
In machine learning, there are various techniques for building models. One of them is ensemble learning that uses a combination of models to achieve better performance. By aggregating different predictions, ensemble models can demonstrate better results than their alternatives.
In this blog post, we will talk about how ensemble learning works, review different types of ensemble learning algorithms, and learn about advantages and disadvantages of ensemble learning for various tasks.
This article is part of our series dedicated to types of machine learning.
Read our other articles for more context:
What Is Unsupervised Learning?
What Is Semi-Supervised Learning?
Reinforcement Learning: How It Works
What is ensemble learning?
Ensemble learning is a machine learning paradigm that proposes to use multiple models to create a stronger model. The fundamental idea behind ensemble learning is that a group of models, when working together, can outperform any individual model. It is a lot like teamwork in a corporation: a team of specialists can potentially come up with a more qualified solution than an individual employee.
For example, a popular ensemble learning method is to use decision trees. Rather than rely on predictions of one decision tree, it takes into consideration several decision tree predictions. The trees are involved in a voting process: the outcomes that get the majority of votes win.
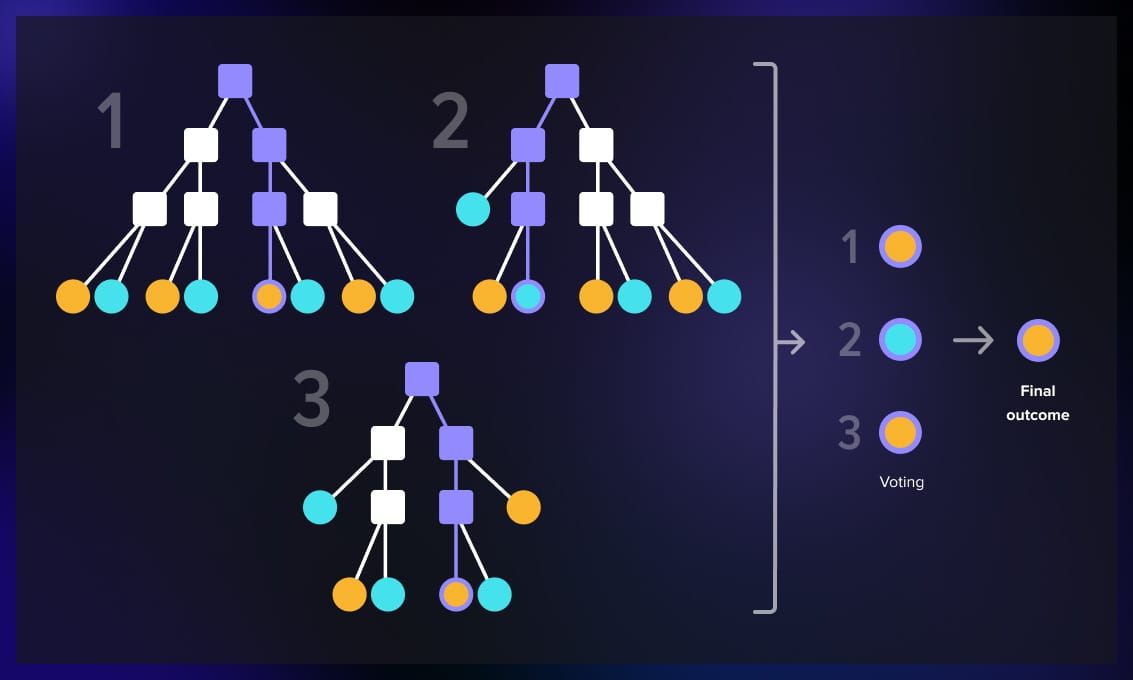
How does it work?
Ensemble learning is an aggregation of different ML models that are used in a cluster to solve a certain problem. For example, several decision trees, neural networks, or a combination of classification and regression algorithms. They are trained on the same data, however, the dataset can also be broken down into smaller datasets, or the training can happen sequentially. At the end, the outputs of the models are aggregated and assessed.
Diversity in models
For ensemble learning to work, you need to use diverse models. If all models in the ensemble are similar, they will probably make similar errors. Different models capture different aspects of the underlying data patterns, and their errors do not coincide. This way, when combined, the strengths of one model can compensate for the weaknesses of another.
For example, for a classification task with a small dataset, you can use several algorithms such as k-nearest neighbors and SVM or several decision trees with different parameters to improve the accuracy of predictions.
Soft and hard voting
Ensemble learning models perform a voting to determine the overall outcome. There are two voting strategies: soft and hard.
- In hard voting, each model in the ensemble makes a prediction, and the final prediction is determined by a majority vote.
