
Every data scientist knows that one of the most exciting parts of machine learning is picking the right algorithm to crack a problem. But how do you make sure that your chosen algorithm actually delivers the results you’re aiming for?
In this article, we discuss several methods allowing you to measure the performance of your ML model.
What is model evaluation?
In machine learning, model evaluation involves analyzing how well a trained model performs when tested on new data. Various evaluation metrics help assess its performance.
These include accuracy, precision, recall, the F1 score, cross-validation and AUC-ROC. Each one gives you a specific view of the model’s strengths and weaknesses in various situations.
One of the most important metrics is predictive accuracy that tells us how well a model makes correct predictions on data it hasn’t seen before. But evaluating a model goes beyond just accuracy. How the model deals with imbalanced classes, noisy data, or missing information is equally important.
Model evaluation also helps you spot overfitting and underfitting. Overfitting occurs when the model does great on the training data but fails to generalize its predictions to new data. On the other hand, underfitting happens when the model is too simple and doesn’t pick up on relevant patterns in the data.
The choice of metrics depends on whether you’re working with unsupervised or supervised learning, and within supervised learning, whether it’s a regression or classification problem. But the basic idea is simple: a model performs well when its predictions closely match the actual outcomes.
Below, we’ve put together a list of methods for ML model performance evaluation.
Confusion matrix
In machine learning, drawing conclusions based on a single metric can be misleading. For example, a classification model may show 90% accuracy, but the number doesn’t cover performance across different classes. To see the big picture , it’s necessary to use a confusion matrix.
A confusion matrix, sometimes called an error matrix, is a simple way to visualize whether all the classes have been covered, and how well a classification algorithm is performing within each of them. It’s essentially a table that shows how many times the actual class labels match up with the predicted ones from the validation dataset. This makes it easy to evaluate the performance of a model and calculate metrics like precision and recall.
You can use a confusion matrix with any classification algorithm, whether it’s Naïve Bayes, logistic regression, or decision trees. Since they’re so useful in data science and machine learning, some libraries, like scikit-learn and Evidently in Python, have built-in functions that create a confusion matrix automatically.
This grid is a handy way to visualize how well a model is doing across all classes by displaying the number of correct and incorrect predictions for each class side by side.
For a simple binary classifier, the confusion matrix might look like this:
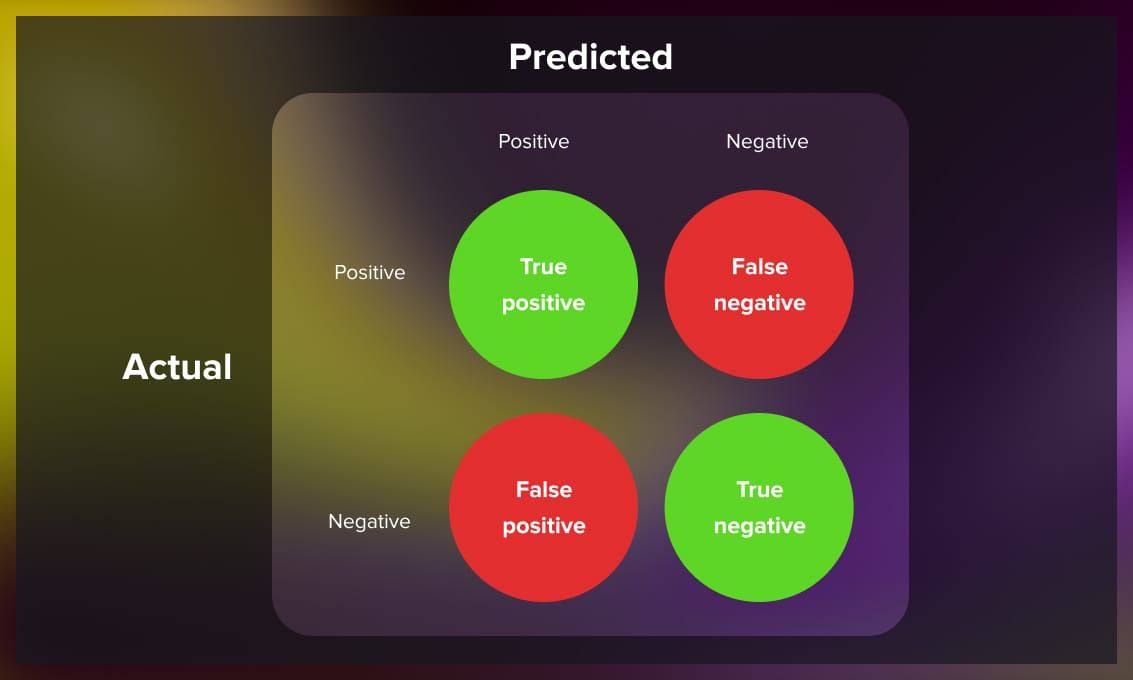
- The top-left corner shows the true positives (TP), which are the correct predictions for the positive class.
