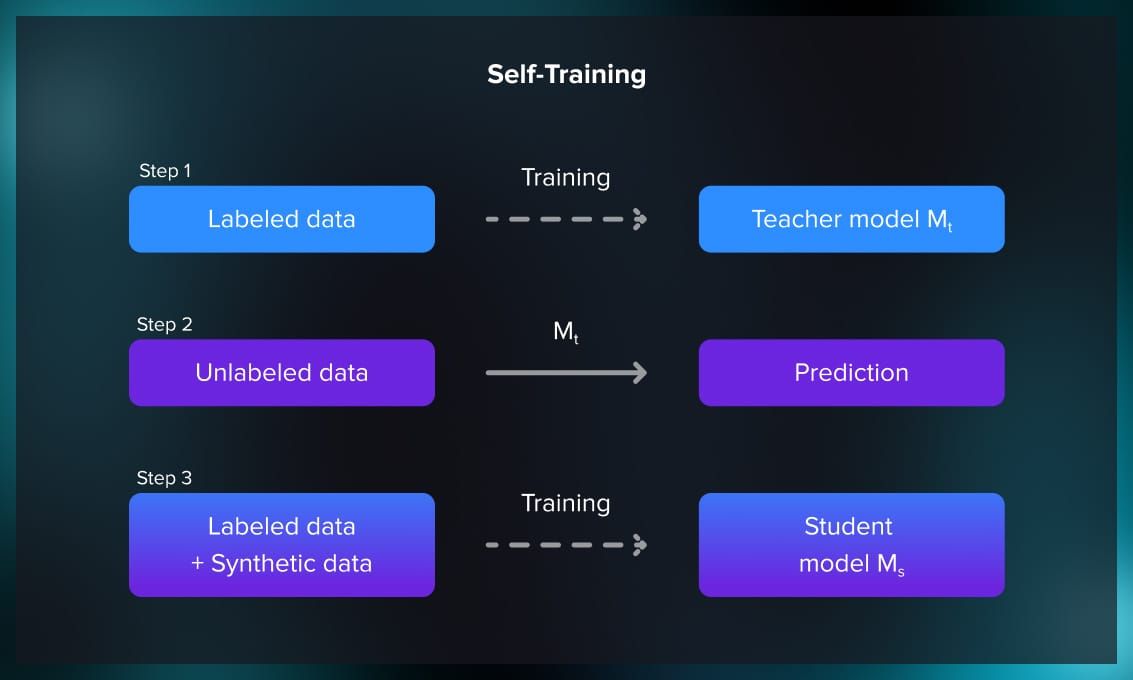
Self-training becomes valuable when there is little labeled data but a lot of unlabeled data. It allows the model to make use of its own predictions on unlabeled instances to expand the labeled dataset.
Moreover, it can be used when labeled data becomes available gradually or in batches. The model can be initially trained on the limited labeled data and then iteratively improve.
For example, in healthcare there is an abundance of unlabeled medical records but it’s hard and expensive to label them, as it usually demands domain knowledge. Self-training can be used to expand the batch.
Co-training
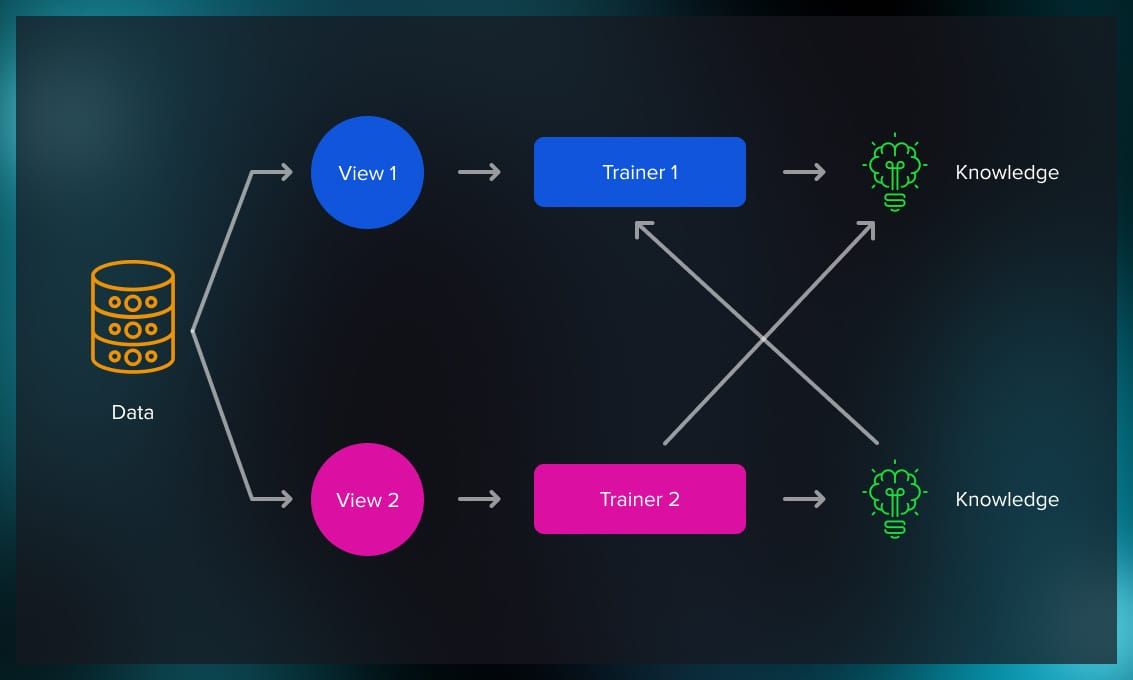
Co-training involves training a model on multiple views of the data. Each view may be associated with a different feature set or representation. The models exchange information during training and leverage the strengths of each other.