- In soft voting, each model in the ensemble provides a probability estimate for each class. The final prediction is then based on the average of these probabilities or values.
Hard voting is usually used to predict class labels. Soft voting can be applied when the base models provide probability estimates or confidence scores.
Ensemble learning techniques
In ensemble learning, there are multiple techniques that can be used for various cases.
Bagging (Bootstrap Aggregating)
Bagging involves training multiple instances of the same learning algorithm on different subsets of the training data.
The dataset is divided into smaller samples, and then each model is exposed to a random sample of the dataset, and predictions are averaged to produce the final output.
Imagine that you have a large dataset that you divide in smaller portions and feed into several similar models at the same time. Each model produces a certain output which is either voted upon for classification tasks or calculated as an average for regression.
To understand how classification works, imagine that you need to put oranges and apples into different baskets.
| Model 1 | Model 2 | Model 3 | Model output | |
| Sample 1 | apple | orange | apple | apple |
| Sample 2 | orange | orange | orange | orange |
| Sample 3 | apple | ? | apple | apple |
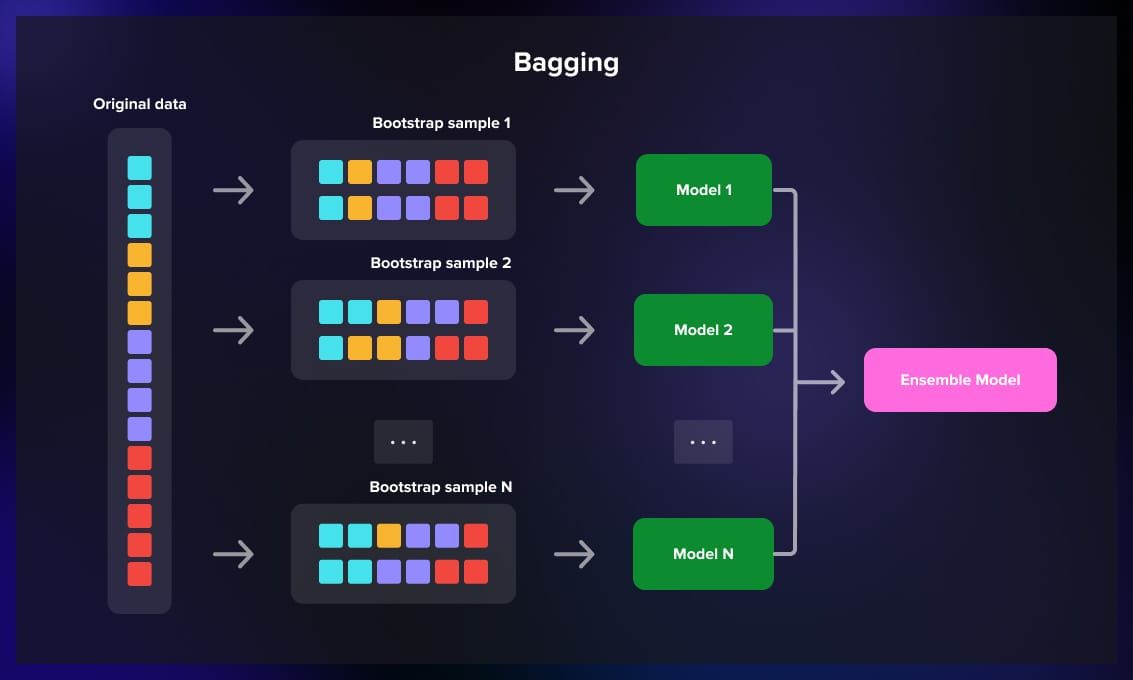
Bagging is helpful when you have a high-variance model and you want to reduce overfitting.
Example tasks:
- Decision tree-based models in high-dimensional data such as random forest for classification or regression.
- Ensemble of neural networks for image classification.
Boosting
Boosting focuses on improving the performance of a weak learner over iterations. Weak learners are models that perform slightly better than random chance.
To improve their performance, ML engineers can use algorithms like AdaBoost and Gradient Boosting, where each model is trained sequentially. A subset of training data is fed into the model during training. The model provides false predictions. The sample is then fed to a different weak learner, and the process is repeated for several more iterations. Then the model outputs the overall prediction based on the previous iterations.
The emphasis is on correcting the errors made during the previous steps. The final prediction is a weighted sum of the individual predictions, where models that perform well are given more weight.