- Just below that, the false positives (FP) show where the model mistakenly predicted something as positive when it wasn’t (also called type I errors).
- The top-right corner displays the false negatives (FN), which are actual positive cases that were wrongly predicted as negative.
- Finally, the bottom-right corner shows the true negatives (TN), where the model correctly predicted the negative class.
If you add up all these values, you get the total number of predictions the model made.
This layout works for binary classification, but it also applies to multiclass problems. Say, you’re building a model to classify different dog breeds.
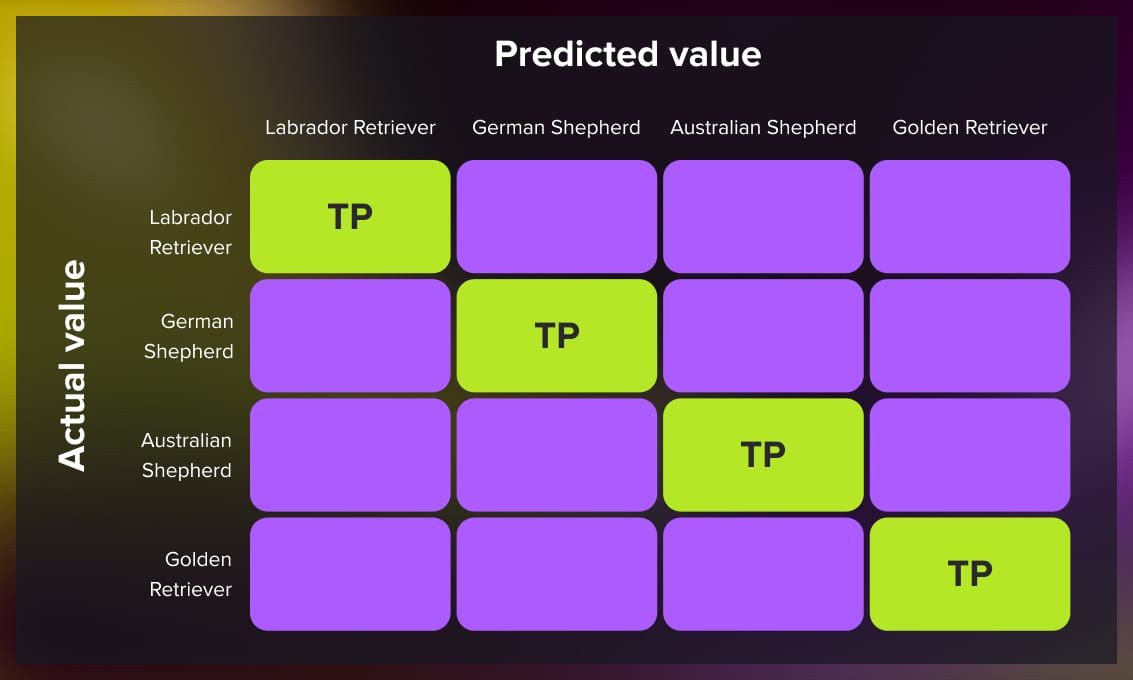
In a multiclass confusion matrix, the diagonal boxes show correct predictions (true positives) for each class, while the other boxes represent incorrect predictions (false positives, false negatives), depending on which class you’re focusing on.