Co-training is helpful when the dataset contains redundant or complementary features. By training multiple models on different subsets of features, co-training allows each model to capture unique aspects of the data, improving overall learning.
It’s also effective in tasks that involve learning from different modalities, such as multimedia analysis. Models can be trained on diverse information to enhance performance.
For example, co-training can be used to build self-driving cars, as they have to analyze information from various cameras and sensors to improve their performance.
Note: The main difference between co-training and the next type of learning we will examine, multi-view learning, is that in co-training, you already have a representation of an object’s features, which are divided into groups. In multi-view learning, this representation usually needs to be discovered.
Multi-view learning
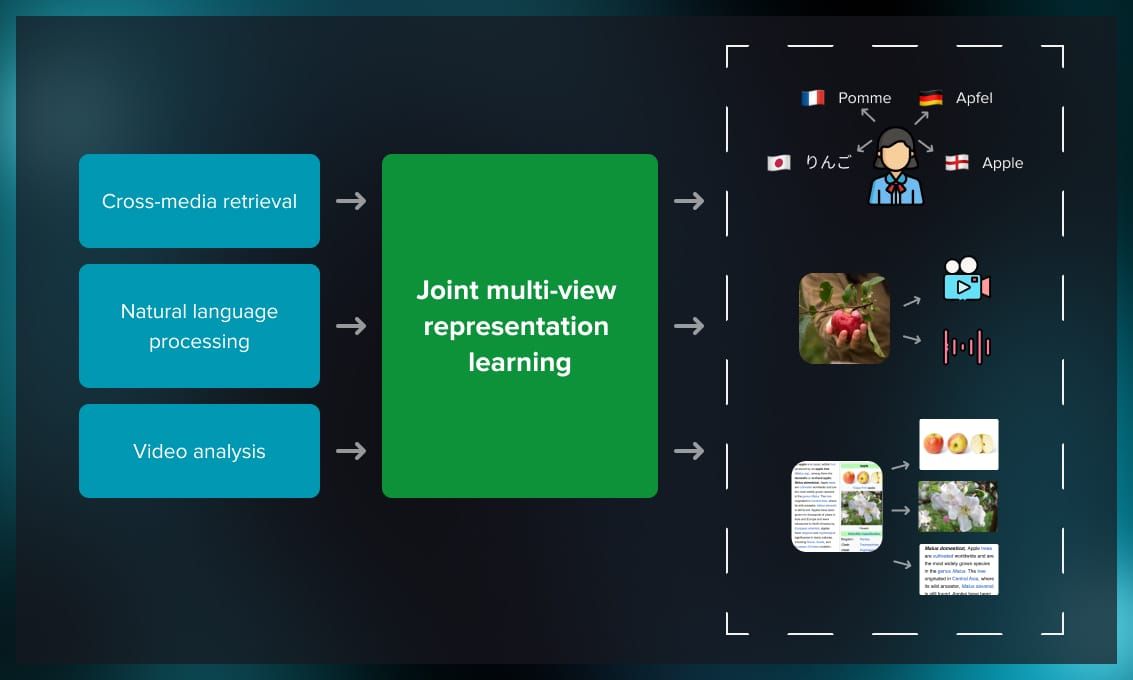
Multi-view learning aims to improve model performance by considering multiple representations of the data. By integrating information from different views, the model gains a more comprehensive understanding of the underlying patterns.