Imagine the same classification task with fruit baskets.
| Model 1 | Model 2 | Model 3 | Model output | |
| Sample 1 | false | true | true | true |
| Sample 1 | false | false | true | true |
| Sample 1 | false | false | true | true |
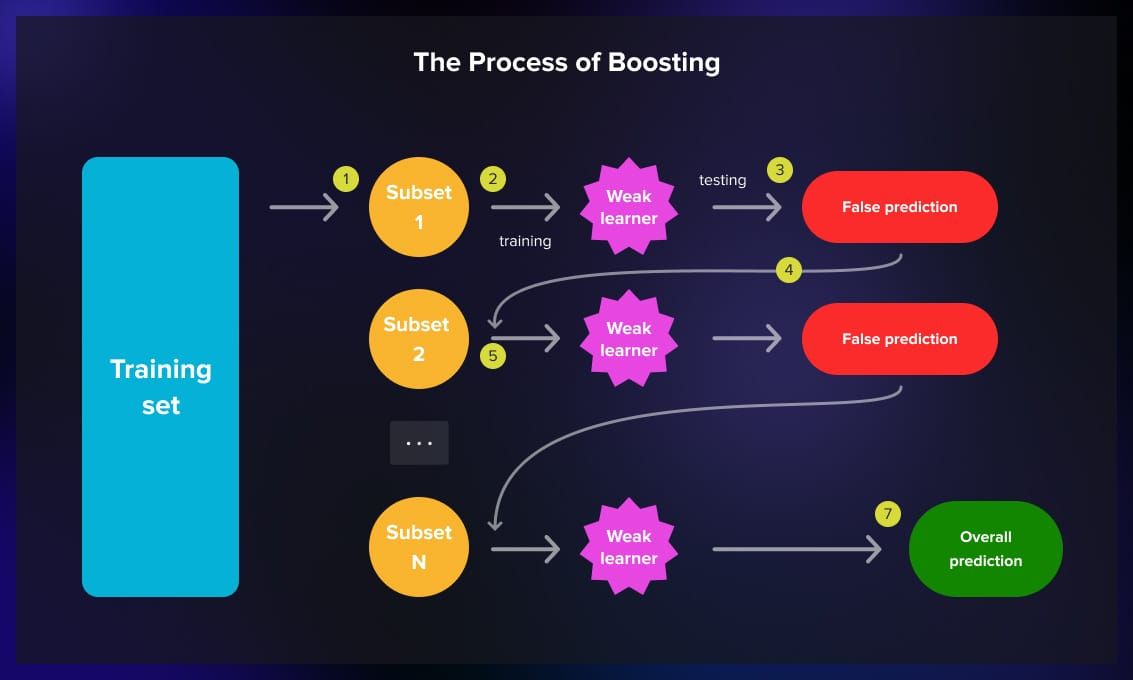
Boosting is used when you have a weak base model and you want to convert it into a strong model.
Example tasks:
- Classification problems where the goal is to improve accuracy, such as in fraud detection or spam filtering.
- Regression problems where you want to predict a continuous variable such as predicting house prices.
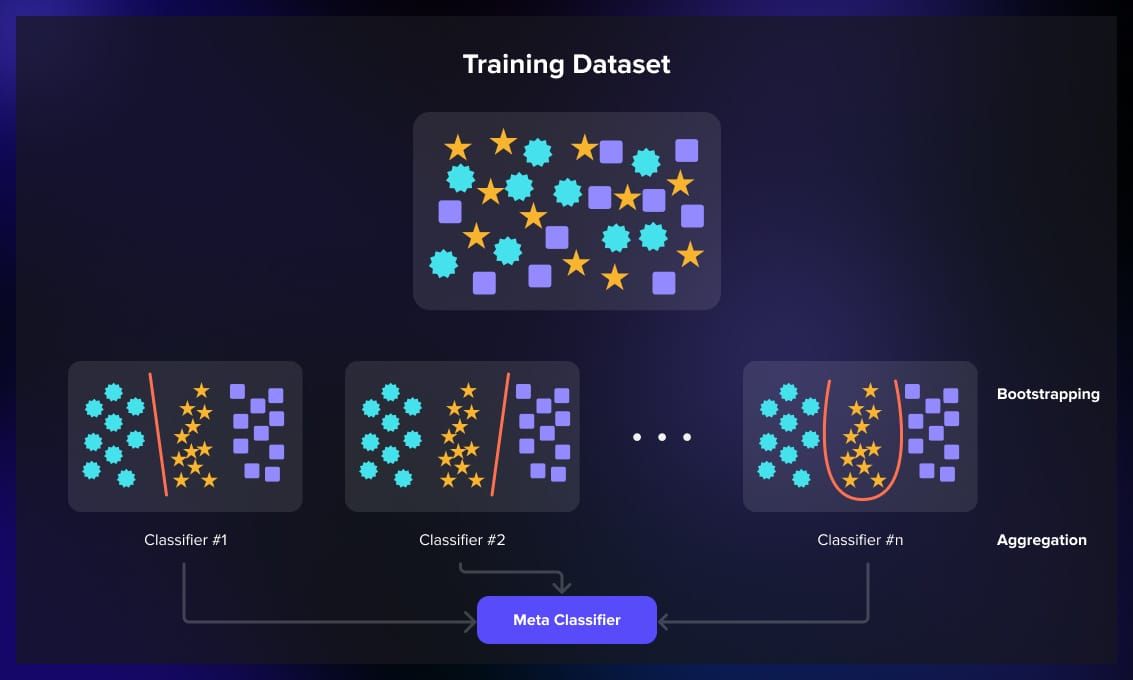
Stacking
Stacking uses a meta-learner, which is another model that takes the outputs of the base models as input.