Check out this video for a detailed explanation:
How to use the confusion matrix to evaluate a model
The confusion matrix provides a visual breakdown of a classifier’s performance. Using its figures, you can calculate other important metrics.
Accuracy
Accuracy measures the percentage of correct predictions, but it doesn’t always tell the full story.
Let’s say you run a classifier on a dataset with 100 instances, and the confusion matrix shows just one false negative and no false positives. The model has a 99% accuracy, but that doesn’t necessarily mean it’s performing well in every situation. If your model is designed to identify something critical—like contagious diseases—even 1% of misclassified cases could be disastrous. So accuracy alone isn’t always enough, and other metrics are needed to get a more complete picture.
Precision and recall
Precision tells us how often the model’s positive predictions are actually correct. The positive predictive value (PPV) can be calculated with the following equation.

Recall, or sensitivity, shows how well the model identifies all the true instances of a class, meaning what percentage of actual positives the model successfully picked up. This is also known as the true positive rate (TPR) and can be calculated with this formula:

F1 score
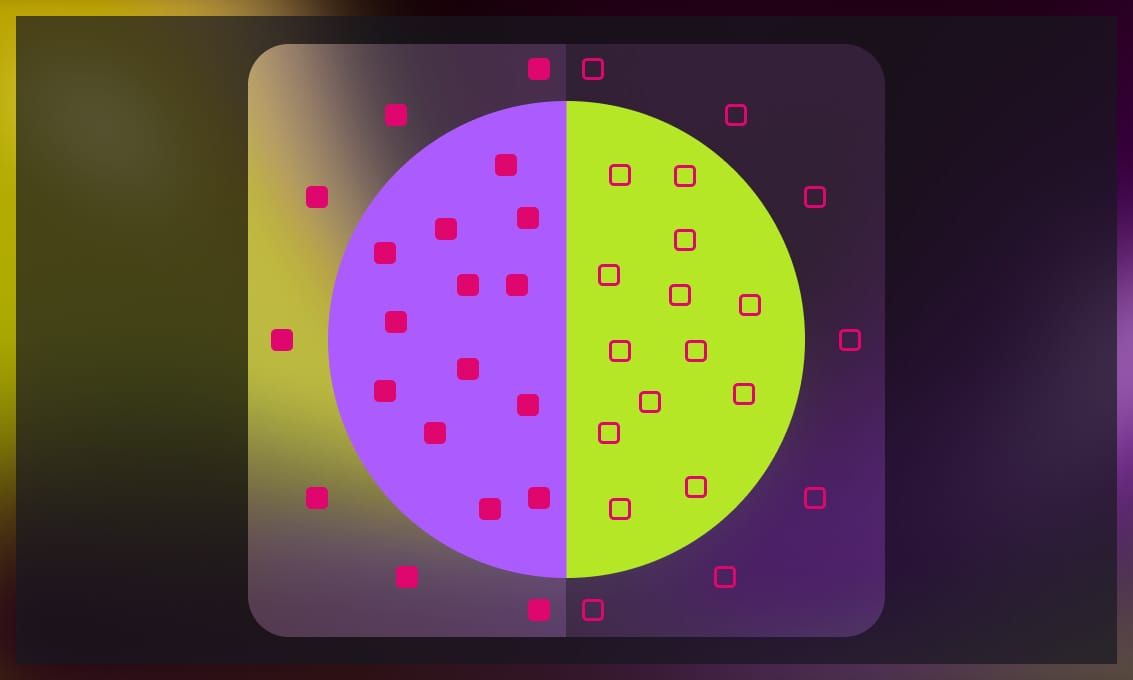
Precision and recall can sometimes work against each other. When a model boosts recall by correctly identifying more true positives, it often misclassifies more false positives, which lowers precision. The F1 score, or F-measure, combines both metrics into one as a harmonic mean. This allows you to have a better picture of a model’s performance.