For example, a content recommendation system can use different modalities to label and classify content, including texts, computer vision, and users’ behavior data.
As we mentioned previously, some specific cases of multi-view learning are:
-
Co-training
-
Multi-View Feature Learning
-
Multi-Kernel Learning
-
Ensemble Methods
Assumption in semi-supervised learning
Hybrid learning relies on certain assumptions about the unlabeled data to be able to make predictions.
Cluster assumption
Cluster assumption suggests that points that are close to each other in the input space are likely to share the same label or belong to the same underlying class.
This assumption helps models to see the underlying structure of the data distribution. Semi-supervised learning algorithms exploit this assumption to extend information from labeled to unlabeled data, assuming that neighboring points in the input space have similar labels.
However, it doesn’t always work well. Data with complex structures or overlapping classes may require other methods. Therefore, the success of semi-supervised learning methods often depends on the underlying characteristics of the dataset and the extent to which the cluster assumption aligns with the true data distribution.
Smoothness assumption
Smoothness assumption is based on the idea that the decision boundary between different classes in the input space should be smooth and continuous. That means that in the vicinity of a data point, the true labels of nearby points are likely to be similar.
This assumption is particularly relevant when dealing with semi-supervised learning scenarios where only a small portion of the data is labeled, and the algorithm needs to generalize well to the entire dataset.
Low-density assumption
This assumption is based on the idea that decision boundaries between different classes typically reside in low-density regions of the data distribution.
The low-density assumption suggests that the areas where the density of data points is low are more likely to contain the decision boundaries that separate different classes. Regions with sparse data are more likely to represent transitions between distinct clusters or classes.
Manifold assumption in semi-supervised learning
This assumption is based on the idea that high-dimensional data lying in a lower-dimensional manifold can be effectively represented and learned.
In other words, the relationships and patterns learned from labeled instances can be effectively extended to nearby unlabeled instances. This assumption serves as a guiding principle for algorithms to make use of both labeled and unlabeled data to learn the underlying structure of the data distribution.
Applications of hybrid learning
Semi-supervised learning is used across many fields.
1. Computer vision
Semi-supervised learning has revolutionized the field of computer vision, where labeled datasets for training are often limited and expensive to obtain. In tasks such as image classification, object detection, and segmentation, leveraging both labeled and unlabeled data allows models to generalize more effectively, improving accuracy and robustness.
2. Natural language processing (NLP)
Hybrid learning has proven invaluable for tasks like sentiment analysis, document classification, and language modeling. Pre-training language models on large amounts of unlabeled text data, followed by fine-tuning on smaller labeled datasets, has become a prevalent approach.
3. Medical imaging
Semi-supervised learning is increasingly being applied in medical imaging for tasks such as tumor detection, organ segmentation, and disease classification. With limited labeled medical datasets, incorporating unlabeled data allows models to learn from a broader range of patient cases and enhance their diagnostic capabilities.
4. Anomaly detection
In cybersecurity and fraud detection, semi-supervised learning helps to identify anomalous patterns within large datasets. By training on normal behavior (labeled data) and learning from the vast array of unlabeled data, these models become adept at flagging unusual activities or potential security threats.
5. Speech recognition
Semi-supervised learning also helps improve automatic speech recognition systems. By utilizing both labeled and unlabeled audio data, models can adapt to diverse speaking styles and accents, leading to more accurate and robust speech recognition applications.
6. Autonomous vehicles
The development of self-driving cars relies heavily on accurate perception of the environment. Hybrid learning aids in tasks like object detection, lane segmentation, and scene understanding by allowing models to learn from both annotated and unannotated data.
7. Finance and fraud detection
In financial industries, labeled instances of fraudulent transactions are scarce, so one has to rely on semi-supervised learning to detect fraudulent activities. Models can learn the inherent patterns of normal transactions from unlabeled data, which improves their ability to flag suspicious behavior.
8. Drug discovery
In pharmaceutical research, semi-supervised learning is used for analyzing molecular structures and predicting potential drug candidates. The scarcity of labeled data is addressed by incorporating vast amounts of unlabeled chemical data, which helps with the identification of promising compounds.
Conclusion
Semi-supervised learning is a method that maximizes the use of available resources, addresses the labeling bottleneck, and opens new possibilities for machine learning applications. As researchers continue to innovate and refine techniques in this field, we can expect semi-supervised learning to play an increasingly crucial role in advancing the capabilities of artificial intelligence systems.
Read more:





.jpg)
.jpg)