This method is usually used when different models in the ensemble have different skills and their errors are uncorrelated.
The meta-learner then makes the final prediction based on these combined outputs. Stacking is effective when different base models specialize in capturing different aspects of the underlying data patterns.
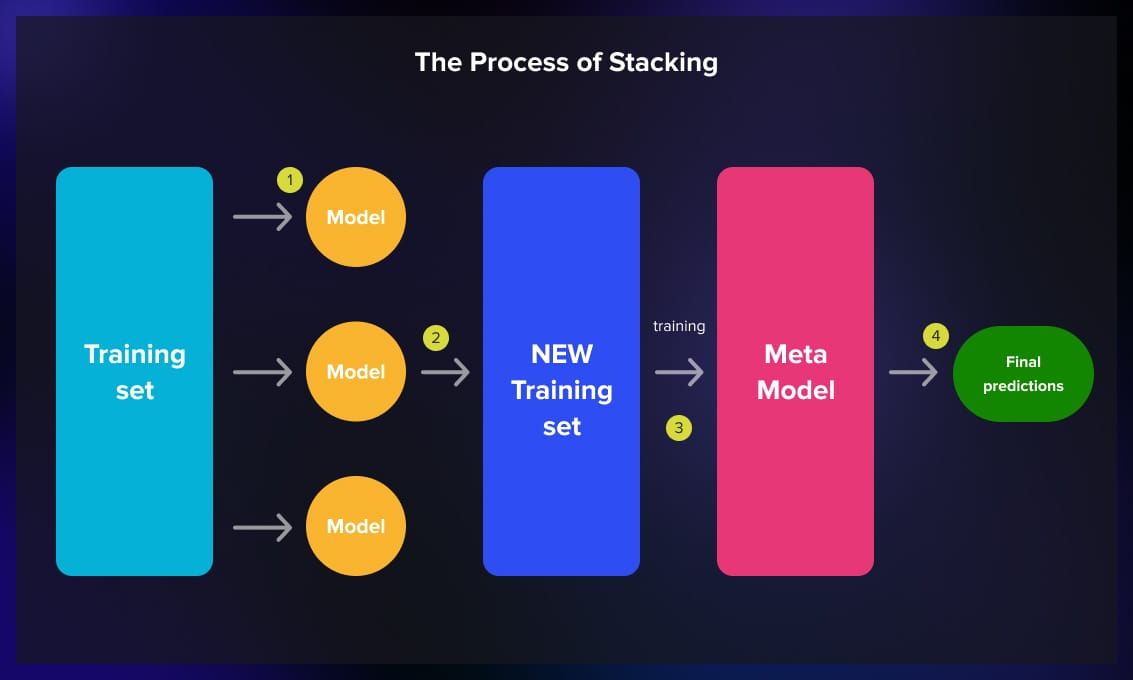
Stacking is used when you want to combine the predictions of multiple models, capture the strengths of individual models and improve overall performance.
Example tasks:
- Any complex problem where different types of models might excel in different aspects such as combining a decision tree model with a neural network for a diverse set of features.
- Multi-modal tasks where different models handle different types of data (text, images, etc.).
Types of ensemble learning algorithms
Ensemble learning is often used for classification and regression tasks. For each task, there are many algorithms to choose from, depending on the type of the problem, the dataset size, and the desired trade-offs between interpretability, speed, and accuracy.