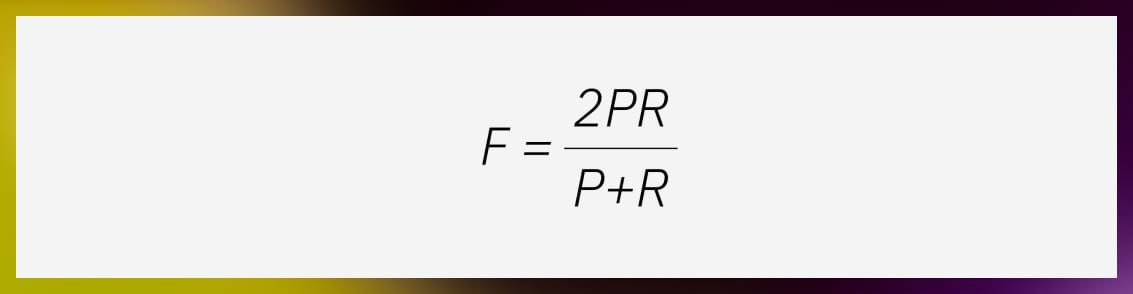
You can calculate the F1 score using precision (P) and recall ®, where P stands for precision (positive predictive value) and R is recall (sensitivity).
The F1 score works best with imbalanced datasets, where the tradeoff between precision and recall becomes more obvious. Imagine a model that predicts fraudulent transactions. If it predicts no transactions as fraudulent, it may have perfect precision but zero recall, because it misses all the actual fraudulent transactions. Conversely, if the model predicts every transaction as fraudulent, it would have perfect recall but zero precision, as it would be flagging many legitimate transactions as fraudulent. This is a classic case where the F1 score is useful for balancing precision and recall, but in fraud detection, precision might be more critical than recall, depending on the cost of false positives versus false negatives.
The F1 score is particularly valuable when both false positives and false negatives are essential in evaluating model performance. Read our post offering a more detailed explanation of F1 score here.
Conditional measures
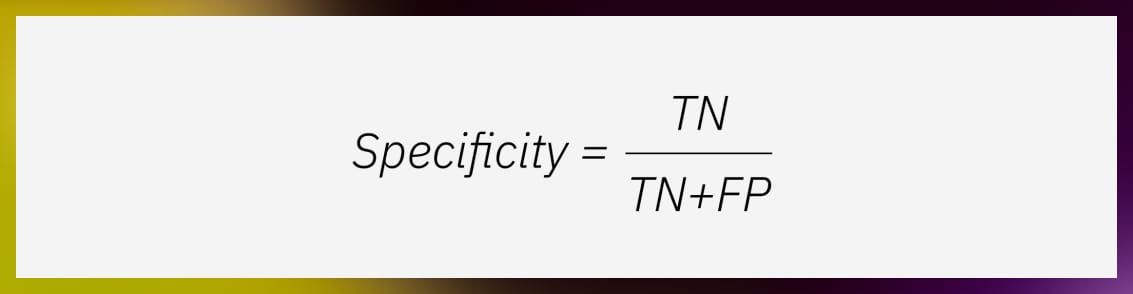
Conditional measures help us understand how well a model is at identifying a specific class or non-class. Recall tells us how many of the actual positive cases were correctly predicted. On the flip side, specificity, or the true negative rate (TNR), measures how accurately the model identifies negative cases. It’s the proportion of correct negative predictions out of all actual negative instances. You can calculate specificity with this formula:
False positive rate
Specificity also helps calculate a model’s false positive rate (FPR), which is often used in visualizations like ROC curves and AUC.
The FPR tells us how likely a model is to incorrectly classify something as part of a class when it actually isn’t. In other words, it shows how often a model produces false positives, also known as type I errors in statistics.

On the other hand, type II errors refer to false negatives, where the model incorrectly classifies actual instances of a class as something else. The false negative rate (FNR) represents the chance of this happening. Just like FPR relates to specificity, FNR is linked to sensitivity:

One reason FNR isn’t used as frequently in research is that it relies on knowing the total number of actual instances for a class, which may not always be available.