1. Random forest
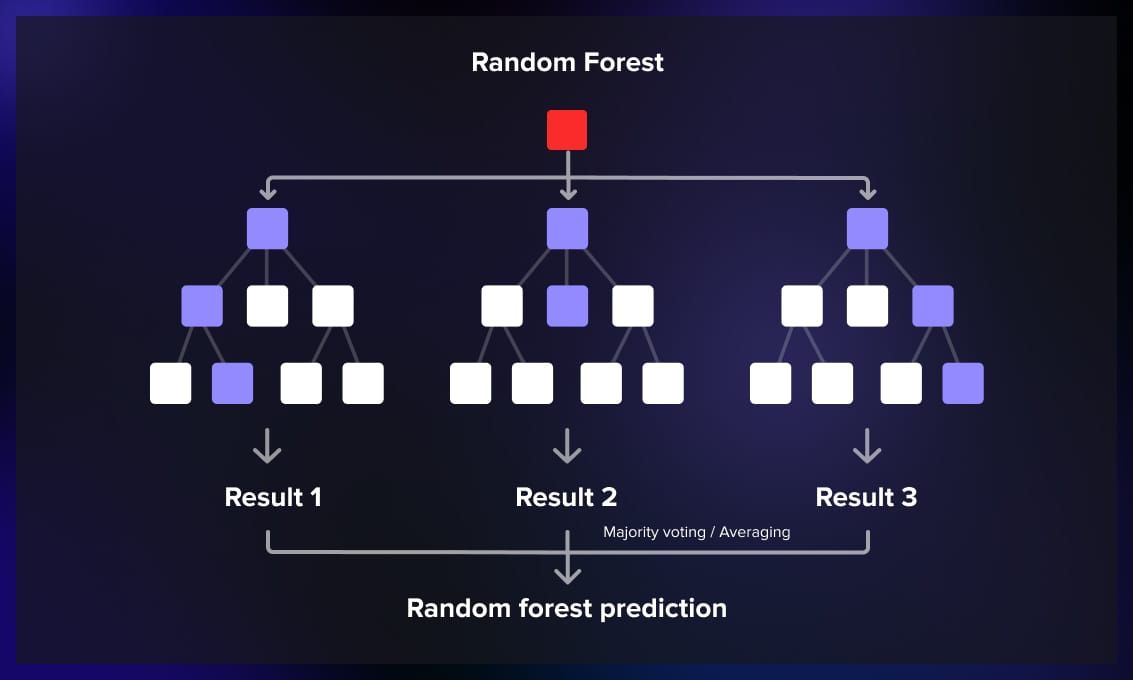
Random forest builds multiple decision trees during training and merges their predictions. Each tree is trained on a random subset of the training data, and the final prediction is determined by a majority vote. It can be used for classification, regression, and other tasks.
2. AdaBoost (Adaptive Boosting)

AdaBoost assigns weights to misclassified instances and focuses on training subsequent models to correct these errors. The final prediction is a weighted sum of the individual model predictions. It is used to solve the problem of weak learners for regression problems.
3. Gradient boosting
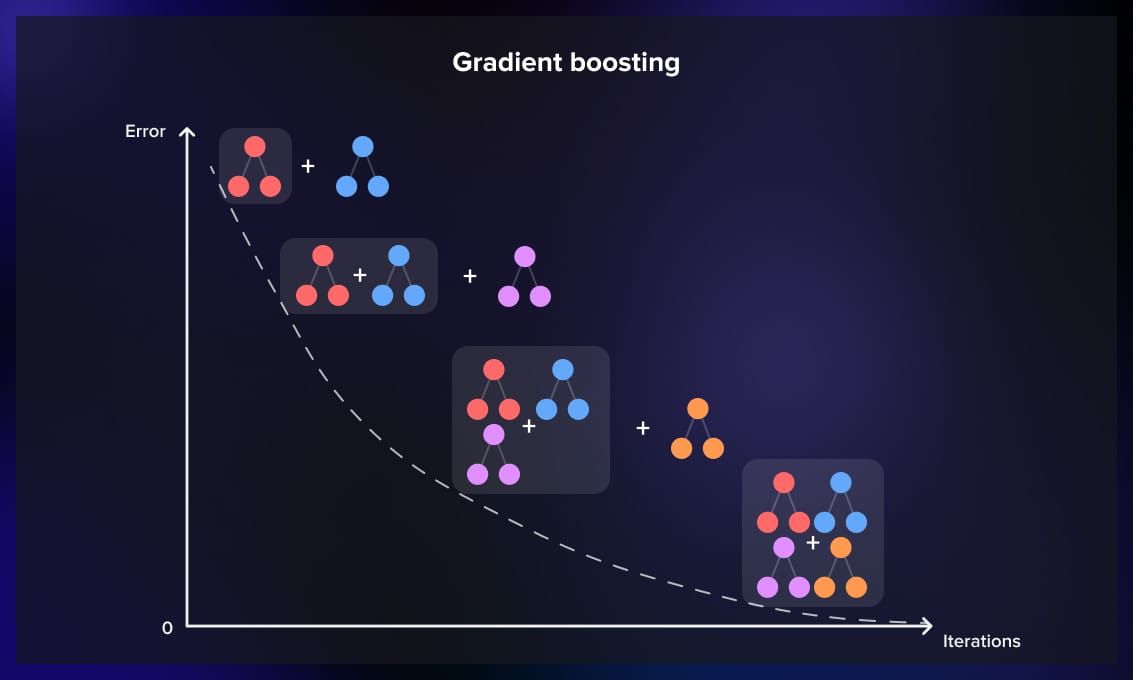
Gradient boosting builds trees sequentially, with each tree correcting the errors of the previous one. It minimizes a loss function, often using gradient descent, to find the optimal weights for each tree.
It’s also often used to solve the problem of weak learners, and is used for both regression and classification tasks.
4. Bagging Meta-Estimator
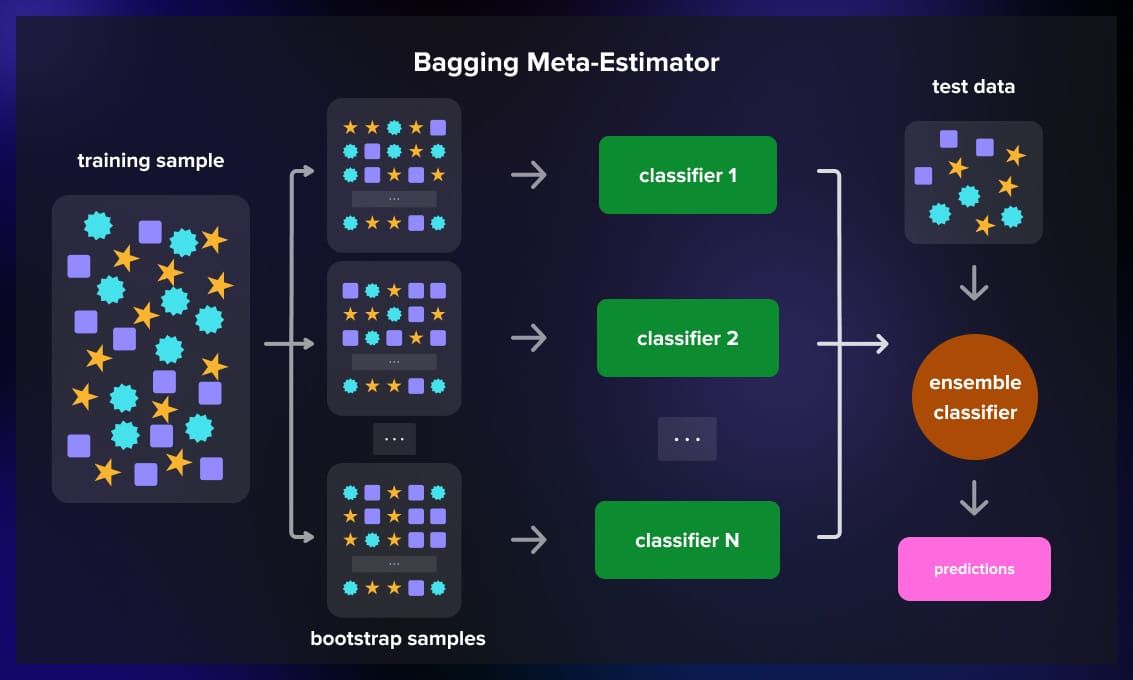
BaggingClassifier and BaggingRegressor provide a general framework for bagging. They can be used with various base classifiers or regressors.