Unconditional metrics
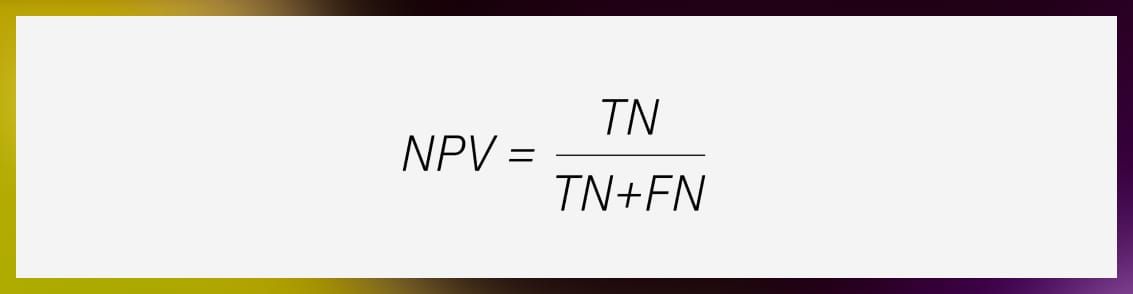
Unconditional metrics indicate the probability of a selected instance belonging to a specific class. One metric is the above-mentioned precision (positive predictive value, or PPV), the other is negative predictive value (NPV). The latter tells you the likelihood of a selected instance not being part of that class. The formula for calculating NPV is:
Cohen’s Kappa Score
The Kappa Coefficient (Cohen’s Kappa Score) is typically applied to binary classifiers using a 2x2 confusion matrix.
Cohen’s Kappa (K) shows how much two raters agree on their classifications, taking into account the chance that some of their agreement could happen randomly. This makes it more reliable than just looking at a simple percentage of agreement. While it’s usually used for two raters, it can be adapted for more. In binary classification models, one rater is the model, and the other is a real-world observer who knows the true class labels. The Kappa score reflects both where the model and observer agree (true positives and negatives) and where they disagree (false positives and negatives). Essentially, it evaluates how much of the agreement is real, not just due to chance.
Cohen’s Kappa can also be applied in situations where multiple people (or raters) are diagnosing, evaluating, or rating behaviors. It’s considered a trustworthy measure of how well raters agree. You can calculate the Kappa score from raw data, where each row is an observation and each column represents a rater’s decision, or from a confusion matrix showing true positives, false positives, true negatives, and false negatives.
Originally intended to measure consistency between data annotations, Cohen’s Kappa is now often used as a quality metric in binary classification tasks. It can also be applied to multi-class classification models.
Unlike other metrics such as sensitivity or specificity, the Kappa score doesn’t directly relate to them and can be sensitive to class imbalances. Also, it doesn’t give you an understanding of specific error types, for example, false positives or false negatives. So you can’t interpret model performance using this score alone, and you should combine it with other metrics.
Matthews Correlation Coefficient
The Matthews Correlation Coefficient (MCC) is a statistical metric that helps you evaluate the performance of binary classification models. MCC gives you a more balanced view than simple accuracy and is especially handy in case of unbalanced datasets.
Here’s the MCC formula:

Where:
- TP = True Positives
- TN = True Negatives
- FP = False Positives
- FN = False Negatives
The MCC will only give a high score if the model performs well across all parts of the confusion matrix (true positives, false positives, true negatives, and false negatives), taking into account both the positive and negative classes in the dataset. It ensures that the prediction quality is balanced for both groups.
Brier score
The Brier score measures the accuracy of probabilistic predictions — how well a model predicts outcomes like win/lose or click/no-click.
To calculate the Brier score, you look at the difference between the predicted probability and the actual result, then square that difference and average it across all predictions.