5. VotingClassifier
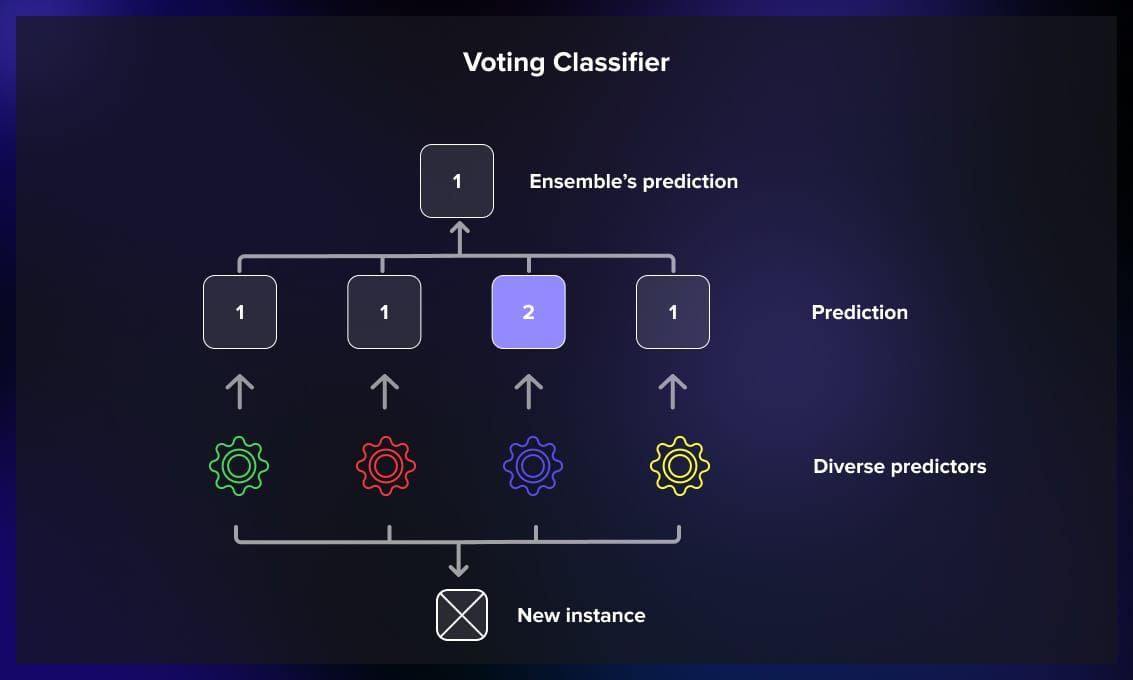
VotingClassifier allows combining multiple classifiers (e.g., SVM, random forest, logistic regression) by majority voting. It supports soft and hard voting strategies.
6. StackingClassifier, StackingRegressor
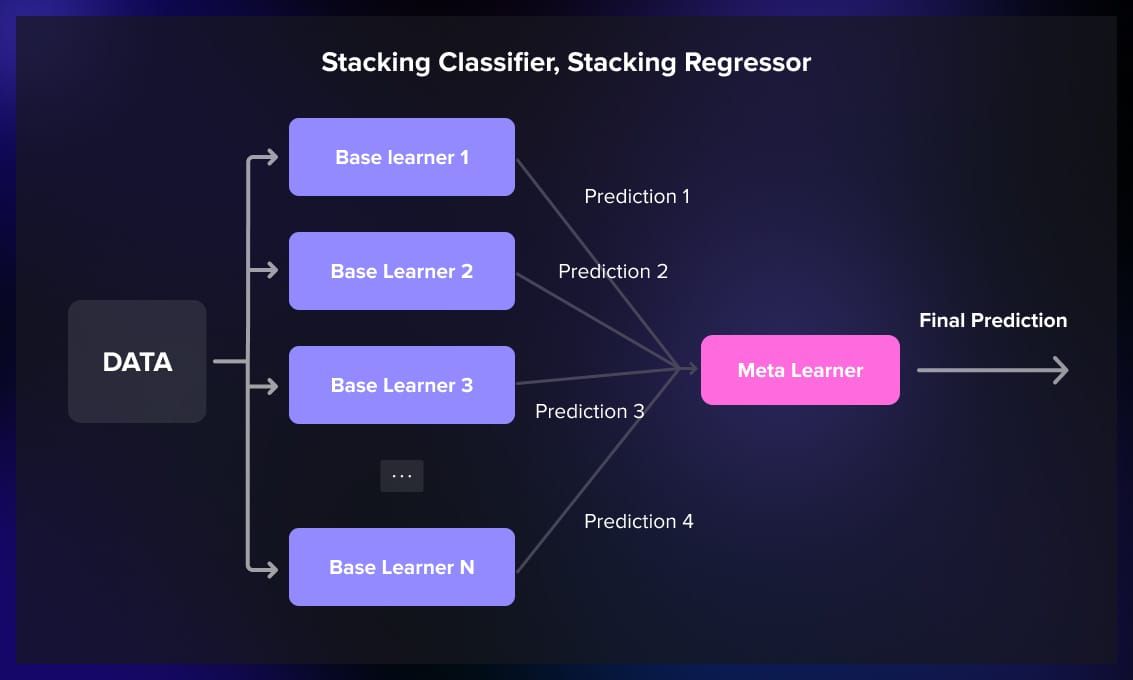
StackingClassifier and StackingRegressor enable stacking with multiple base learners and a meta-learner. They provide a flexible way to experiment with stacking in a scikit-learn compatible interface.
7. Neural networks
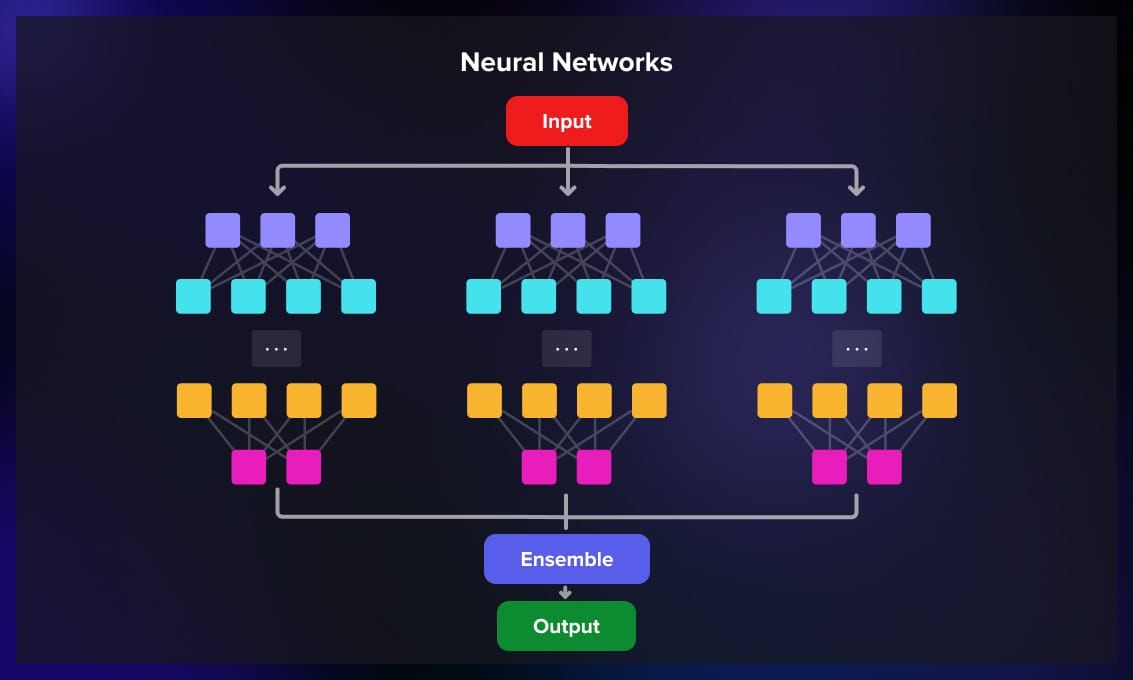
Neural networks can also be used in an ensemble. You can use bagging and train multiple networks independently, and combine their predictions.
Pros and cons of ensemble learning
In this section, we will review the advantages and disadvantages of ensemble learning models.
Advantages of ensemble learning
Ensemble learning offers several advantages that contribute to its popularity in the machine learning community.
1. Increased accuracy
Ensemble learning can enhance predictive accuracy. By combining the strengths of multiple models, ensemble methods can often outperform individual models.
2. Improved robustness
Ensemble learning tends to be more robust to outliers and noisy data. Outliers that significantly affect one model’s performance might have less influence on the overall ensemble prediction.The diversity among models helps mitigate the impact of individual model errors.
3. Generalization to new data
Ensemble models often generalize well to new and unseen data. The combination of diverse models helps capture complex patterns in the data.
4. Versatility across tasks
Ensemble learning techniques can be applied to various machine learning tasks, including classification, regression, and even unsupervised learning. They are adaptable to different types of models and datasets.
Disadvantages of ensemble learning
However, when using ensemble learning, there are also some disadvantages and trade-offs that engineers have to deal with.
1. Computational complexity
Ensemble methods can be computationally expensive, especially when dealing with a large number of models or complex base learners. Training and maintaining multiple models require more resources.
2. Increased model complexity
The combination of multiple models can result in increased model complexity, making it more challenging to interpret and understand the inner workings of the ensemble.
3. Overfitting risk
Although ensemble methods can reduce overfitting in some cases, there is a risk of overfitting to the training data, especially if the base models are too complex or if there is not enough diversity among them.
4. Dependency on base models
The effectiveness of ensemble learning depends on the quality and diversity of the base models. If the base models are weak or similar, the ensemble might not provide significant improvements.
Conclusion
In conclusion, ensemble learning is a powerful technique, particularly in terms of accuracy, robustness, and generalization. However, be mindful of its potential downsides, including increased computational complexity, model interpretability challenges, and the need for careful consideration when selecting and training base models.
As with any machine learning approach, the choice of whether to use ensemble learning should be guided by the specific characteristics of the problem at hand and the available resources.
If you want to learn more about ML, check out our recent articles:





.jpg)
.jpg)