The formula looks like this:
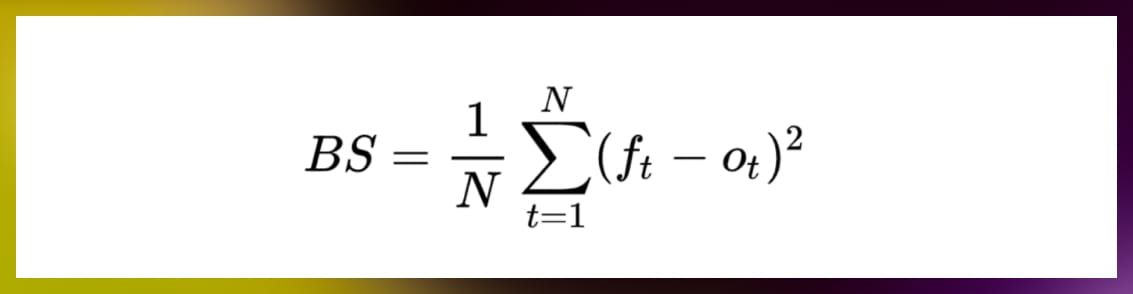
Where:
- f_t is the predicted probability,
- o_t is the actual outcome (what really happened),
- N is the total number of predictions.
The score ranges from 0.0 to 1.0, with 0.0 meaning perfect predictions and 1.0 meaning completely wrong predictions.
If the Brier score is around 0.5, it can be hard to tell if the model is doing well or poorly. In general, the lower the Brier score, the better the model. For example:
- Best case: If you predict a 100% chance of something happening, and it does, the score is 0.0.
- Worst case: If you predict a 100% chance of something happening, and it doesn’t, the score is 1.0.
- Middle case: If you predict a 30% chance and it actually happens, the score is (0.3−1)2=0.49(0.3−1)2=0.49.
Overall, the Brier score tells you how close your predicted probabilities are to reality, with lower scores showing better accuracy.
Cross-validation
One of the key steps in evaluating how well an ML model will perform on new data is ensuring that it can generalize beyond the dataset it was trained on. Cross-validation is especially helpful when you work with a small dataset, as it allows you to make the most of your available data without sacrificing too much for testing.
- K-fold cross-validation: This approach splits the dataset into k equal parts, or “folds.” The model is trained on _k-1 _of those folds and tested on the one left out. This process repeats k times, with each fold getting a turn as the test set. In the end, you average the results for a more reliable performance estimate.
- Hold-out cross-validation: In this method, the data is split into separate sets, typically training and testing (and sometimes validation). The model is trained on one set and tested on the other. It’s straightforward and fast but can be less reliable since the model’s performance can depend on how the data was divided.
- Stratified k-fold cross-validation: Similar to regular k-fold, but here, each fold is made to have the same proportion of different classes as the overall dataset. This is especially useful for imbalanced datasets to make sure the model sees representative samples during training and testing.
- Leave-p-out cross-validation: This method involves leaving p samples out of the dataset for testing while the model is trained on the rest. It repeats for every possible combination of left-out samples. While thorough, it can be very slow since it tests a lot of combinations.
- Leave-one-out cross-validation (LOO-CV): A specific version of leave-p-out where only one data point is left out for testing, and the model is trained on all the others. This process is repeated for every data point. It can be computationally expensive but gives a detailed picture of model performance.
- Monte Carlo (shuffle-split): Here, you randomly split the data into training and test sets several times, shuffling the data each time. The model is trained and tested on these different parts, and the results are averaged. It’s faster than k-fold, but since splits are random, results can vary between runs.
- Time series (rolling cross-validation): For time series data, this method respects the chronological order of the data. It trains the model on an expanding window of time while testing on the next available period. It’s good for evaluating models on sequential data where the past predicts the future.
Cross-validation can also be paired with hyperparameter tuning to further optimize a model’s performance. You can also combine it with a grid or random search to adjust the model’s parameters and find the best configuration without overfitting the training data.
Conclusion
Model evaluation is necessary for enhancing and keeping AI models accurate and up-to-date. It helps you track relevant parameters, detect bias, and check the model’s performance on unseen data. It also helps analyze error sources, optimize hyperparameters, and identify overfitting and data drift at an early stage. In other words, it allows you to make appropriate changes to the data or the algorithms to customize the model to your specific tasks and purposes and maintain its effectiveness.






